

AI资讯



最新发布第12页

中国AI硬件崛起:宇树机器狗挑战波士顿动力
中国AI硬件领域迎来重大突破,宇树科技推出的机器狗产品正逐步挑战波士顿动力的行业领先地位。这一进展不仅展示了中国在机器人技术上的创新能力,还标志着国际机器人市场竞争的新格局。


OpenAI一分为二,营利性公司诞生,奥特曼首获股权分配详情
最新消息,OpenAI正式宣布分成两家公司,其中一家成为营利性企业。在这一重大变革中,奥特曼将成为首位获得营利性股权的关键人物。本文为您揭示更多详情。

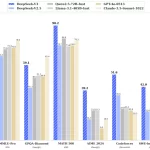
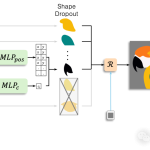
DeepSeek-V3 正式发布:引领行业前沿的技术突破
DeepSeek-V3 正式发布,这是一款集成了最新技术的创新产品,为行业带来前所未有的效率和性能提升。立即了解DeepSeek-V3的详细信息,掌握行业前沿动态。

美国紧急行动:英伟达GPU涉嫌违规流向中国,芯片禁令失效?
最新消息显示,美国政府对英伟达展开调查,质疑其GPU如何规避芯片禁令,将产品非法流入中国市场。本文将详细分析这一事件的背景、影响以及相关法律法规。







友情链接

搜索






