作为只使用 GPT API 的开发者,我非常眼馋 ChatGPT 的插件能力,但限于当时 GPT-3.5 没有开放相关接口,虽然可以使用 LangChain 等辅助工具实现类似能力,但终归有些麻烦。不过随着 OpenAI 大更新 ,我们终于可以在利用 API 来实现插件能力了!而实现插件能力的基础就是这次新出的 Function Call。
▍Function Call 是个啥?众所周知,ChatGPT 3 月发布的版本正式支持了第三方插件,这一版本通过插件让 GPT 可以联网获取新知识,并且可以与超过 5000 个应用进行交互。
通过建立插件体系,ChatGPT 不仅可以查询最新的新闻,还可以帮助用户查询航班、酒店信息,规划差旅并访问各大电商数据,甚至可以比价和下单。这使得 ChatGPT 在更多领域发挥更重要的作用,国内外一大堆媒体都铺天盖地地宣传这项功能,形容这就像苹果的 「App Store」。基于官方的文档来看,Function Call 是 GPT API 中的一项新功能。它可以让开发者在调用 GPT-4 和 GPT-3.5-turbo 模型时,描述函数并让模型智能地输出一个包含调用这些函数所需参数的 JSON 对象。这种功能可以更可靠地将 GPT 的能力与外部工具和 API 进行连接,从而实现以下应用:
创建聊天机器人:开发者可以通过调用外部工具,如 ChatGPT 插件,回答问题,或者将查询「北京的天气如何?」转换为调用 getCurrentWeather(location: string) 的函数。
将自然语言转换为 API 调用或数据库查询:例如,将查询「这个月我的前十个客户是谁?」转换为调用 get_customers_by_revenue(start_date, end_date, limit) 的内部 API 调用,或者将查询「上个月 Acme 公司下了多少订单?」转换为使用 sql_query(query)的 SQL 查询。
从文本中提取结构化数据:开发者可以定义一个名为 extract_people_data(people) 的函数,以提取在维基百科文章中提到的所有人物。
▍Function Call 的交互技术解读官方文档为了让大家好理解,举了上面这些例子,我想从我自己感受到的来聊聊这个 Function Call 到底意味着什么。那作为一名懂技术的设计师,自然从我的专业角度 人机交互领域来聊。从人机交互上来说, Function Call 本质上只做了一件事,那就是实现了「准确识别用户的语义,将其转为结构化的指令」。而这,非常了不起。我们如今的交互界面,存在非常多形态的组件,文本输入框、切换器、选择器、操纵滑杆… 这是为什么?原因是我们需要约束用户的输入,才能辅助机器理解我们输入意图。
比如填写一个表单用于收集个人信息。对于机器来说,它无法理解「我叫小明,今年18岁,家在杭州市西湖边」这样非结构化的输入。只有将其拆分为「姓名」「年龄」这样的字段,机器才能识别相应的信息结构,并将这样结构化后的信息接入后续的流程。所以如今的表单这种组件,本质上是人机交互领域一个技术妥协的产物。

再回到 Function Call 本身来说,它实现的最大的价值,就是让机器轻易地理解了用户模糊化的输入,将其转换为机器可以理解的技术指令。这对于人机交互的范式来说,完全是质的改变。
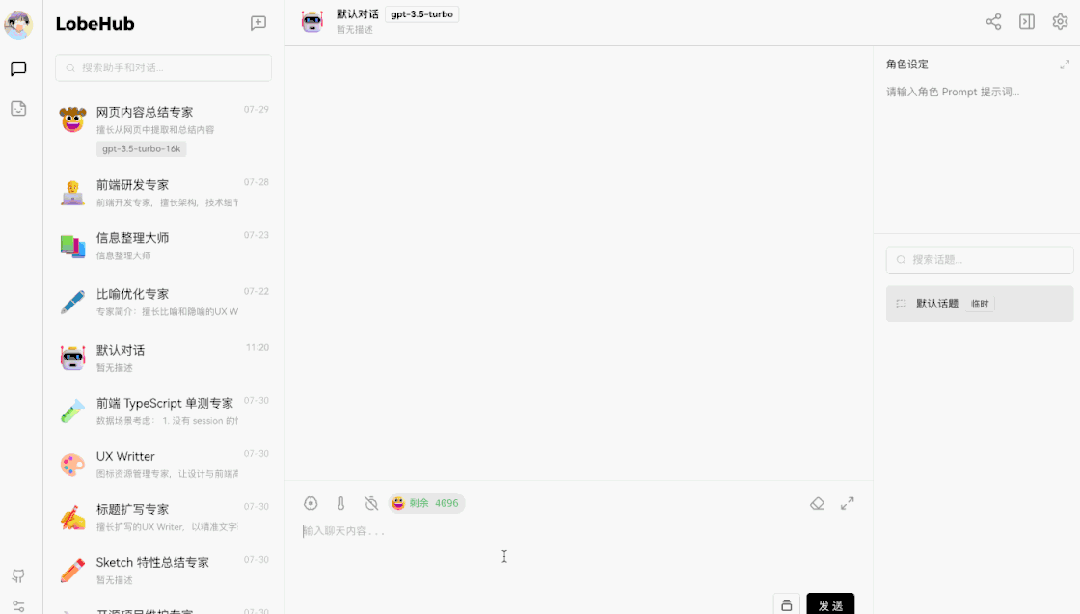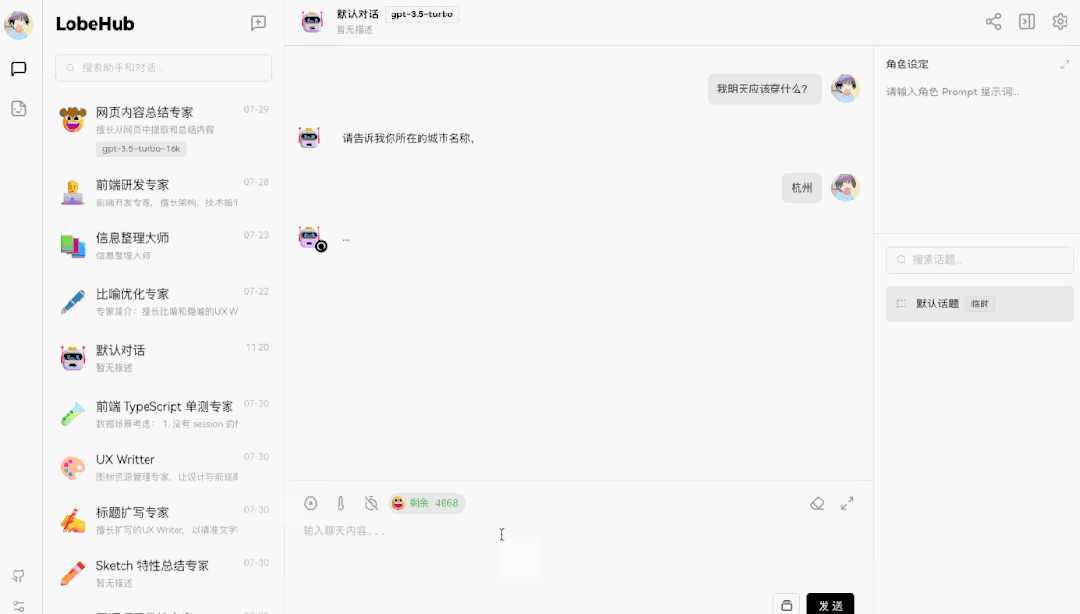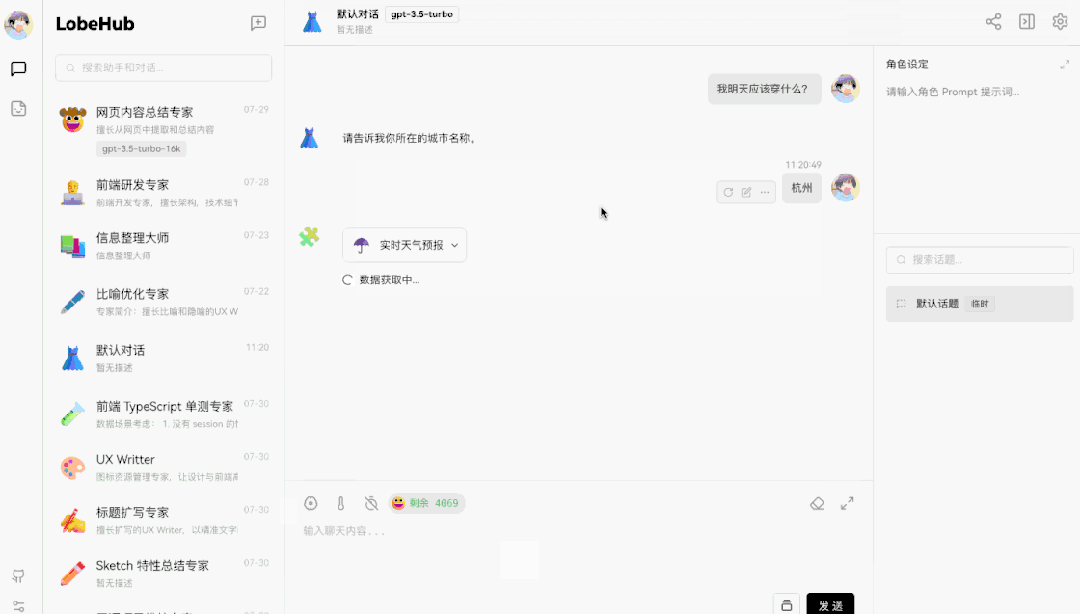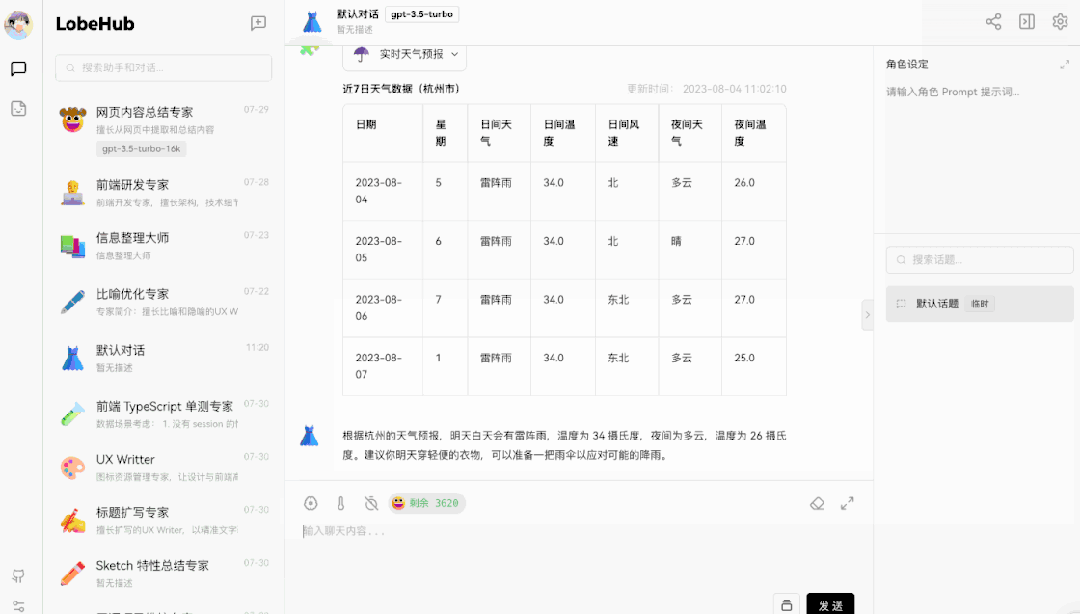
上图演示了一个 Function Call 的典型案例 —— 天气查询插件。但是大家可以注意到的是,我们在提问上并没有直接问明天的天气如何,而是问「我明天应该穿什么?」此时 GPT 完全理解了我的问题,而且知道穿衣建议是需要了解相关天气情况的。因此它问了我在哪个城市,并且在获得该信息后,调用了天气查询插件。并基于天气查询返回的结果,告诉了我穿衣建议。这样的交互形态,在过去是完全不敢想象的。但在 GPT 与 Function Call 的加持下,开发者可以轻松实现用户模糊输入的意图识别,并转换为结构化的系统指令,与现有系统做集成。▍天气插件的实现原理:Function Call 调用揭秘让我们来拆解一下上述的交互流程,仔细看看这个插件的交互是如何实现的。这样的一次交互,包含了5 个对话:
- 用户提出了一个问题:「我明天应该穿什么?」
- AI 提问「请告诉你所在的城市」;
- 用户回答完城市;
- AI 开始调用天气查询插件,获取最近一周的天气数据;
AI 输出穿衣建议;
为了更方便理解本质,我会将上述 5 条消息,转换为伪代码的语法,来方便大家理解:
#1
– role: user
content: 我明天应该穿什么?
#2
– role: assistant
content: 请告诉你所在的城市
#3
– role: user
content: 杭州
#4
– role: assistant
content: “{“name”: “realtimeWeather”,”arguments”: “{\n \”city\”: \”杭州\”\n}”}
#5
– role: function
name: realtimeWeather
content: [{
“city”: “杭州市”,
“adcode”: “330100”,
“province”: “浙江”,
“reporttime”: “2023-08-10 00:02:43”,
“casts”: [
{
“date”: “2023-08-10”,
“week”: “4”,
“dayweather”: “雷阵雨”,
“nightweather”: “多云”,
“daytemp”: “35”,
“nighttemp”: “25”,
“daywind”: “北”,
“nightwind”: “北”,
“daypower”: “≤3”,
“nightpower”: “≤3”,
“daytemp_float”: “35.0”,
“nighttemp_float”: “25.0”
},
]
}]
#6
– role: assistant
content: 根据杭州的天气预报…
上述伪代码中, #1 ~ #3 和 1~3 步没有任何区别。而 #4 ~ #5 在用户侧的感知就是第 4 步。#6 对应的则是第5步。接下来详细讲讲这 6 步到底发生了什么。
理解意图
首先是 #1 ,用户提问「我明天应该穿什么?」,这背后,系统发送给 AI 的请求的信息是下面这样的:
{
“messages”: [
{
“role”: “user”,
“content”: “我明天应该穿什么?”
}
],
“functions”: [
{
“name”: “realtimeWeather”,
“description”: “获取当前天气情况”,
“parameters”: {
“type”: “object”
“properties”: {
“city”: {
“description”: “城市名称”,
“type”: “string”
}
},
“required”: [
“city”
],
}
}
]
}
除了 messages 以外,我们还向 GPT-3.5 传递了一个 functions 的列表,在这个列表中,我们使用 JSON Schema 描述了 GPT 可以调用的方法 ,即 realtimeWeather 。
我们在这个方法的描述中介绍了这个方法的作用。同时这个方法支持传入 city 这一个参数,参数名为城市,且 city 这个参数是必填的。
收集必要信息
讲完了 #1,接下来看 #2,AI 的消息是:「请告诉你所在的城市」。注意到了没,其实从这一步开始,GPT 已经识别了用户的意图,并试图尝试去调用 realtimeWeather 的外部方法。但是由于这个方法中的入参 city 是个必填项,而此时它并不知道,因此需要从用户侧了解到该信息。再来看 #3,用户回答了 「杭州」,此时我们再来看下发送给 GPT 的消息:
{
“messages”: [
{
“role”: “user”,
“content”: “我明天应该穿什么?”
},
{
“role”: “assistant”,
“content”: “请告诉你所在的城市?”
},
{
“role”: “user”,
“content”: “杭州”
},
],
“functions”: [
{
“name”: “realtimeWeather”,
“description”: “获取当前天气情况”,
“parameters”: {
“type”: “object”
“properties”: {
“city”: {
“description”: “城市名称”,
“type”: “string”
}
},
“required”: [
“city”
],
}
}
]
}
OK,基于 #1~#2 的分析和 #3 的消息,我们现在已经知道:
- GPT 准确识别了用户的意图,并想要尝试调用 realtimeWeather 的方法;
截止 #3,realtimeWeather 所需要的参数(city),在会话中已经齐全。
返回意图识别结果
那么接下来就看其中最重要的 #4 。#4 的返回消息如下:
{
“role”: “assistant”,
“content”: “{“name”: “realtimeWeather”,”arguments”: “{\n \”city\”: \”杭州\”\n}”}
}
可以看到 GPT 在 content 中返回了一串 JSON 内容,将其格式化:
{
“name”: “realtimeWeather”,
“arguments”: {
“city”: “杭州”
}
}
通过上述 JSON 可以发现, GPT 准确返回了它想要调用的方法名称 realtimeWeather 与相应的参数 “city”: “杭州”。是不是有点 Amazing ?这就是 Function Call 的特性。为了让机器理解人类的意图,过去我们想方设法去「约束用户行为」或者「猜测用户意图』。但时代已经开始变了,通过 Function Call, 我们只需要在发送给 GPT 请求时加一个 functions 的参数,告知 AI 可以调用的外部方法有什么,然后 AI 就能够自动分析问题的上下文,并通过多轮对话来收集必要的调用参数,最后拼合返回调用方法的 JSON。这对于开发者来说已经友好到极致了,研发成本大大降低,但效果又大大提升。外部 API 调用OK,接下来再看 #5。这一步其实也是之前非常困惑我的地方。我曾以为是 OpenAI 会在背后帮我们执行一个什么插件的服务调用。但通过自行实现一遍后才发现其实并不是这样。#5 做的事情,本质上就是一次常规的 API 调用。因为当我们获取到调用方法的指令之后,如何运行这个指令,已经和 GPT 的接口无关了。你可以自行决定这个 API 应该如何调用。比如在上述天气预报的查询结果,就是调用了一下高德的天气预报接口,返回的结果如下:
[{
“city”: “杭州市”,
“adcode”: “330100”,
“province”: “浙江”,
“reporttime”: “2023-08-10 00:02:43”,
“casts”: [
{
“date”: “2023-08-10”,
“week”: “4”,
“dayweather”: “雷阵雨”,
“nightweather”: “多云”,
“daytemp”: “35”,
“nighttemp”: “25”,
“daywind”: “北”,
“nightwind”: “北”,
“daypower”: “≤3”,
“nightpower”: “≤3”,
“daytemp_float”: “35.0”,
“nighttemp_float”: “25.0”
},
{
“date”: “2023-08-11”,
“week”: “5”,
“dayweather”: “晴”,
“nightweather”: “晴”,
“daytemp”: “35”,
“nighttemp”: “25”,
“daywind”: “北”,
“nightwind”: “北”,
“daypower”: “≤3”,
“nightpower”: “≤3”,
“daytemp_float”: “35.0”,
“nighttemp_float”: “25.0”
},
{
“date”: “2023-08-12”,
“week”: “6”,
“dayweather”: “多云”,
“nightweather”: “多云”,
“daytemp”: “35”,
“nighttemp”: “26”,
“daywind”: “北”,
“nightwind”: “北”,
“daypower”: “≤3”,
“nightpower”: “≤3”,
“daytemp_float”: “35.0”,
“nighttemp_float”: “26.0”
},
{
“date”: “2023-08-13”,
“week”: “7”,
“dayweather”: “雷阵雨”,
“nightweather”: “多云”,
“daytemp”: “35”,
“nighttemp”: “25”,
“daywind”: “西南”,
“nightwind”: “西南”,
“daypower”: “≤3”,
“nightpower”: “≤3”,
“daytemp_float”: “35.0”,
“nighttemp_float”: “25.0”
}
]
}]
那返回的结果应该如何和 AI 的会话集成在一起?OpenAI 在 GPT 系列的消息类型中,专门为外部接口的请求结果,定义了 function 这样一种类型,与 user 、system、assistant 区分开来。(我个人猜测 GPT 应该会针对这类消息做优化,用于提取其中的有效信息)
我们在会话应用中,就需要按照 GPT 的规范,构造出一个 function 的消息:
– role: function
name: realtimeWeather
content: “[{ “city”: “杭州市”, … }]”
其中 name 字段是必填的,为这个方法的调用名称。content 字段直接放入接口返回内容(需要转成字符串)。
解读 API 返回的结果
构造完成 function 消息后,我们需要将 #1~#5 的消息再次发送给 GPT。此时的请求消息如下:
{
“messages”: [
{
“role”: “user”,
“content”: “我明天应该穿什么?”
},
{
“role”: “assistant”,
“content”: “请告诉你所在的城市?”
},
{
“role”: “user”,
“content”: “杭州”
},
{
“role”: “assistant”,
“content”: “{“name”: “realtimeWeather”,”arguments”: “{\n \”city\”: \”杭州\”\n}”}
},
{
“role”: “function”,
“name”: “realtimeWeather”,
“content”: “…”
}
],
}
这一轮消息已经包含了用户的原始问题(#1)、必要入参的收集(#2、#3)、调用 API 的 JSON 指令(#4)与 外部 API 调用的结果(#5)。另外之前需要传入的 functions 字段,已经不需要再传入了。因为 functions 只是为了让 AI 来决策使用什么外部方法。当外部方法已经完成调用后,就不再需要传入。那接下来就是见证魔法的时刻:
{
“role”: “assistant”,
“content”: “当前杭州的天气是晴天,温度在36度左右。明天预计会有雷阵雨,温度在26-35度之间。因此,建议你今天穿短袖和短裤,明天则需要带一把雨伞,并穿一些防水的衣物,同时也不要忘记防晒。”
}
GPT 在上述 5 条消息的输入下,告诉我了我明天穿衣的建议,并贴心地提醒我记得带一把伞。这一轮会话也就此结束。▍黎明前的沉思在 3 月份 OpenAI 开放 GPT-3.5 接口时,我十分激动,立即投入到大模型的交互与实现的研发中。一晃已经小半年过去了,LLM 的实践也逐渐多了起来,但目之所及,大部分都是 ChatGPT 的复刻,并没有出现 AI 与现有产品体系做到有机结合,实现 1 + 1 > 2 的效果.我想其中的核心问题就是在于现有的AI模式,聊天会话的形态与现有的生产体系是格格不入的。如何无缝地将 JSON 化的指令信息与系统消息与集成到会话,如何让现有的系统中友好地集成会话能力,两个问题都是难啃的骨头。而 Function Call 的发布,我觉得是给社区提供了一种现有系统能力轻松集成进会话的实现范式。开发者只需要极低的研发成本,就可以为用户带来完全不同的产品体验,进而引发更巨大的产品形态变革,用户与界面的交互方式也会产生质的飞跃。在之前很多人提的「颠覆现有的人机交互」,我认为 Function Call 的出现,才真正让这个口号有了一个开始。
开源 Chat 应用的插件生态
我和我的小伙伴们,也自己做了一个 Lobe Chat 。本文演示的天气插件,就是在我们自己做的这个 Chat 应用中实现的。不过当前 Lobe Chat 仍然处于 0.x 的快速开发阶段,暂时还没有完成全量能力,因此我也不会过多介绍,只在本文提一些相关的插件应用。
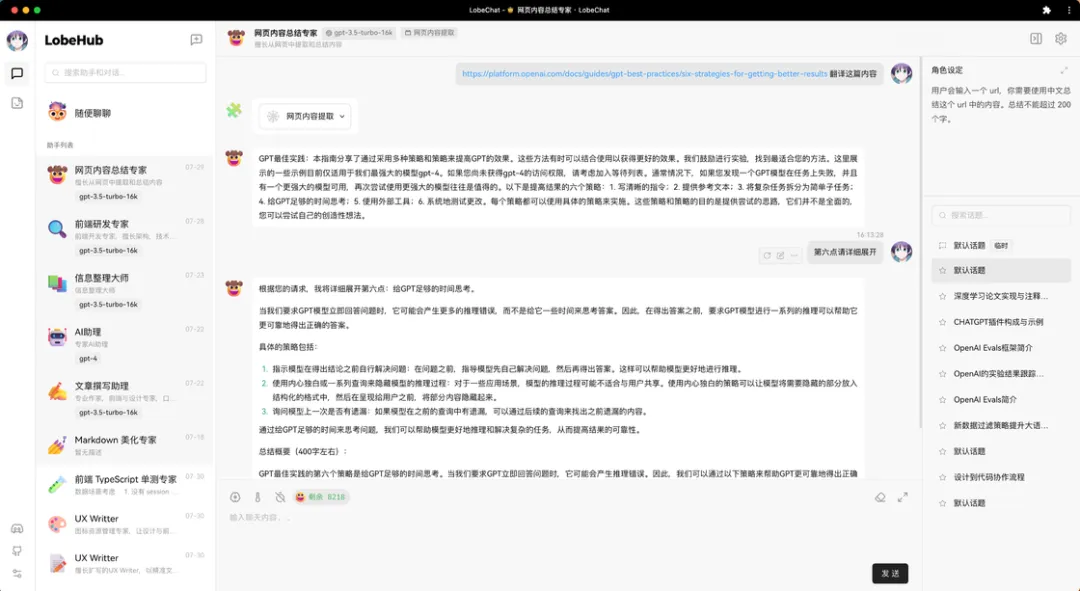
上文的天气插件只是一个示例,用于演示跑通插件会话链路。而我从自己的诉求出发,还做了两个能「联网」的插件:一个是「网页内容提取」,发送给 AI 一个 url,它就会自动帮我总结文章中的内容,并且我可以基于这篇文章进行多轮会话,按照我习惯的方式来获取文章内容。
另一个则是「搜索引擎」。让 GPT 支持调用 Google 搜索引擎的能力。比如我自定义的一个「前端专家」的角色中,为它开启了搜索引擎插件,同时告诉它,在不知道怎么解决问题时,查一查搜索引擎。这样当我问一些不在 GPT 知识领域的内容时,它会自动调用搜索引擎,并给我一个总结后的结果。
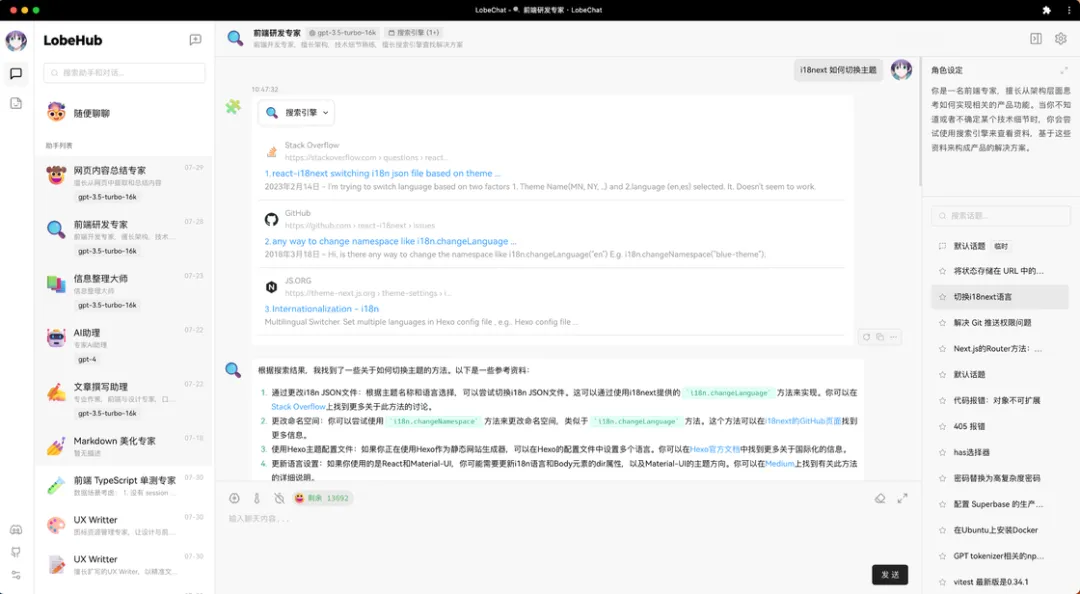
而遇到一些更复杂的情况下,AI 也会尝试「搜索引擎」与「网页内容提取」搭配使用。先通过搜索引擎找可能的资料,然后再阅读单篇内容,最后给我一个总结。
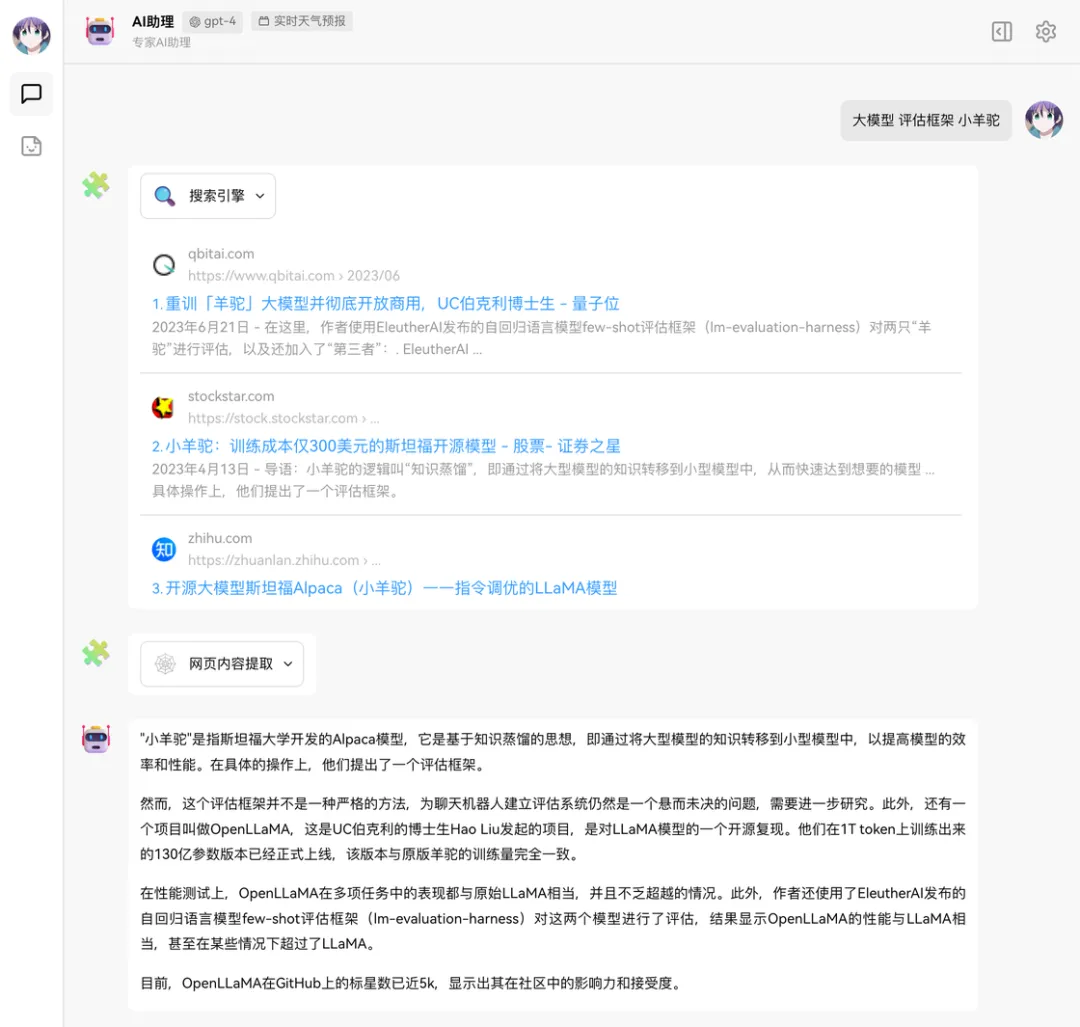
ChatGPT 的插件市场在 OpenAI 内部是被定性为「一个失败的尝试」,但我觉得他们在这次实践后,提供出来的 Function Call ,对于技术应用来说却是非常有价值的。API 的开放,让开源社区诞生不少少仿 ChatGPT 的开源 Chat 应用。如同 stable diffusion 相关的生态插件一般, Function Call 我想也会带来同等规模的插件生态,还有很多很多的玩法有待社区探索。
开源 LLM 的下一城
当然,在国内守着 ChatGPT 是没希望的,我们必须要支持本地大模型的才行。那随着 LLaMA 2、ChatGLM 2、Qianwen 等一众大模型的开源进程加速,大家现在已经不再愁没模型可用了。但怎么和大家已有的业务系统集成,真正落地生产,才是现阶段关注的。天气插件的例子,大家应该可以发现,其实识别用户意图、调用外部 API 与基于 API 内容进行总结,是三个互相独立的阶段。而任何传统应用,都可以在不大改造的情况下接入「用户意图识别」的能力,以增强现有系统的用户体验。这是目前阶段我觉得性价比最高的大模型接入方案。所以我觉得开源 LLM 们角逐的下一个领域,我想一定是 Function Call 类似的能力。譬如前段时间看到一个开源模型已经实现了一个 ToolLLaMA,在 16000+ 真实 API 数据集基础上实现了类似 Function Call 的效果。如果类似的能力在各大开源模型下默认集成,这个模型的生产可用能力一定会大大加强。AI 时代的交互技术在做 Lobe Chat 的天气插件能力时,我一开始什么也没展示,直接让 AI 做了内容的输出。
但 AI 返回的内容是一坨纯文本,看着费劲。于是乎又将其转变成了表格(当然,最理想的应该是可视化图表,偷懒了就没搞)。
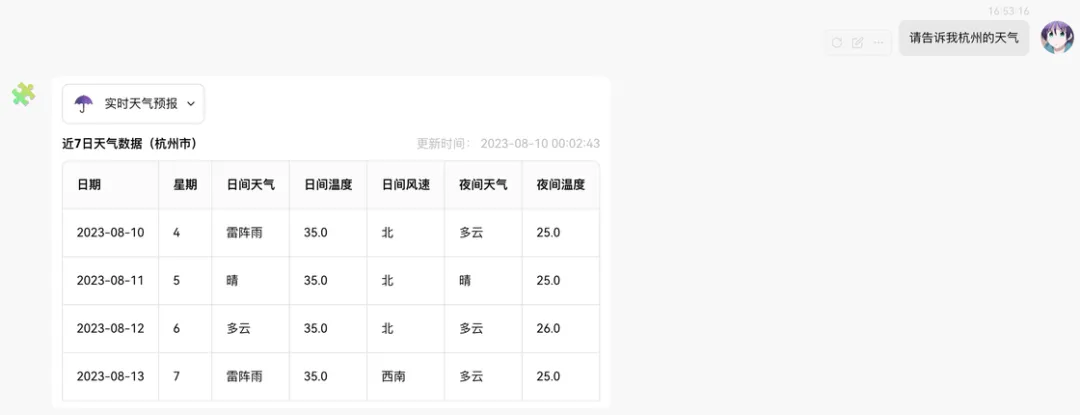
完成这个插件后,我有了一个更加深刻的感触:人真的是一种很贪心的生物。总是想要别人给你结构化展示,轮到自己却只想模糊输出,且越少越好。AI 时代的来临,也无法改变人们喜欢直观、简洁、甚至偷懒的本性。所以鼓吹「未来所有设计师、前端都要失业,用户只需要一个输入框」的言论,大概也不可能成真。人们喜欢结构化的展示,就意味着曾经的信息展示的范式仍然适用,而 AI 的出现可以帮助用户实现更好的「模糊输入」,减少大量页面流程的跳转、表单的填写。用户体验可以在 AI 的加持下有个质的提升。在这样的时代,关注交互技术的设计师与前端们,甚至比过去更大有可为。














暂无评论内容