![图片[1]-LLaMA进化史揭秘:从初代到LLaMA3,全面了解最强开源模型家族](https://www.talksai.cn/wp-content/uploads/2024/05/word-image-8121-1.png)
导语
Meta公司,作为全球科技巨头,在人工智能领域持续展现其前瞻视野与深厚技术底蕴。其开源大模型系列LLaMA(Large Language Model Assistant),自初代发布以来,历经数次迭代,从LLaMA 1到最新的LLaMA 3,不仅在技术参数上实现了跨越式的提升,更通过开放源代码和数据集,深刻地改变了AI研究与应用的格局。本文将详细梳理LLaMA系列从1到3的技术演进历程,剖析其核心技术创新、对开源社区产生的深远影响,以及对全球AI生态的积极贡献。
LLaMA 1:开源之路的起点

Meta于2022年2月首次公开发布了LLaMA 1,这是其进军开源大模型领域的开篇之作。Llama 1基于Transformer架构,旨在推动大型语言模型(LLM)的小型化和平民化研究。Llama 1包括四种参数规模:7B、13B、33B、65B(此处“B”代表十亿,直观反映了模型的复杂性及其对训练数据理解的深入程度。)
与GPT-3最高1750亿的参数规模相比,Llama 1的体积小了10倍以上,但性能优于GPT-3。
尽管在当时的大模型竞争中,LLaMA 1的参数量并不算突出,但Meta凭借其在机器学习领域的深厚积累,精心设计了模型结构与训练流程,使其在有限的参数规模下展现出良好的泛化能力和较低的计算资源需求。
虽然最强大的 LLM 通常只能通过有限的API(如果有的话)访问,但 Meta 在非商业许可下向研究社区发布了 LLaMA 的模型权重。LLaMA 发布一周内,其权重通过BitTorrent在4chan上向公众泄露。
LLaMA 使用Transformer架构,这是自 2018 年以来语言建模的标准架构。
存在细微的架构差异。与 GPT-3 相比,LLaMA
– 使用 SwiGLU激活函数代替 GeLU;- 使用旋转位置嵌入而不是绝对位置嵌入;- 使用均方根层归一化而不是标准层归一化。

LLaMA 的开发人员将精力集中在通过增加训练数据量而不是参数数量来扩展模型性能,他们认为 LLM 的主要成本来自对训练模型的推理,而不是训练过程的计算成本。
LLaMA 1基础模型在包含 1.4 万亿个Token的数据集上进行训练,这些Token来自公开可用的数据源,包括:
– CommonCrawl抓取的网页- 来自GitHub 的开源源代码存储库- 20 种不同语言的维基百科- 古腾堡计划的公共领域书籍- 上传到ArXiv的科学论文的LaTeX源代码- Stack Exchange网站的问题和解答
Llama的开源之举犹如平地惊雷,瞬时在人工智能领域掀起了波澜壮阔的开源浪潮,不仅彻底激活了全球语言模型技术的开放共享进程,更以其深远影响力辐射至世界各地,从科技巨头云集的美国硅谷直至创新活力涌动的中国大地,激发出前所未有的开源创新热潮。
随着Llama开源代码的全面公开,一个围绕其核心技术构建的全球开发者社区如雨后春笋般蓬勃兴起。无论是经验丰富的资深工程师,还是怀揣梦想的编程新手,纷纷涌入这一开源阵营,借助Llama强大的语言模型基础,结合自身专业背景与创新思维,开展了一系列丰富多元的应用开发与技术探索。
短短时间内,基于Llama的开源项目如繁星闪烁,遍布全球各地,涵盖了从基础研究、教育应用、企业级解决方案到个人创意项目等多个层面,展现出开源力量在推动科技进步上的巨大潜力。
在美国,众多科技公司与顶尖研究机构敏锐捕捉到了这一变革机遇,纷纷投入资源,基于Llama开源模型开发出一系列具有行业影响力的产品与服务。
与此同时,中国这片充满活力与创新精神的土地上,Llama开源的影响同样深远。中国的开发者群体以其特有的敏锐度与执行力,迅速响应这一开源潮流,基于Llama构建出众多具有中国特色的开源项目。
LLaMA 2:技术跃升与应用拓展

随着Meta对大模型研究的不断深入,LLaMA系列在2023年7月18日迎来了重要升级——LLaMA 2的发布,这一版本是与微软合作的结果。
Meta 训练并发布了三种模型大小的 LLaMA-2:70亿、130亿 和 700 亿个参数。模型架构与 LLaMA-1 模型基本保持不变,但用于训练基础模型的数据增加了 40%。
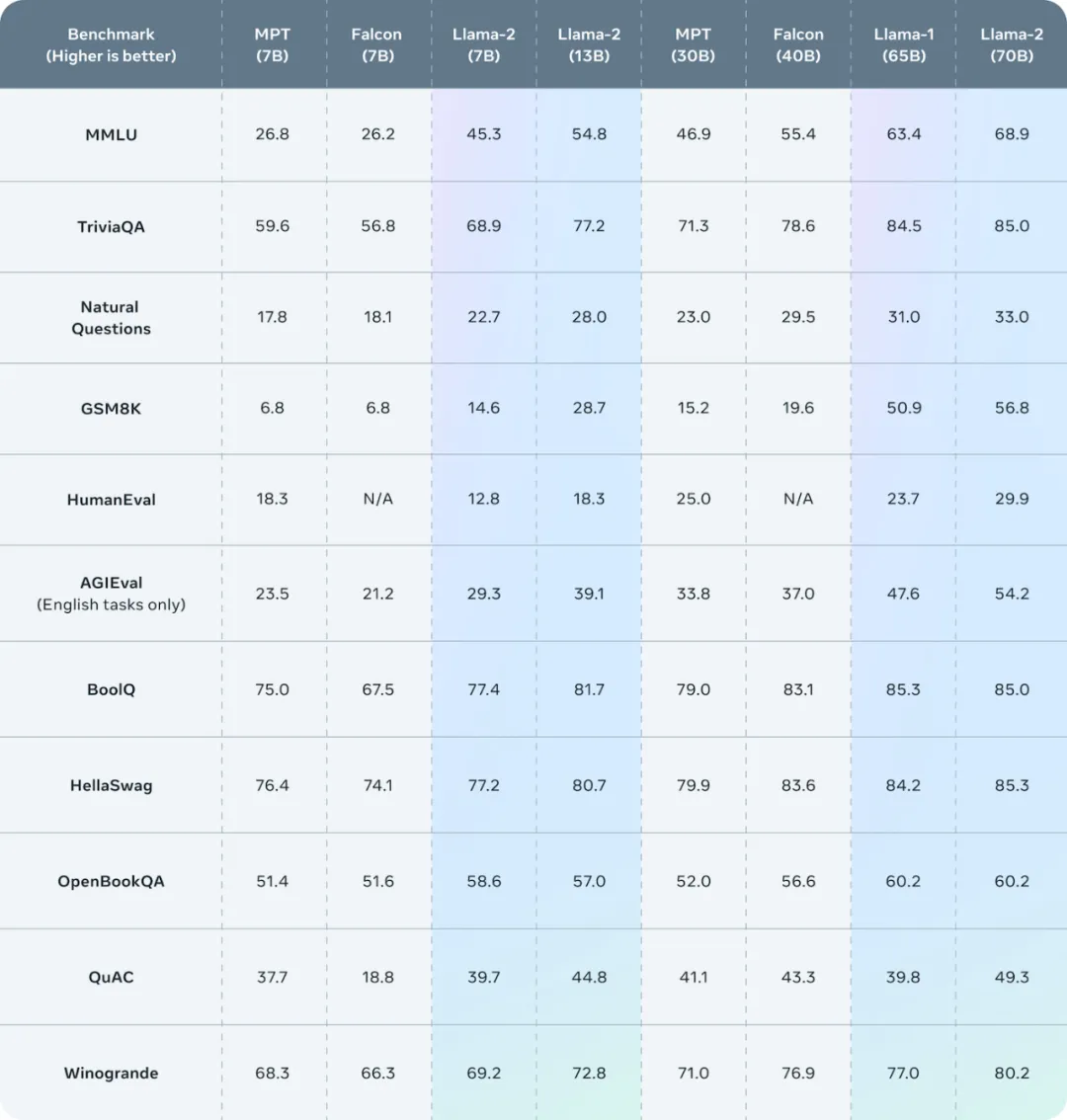
LLaMA-2 包括基础模型和针对对话进行微调的模型,称为 LLaMA-2 Chat。与 LLaMA-1 进一步不同的是,所有模型都附带权重,并且对于许多商业用例都是免费的。
Llama 2的基础模型在规模庞大的数据集上进行了训练,该数据集包含高达2万亿个Token。特别之处在于,数据集的构建过程中,着重去除了那些频繁导致个人数据泄露的网站内容,从而确保了模型在学习过程中避免接触敏感信息。与此同时,对于被公认为权威及可靠的来源,采取了上采样策略,以增加这些优质数据在训练中的权重,确保模型所学更加准确且具有代表性。
Llama 2-Chat分支则在此基础上进行了精细化的微调工作。针对专为此项目精心设计的27,540组提示-响应对,模型进行了针对性训练,其表现明显超越了虽然规模更大但质量相对较逊的第三方数据集。在对AI的对齐过程中,运用了极为丰富的1,418,091个元示例以及另外7个小型但精选的数据集,同时还融入了人类反馈强化学习(Human Feedback Reinforcement Learning, RLHF)技术,以确保模型的行为与人类价值观和社会规范高度契合。
综上所述,Llama 2及其Chat版本在数据利用、微调策略及对齐方法上均体现出严谨的设计理念与高水准的技术实施,旨在打造一个既安全可靠又具备深度对话能力的大规模语言模型。
LLaMA 2的开源进一步激活了开发者社区的创新潜力。基于LLaMA 2构建的应用项目数量激增,覆盖领域更加广泛,形成了一个充满活力的生态系统。同时,LLaMA 2的源代码和数据集被广泛应用于学术研究,推动了AI领域的前沿探索和人才培养。LLaMA 2的成功,巩固了Meta在开源大模型领域的领先地位,也强化了其致力于推动AI民主化、赋能全球开发者的承诺。
LLaMA 3:跨入多模态与超级算力新时代

进入2024年,4月18日,Meta携LLaMA 3震撼亮相,标志着LLaMA系列步入全新的发展阶段。LLaMA 3在技术层面实现了重大突破,其最大版本的参数量飙升至超过4000亿,远超LLaMA 2的700亿,展现了Meta在大规模模型训练上的雄心壮志与技术创新。该模型不仅在单语言任务上表现卓越,更关键的是实现了多模态处理能力,能够同时理解并生成文本、图像、音频等多种类型的数据,开启了跨媒介交互的新纪元。
Llama 3当前发布了两款不同参数规模的模型版本,分别拥有80亿(8B)和700亿(70B)参数量目前,Llama 3仅提供文本形式的回应,但Meta强调相较于前代,这已是“显著进步”。Llama 3在应对提示时展现出更丰富的多样性,减少在不应拒绝回答时的误拒情况,且在推理任务上有了显著提升。此外,Meta宣称Llama 3能更好地理解和执行指令,以及编写更高品质的代码。
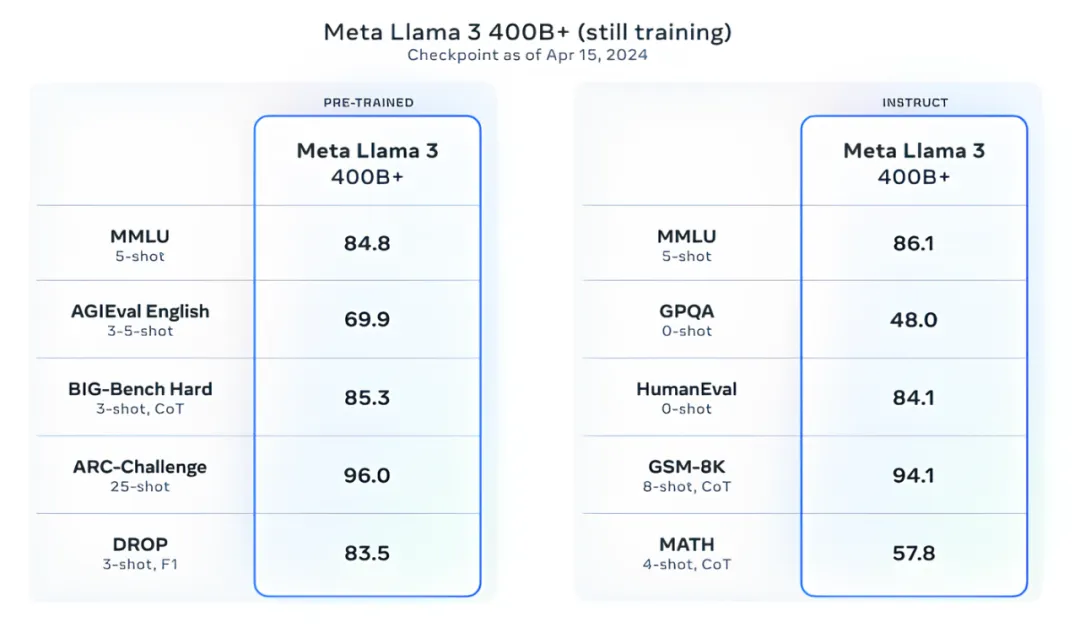
Meta声称Llama 3的两种规格在若干基准测试中力压Google的Gemma、Gemini、Mistral 7B以及Anthropic的Claude 3等同等级别的竞争模型。具体来说,在广泛用于评测常识能力的MMLU基准测试中,Llama 3 8B版显著优于Gemma 7B和Mistral 7B,而Llama 3 70B版则略胜Gemini Pro 1.5一筹。

Meta进一步指出,经过人类评估者的主观评价,Llama 3的整体表现优于包括OpenAI GPT-3.5在内的诸多竞品。为确保评估贴近实际应用场景,Meta特意构建了一个全新的数据集,涵盖咨询建议、头脑风暴、分类、封闭式问答、编程、创意写作、信息提取、角色塑造、开放式问答、推理、文本改写和总结等12项关键任务。参与模型研发的团队并未接触这些评估数据,以保证评价公正,不影响模型原有性能。
除了技术革新,Meta还宣布将在年内建成一个等同于60万个H100 GPU的“超级算力库”,为大规模模型训练提供强大的硬件支持,这无疑将进一步加速LLaMA系列及其他AI项目的研发进程。
LLaMA 3的开源,无疑将掀起新一轮的创新热潮。开发者和研究者不仅可以利用这一强大工具进行应用开发和科研探索,还能通过参与模型优化和应用创新,共同塑造未来AI的发展方向。Meta的这一举措,不仅深化了其在开源AI领域的影响力,也彰显了其在全球科技竞赛中以开放共享促进技术进步的战略眼光。
LLaMA系列对开源社区的影响

1. 降低AI技术门槛:LLaMA系列的开源,使开发者无需从零开始构建复杂的大型模型,即可获得高性能的AI工具,大大降低了AI技术的入门门槛,让更多人有机会参与到AI开发与创新中来。
2. 推动社区创新:LLaMA系列的开放性激发了开发者社区的创新活力。围绕LLaMA模型,开发者创建了各种插件、工具包、接口和应用程序,形成了一个丰富多元的生态系统。这些创新成果不仅服务于社区内部,也在更广泛的领域产生了积极影响。
3. 促进科研发展:LLaMA系列的源代码和数据集为学术研究提供了宝贵资源,推动了AI领域的前沿探索。学者们可以使用LLaMA模型进行实验验证、对比分析或改进研究,加快了AI技术理论与实践的融合与发展。
4. 加强国际合作与交流:LLaMA系列作为全球范围内广泛使用的开源模型,促进了各国开发者、研究者之间的交流与合作。国际化的开源社区围绕LLaMA展开了跨国、跨领域的协作,共同推动AI技术的全球化发展。
结论
从LLaMA 1到LLaMA 3,Meta的开源大模型系列见证了技术的飞跃、生态的繁荣与社区的壮大。每一版本的迭代都带来了参数规模的提升、技术特性的增强以及应用范围的拓宽,持续推动着自然语言处理乃至整个AI领域的边界。
更重要的是,Meta始终坚持开源路线,通过共享模型源码与数据,激发了全球开发者与研究者的创新潜能,促进了AI技术的普及与应用,对开源社区产生了深远影响。随着LLaMA 3的发布与超级算力库的建设,可以预见,Meta将在推动AI民主化、赋能全球创新者的道路上迈出更为坚实的一步。














暂无评论内容