这个开源太牛了!
能够微调100多个主流的LLM
项目特色
多种模型:LLaMA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
集成方法:(增量)预训练、指令监督微调、奖励模型训练、PPO 训练、DPO 训练和 ORPO 训练。
多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
先进算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、LoRA+、LoftQ 和 Agent 微调。
实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
性能指标
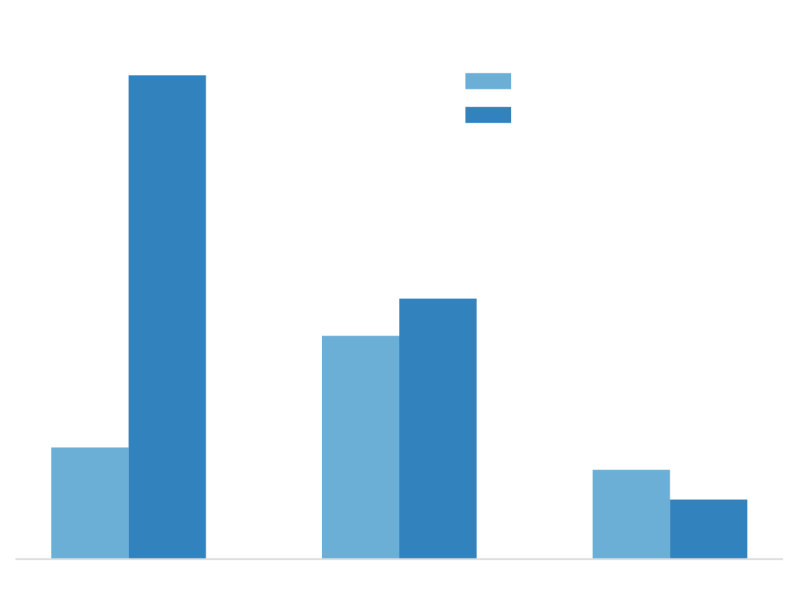
与 ChatGLM 官方的 P-Tuning 微调相比,LLaMA Factory 的 LoRA 微调提供了 3.7 倍的加速比,同时在广告文案生成任务上取得了更高的 Rouge 分数。结合 4 比特量化技术,LLaMA Factory 的 QLoRA 微调进一步降低了 GPU 显存消耗。
LLaMA Factory 介绍
LLaMA Factory 是一个易于使用的大规模语言模型(LLM)微调框架,支持包括LLaMA、BLOOM、Mistral、Baichuan、Qwen 和 ChatGLM 在内的多种模型。该框架旨在简化大型语言模型的微调过程,提供了一套完整的工具和接口,使用户能够轻松地对预训练的模型进行定制化的训练和调整,以适应特定的应用场景。此外,LLaMA Factory 支持多种微调技术,包括(增量)预训练、指令监督微调、奖励模型训练等,并提供多种训练精度选择,如32比特全参数微调、16比特冻结微调等。
P-Tuning 介绍
P-Tuning 是一种基于预训练模型的高效微调方法。它通过调整预训练模型中参数的更新率来优化模型的性能。在微调过程中,P-Tuning 会根据每个参数的重要性及其在预训练模型中的角色来调整其更新率,以实现更精确的模型调整。
LLaMA Factory 的 LoRA 微调与 ChatGLM 官方的 P-Tuning 微调对比
性能提升:与ChatGLM官方的P-Tuning微调相比,LLaMA Factory的LoRA微调在广告文案生成任务上取得了更高的Rouge分数,这表明LoRA微调在文本生成任务上具有更优越的性能。
训练速度:LLaMA Factory的LoRA微调提供了3.7倍的加速比,这意味着使用LoRA微调可以更快地完成模型的训练过程,从而提高工作效率。
GPU显存消耗:结合4比特量化技术,LLaMA Factory的QLoRA微调进一步降低了GPU显存消耗。这使得在资源受限的环境下也能进行有效的模型微调。
综上所述,LLaMA Factory的LoRA微调在性能、训练速度和GPU显存消耗方面都表现出优于ChatGLM官方的P-Tuning微调的特点。这使得LLaMA Factory成为一个强大且高效的工具,用于对大型语言模型进行微调以适应特定的应用场景。















暂无评论内容