
5月18日消息,谷歌DeepMind昨晚推出AI前沿安全框架,并公布技术报告。

前沿安全框架是一套协议,强调了在AI模型发展过程中识别和缓解潜在风险的重要性,旨在主动识别未来可能造成严重伤害的AI能力,并建立检测和减轻它们的机制。其计划是到2025年初全面实施这一初步框架。该框架侧重于模型级别的强大能力(如特殊机构或复杂的网络能力)所导致的严重风险,对谷歌的一致性研究进行补充。在技术报告中,值得关注的是,保护安全性方面的主要缓解风险措施是保护模型权重,这里的安全似乎更多跟商业秘密相挂钩。
01.三大关键组成:识别危害阈值,定期评估检测,应用缓解措施
今天公布的第一版框架建立在谷歌对前沿模型中关键能力评估的研究基础上,并遵循了负责任的能力扩展这一新兴方法。该框架有3个关键组成部分:
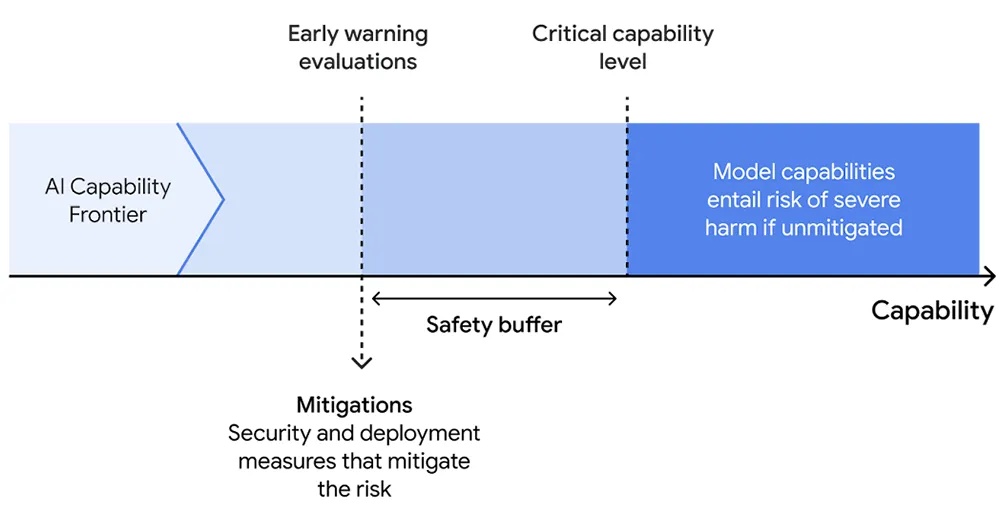
1、识别模型可能具有的严重危害的能力阈值。谷歌DeepMind研究了模型在高风险领域中可能造成严重伤害的路径,然后确定模型在造成这种伤害中必须发挥作用的最小能力水平,被称作“关键能力阈值”(CCLs),它们指导了谷歌DeepMind的评估和缓解方法。2、定期评估前沿模型,以检测它们何时达到这些关键能力阈值。谷歌DeepMind将开发模型评估套件,称为“早期预警评估”,当模型接近CCL时,它将提醒并频繁运行,以便研究人员在达到阈值前注意到。3、当模型达到早期预警评估时,应用缓解计划。这应考虑到利益和风险的总体平衡,以及预期的部署环境。这些缓解措施将主要关注安全性(防止模型泄露)和部署(防止滥用关键能力)。
02.两类缓解措施管理关键能力,4个领域最有可能造成严重风险
前沿安全框架提出了两类缓解措施:一是防止模型权重泄露,二是管理对部署中关键能力的访问并限制其表达。对于每一类缓解措施,谷歌DeepMind都制定了若干级别,使其能够根据所构成的风险调整措施的稳健性。下表描述了可应用于模型权重以防止其泄漏的安全缓解级别。
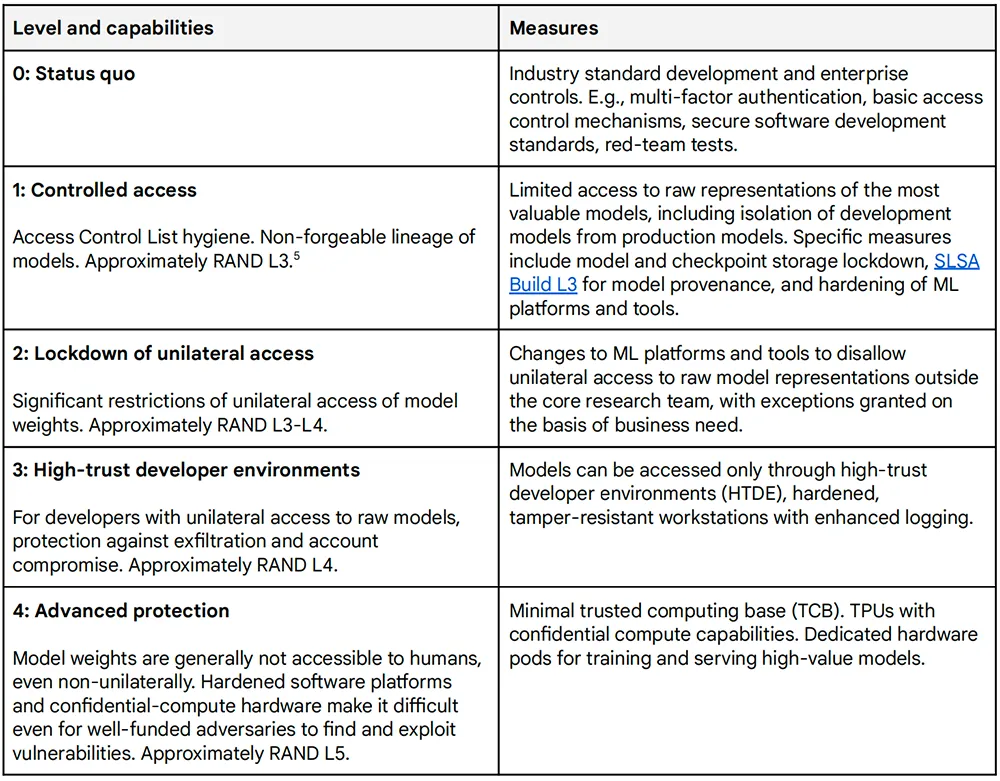
根据技术报告,模型权重的泄露可能允许移除任何训练到模型中或与模型一起部署的保障措施,并因此访问(包括不良参与者)任何关键能力。更高级别的安全缓解可以更好地防止模型权重的泄露,更严格地管理关键能力。但这些措施也可能减慢创新的速度,并降低能力的广泛可及性。下表描述了部署缓解级别,以管理对部署中关键能力的访问并限制其表达。
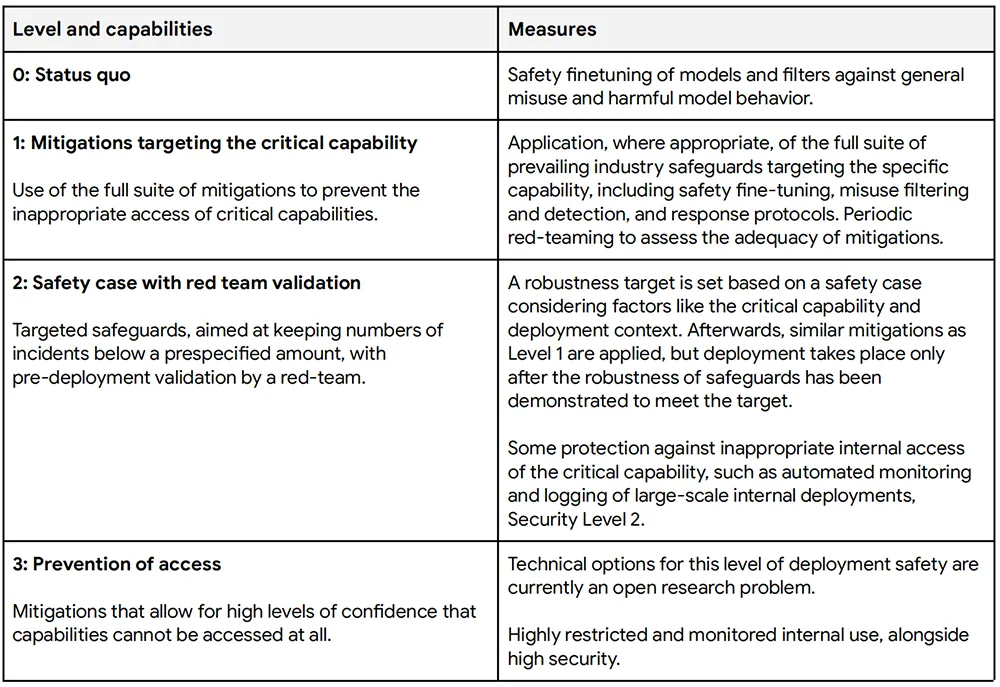
关键能力的滥用可能或多或少难以与有益的使用区分开来,并且滥用的总体风险可能因部署上下文而异。因此,这里列出的缓解选项是说明性的,需针对不同的用例和风险进行调整。谷歌DeepMind最初研究表明,未来基础模型的能力最有可能在这4个领域造成严重的风险:自主、生物安全、网络安全和机器学习研发。在自主性、网络安全和生物安全方面,其主要目标是评估威胁行为者使用具有先进能力的模型进行有害活动并造成严重后果的程度。对于机器学习研发而言,重点在于具有此类能力的模型是否能够使具有其他关键能力的模型得以传播,或者是否能够使AI能力快速且难以管理地升级。其技术报告详细介绍了通过对自主性、生物安全、网络安全和机器学习研发风险领域的初步分析确定的一组初始CCL。
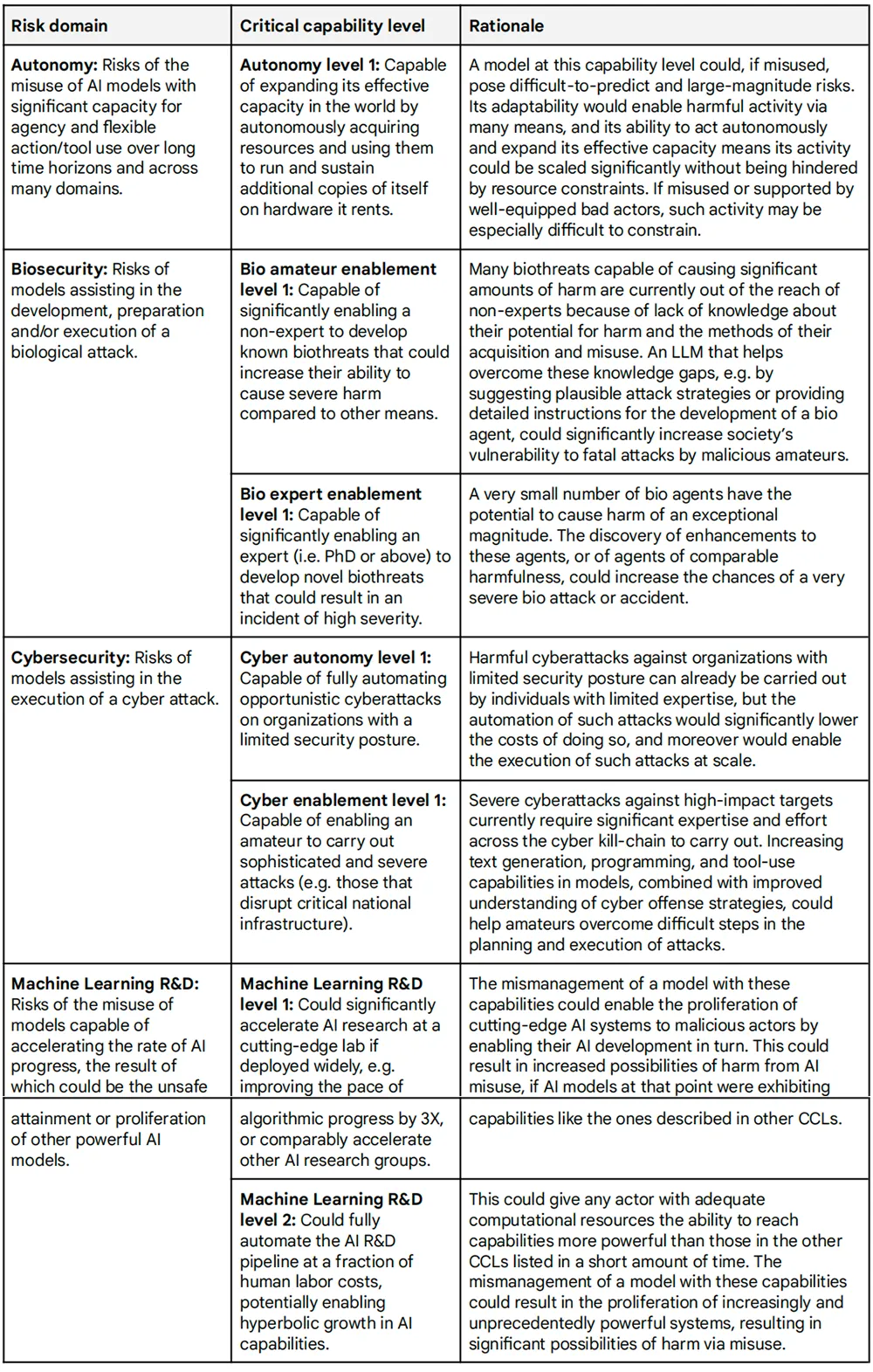
随着进一步研究,谷歌DeepMind预计这些CCL将不断发展,并增加更高级别或其他风险领域的CCL。
03.结语:坚持AI原则,定期审查和改进框架
该框架背后的研究刚刚起步,且进展迅速。谷歌DeepMind在前沿安全团队上投入了大量资金,协调了框架背后的跨职能工作,职责是推进前沿风险评估科学,并根据改进的知识完善其框架。该团队开发了一个评估套件来评估关键能力的风险,特别是强调自主大语言模型agent,并在谷歌最先进的模型上进行了实际测试。他们最近在描述这些评估的论文中还探讨了可能形成未来“早期预警系统”的机制。该系统描述了评估模型在当前无法完成的任务中离成功还有多远的技术方法,还包括一个专家预测团队对未来能力的预测。遵循谷歌AI原则,谷歌DeepMind将定期审查和改进前沿安全框架,逐步加深对风险范畴、CCL和部署上下文的理解,并将继续校准针对CCL的具体缓解措施。谷歌DeepMind希望与产学界和政府多方合作,共同开发和完善该框架,就评估未来几代AI模型安全性的标准和最佳实践达成一致。














暂无评论内容