近几个月以来,AI 智能体(AI Agent)的话题一直是整个 AI 业界的关注焦点。尽管概念炒得火热,但一个 AI 智能体的具体内涵究竟应该是怎样的,绝大多数人并没有一个清晰的认知。
而就在前几日,人工智能专家、斯坦福大学教授吴恩达在红杉资本的人工智能峰会(AI Ascent)上进行了一次演讲,畅谈了他对 AI 智能体的种种看法。

在这次演讲中除了介绍目前智能体工作流的优越性外,还提出了智能体设计的主流模式。
与此同时,他还认为今年在得益于 AI 智能体工作流的帮助,人工智能的能力范围还将持续拓展。本次淼翰实验室将结合吴恩达此次演讲的内容与后续补充博客,对他的 AI 智能体观点进行完整梳理。
01.
AI 智能体工作流
为现有大模型强化赋能
吴恩达以现在绝大多数人对大语言模型的使用作为开场,他描述非智能体,也就是现在的大语言模型的工作流,就是「输入提示,模型生成答案」的格式化流程。这就像一个人坐在键盘前一口气写完一篇文章,中间无法进行修改。
作为对比,吴恩达认为智能体工作流应该是:
规划一个大纲。
确定需要进行哪些网络搜索(如果需要)来收集更多信息。
写初稿。
通读初稿,找出不合理的论点或无关的信息。
修改草案时考虑到发现缺点。
……
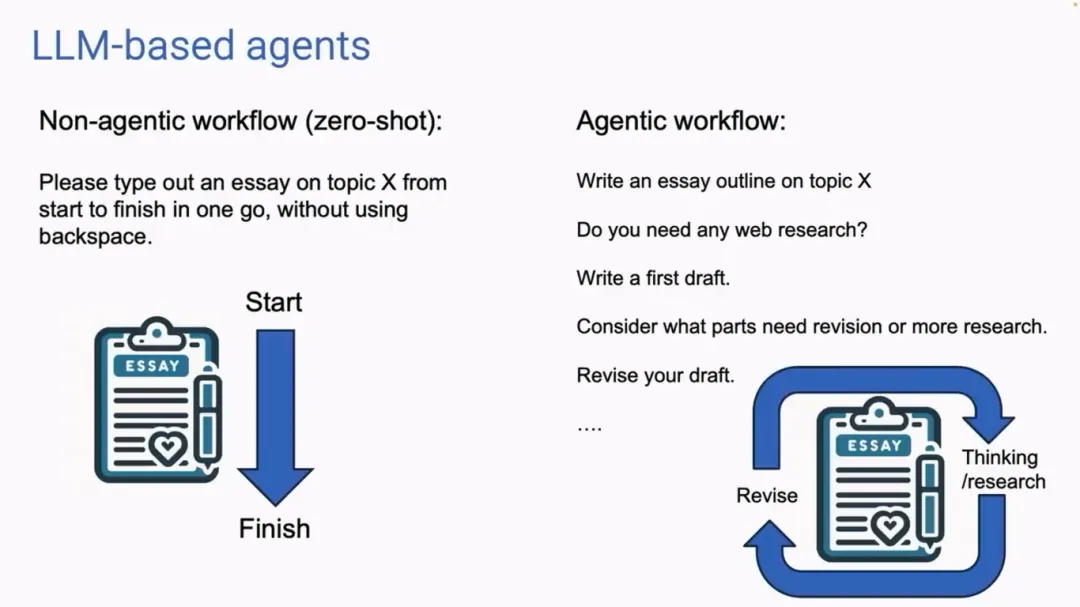
而在有了 AI 智能体的加持后,这个过程还要经历反复迭代,期间 AI 则要不断重复思考、修改。
吴恩达认为很多人并没有意识到这种工作流会带来质的飞跃,因此他举了一个例子。受到最近大火的 AI 程序员 Devin 的启发,其团队也使用 OpenAI 此前发布的 HumanEval 基准测试了目前主流大模型,包括 GPT-3.5 与 GPT-4 等,在零样本提示(Zero-shot Prompting)下的编程能力。
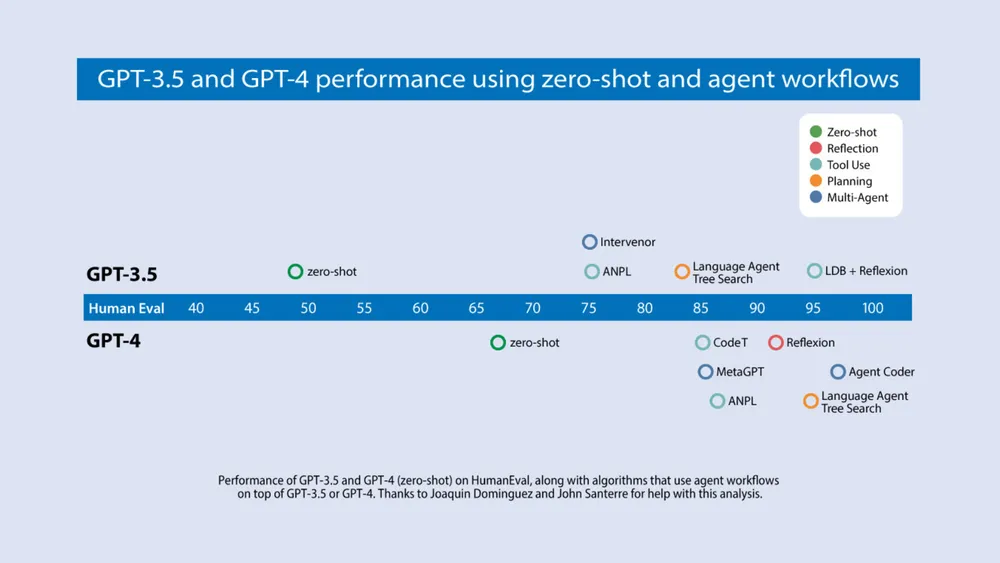
结果显示在零样本提示情况下,GPT-3.5 的正确率只有 48%,而 GPT-4 则好一点,有 67%。但如果给 GPT-3.5 添加上智能体工作流,它的正确率就会达到 95.1%,成功反超 GPT-4;如果再把智能体工作流与 GPT-4 进行结合,它的正确率则会更高。
对于吴恩达来说,智能体工作流的出现能够让 LLM 在无需模型的情况下进一步升级,能焕发出更大的工作能力。
吴恩达表示,确实有很多人已经认识到了「AI 智能体是 AI 的未来」,很多相关研究也正在推进当中,但这一领域仍「混乱且混沌」。因此在这次演讲中,吴恩达也对 AI 智能体的发展形式做出归纳,并总结出了目前 AI 智能体的四种设计模式:
反思(Reflection):大语言模型检查自己的工作以提出改进的方法。
工具使用(Tool use):大语言模型拥有网络搜索、代码执行或任何其他功能等工具来帮助其收集信息、采取行动或处理数据。
规划(Planning):大语言模型提出并执行一个多步骤计划来实现目标。
多智能体协作(Multi-agent collaboration):多个人工智能智能体一起工作,分解任务并讨论和辩论想法,以提出比单个智能体更好的解决方案。
吴恩达希望在厘清了这四种智能体设计模式后,能够帮助广大开发者按照这样比较清晰的思路框架进行探索,并以此获得生产力的提升。
02.
四种设计模式详解
全面展望智能体工作流
接着在演讲中,吴恩达开始分别对这四种 AI 智能体的设计模式进行介绍。
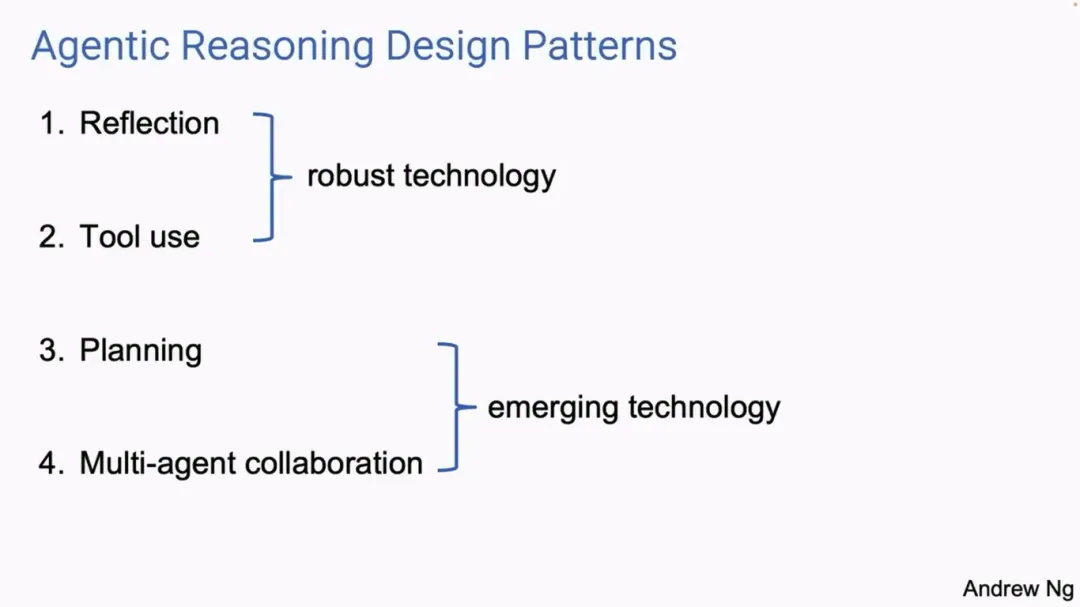
反思(Reflection)
首先是「反思」。吴恩达表示目前 AI 智能体的反思模式已可以直接使用,并且对于实现相对较快的设计模式,已经非常实用。
比如在提示 ChatGPT/Claude/Gemini 时,绝大多数人可能都有收到不满意的输出、提供关键反馈以帮助其响应,然后获得更好响应的经历。而反思正是将这一过程自动化的关键。
吴恩达举例说明,比如让系统为某个任务编写代码,其中一个 AI 编程助手帮助生成代码,接下来就可以让语言模型对自己生成的代码做出反思,提示它「仔细检查代码的正确率、鲁棒性、效率与代码风格,指出可能存在的问题」,语言模型很可能就会发现自己代码中的 bug,并会提出建设性建议。
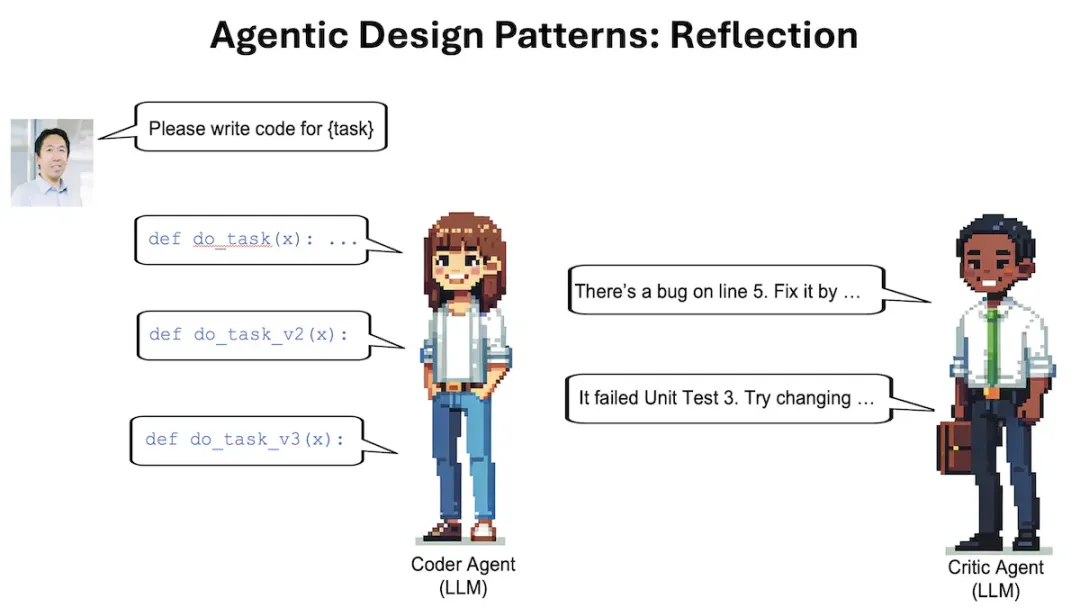
如果把包括 (1) 之前生成的代码与建议,以及 (2) 要求模型使用这些反馈来重写代码,都提示给大语言模型,这可能会带来更好的响应。这也就是所谓智能体的「自我反思」过程,能够使 LLM 发现差距并改进各种任务的输出,包括生成代码、编写文本和回答问题等。
但吴恩达认为我们可以通过提供 LLM「工具」来帮助评估其输出,从而超越自我反思:比如通过一些单元测试运行期代码以检查它是否在测试用例上生成正确的结果,或者搜索网络以仔细检查文本输出,然后反思所发现的任何错误并提出改进的想法。
另外,「反思」还可以使用「多智能体」框架来实现。他发现可以很方便地创建两个不同的智能体,其中一个提示用来生成良好地输出,而另一个提示用来对第一个智能体的输出提出建设性批评,两个智能体间的讨论导致了相应的改进。
他总结道,「反思」是一个相对基本的智能体工作流类型,但他确实在某些情况下改善了他的应用程序结果,并推荐很多人有兴趣去尝试这种模式。
工具使用(Tool use)
吴恩达总结第二种智能体设计模式就是「工具使用」。吴恩达表示「工具使用」作为 AI 智能体工作流的关键设计模式,已经得到了更加广泛地认可。其中 LLM 被赋予了可以请求收集信息、采取行动或操作数据的功能。吴恩达认为一些面向消费者的大语言模型已经融入了这些功能,但 AI 智能体的「工具使用」能力范围应远超目前所能使用的边界。
吴恩达用了两个例子说明目前 LLM 如何调用工具:
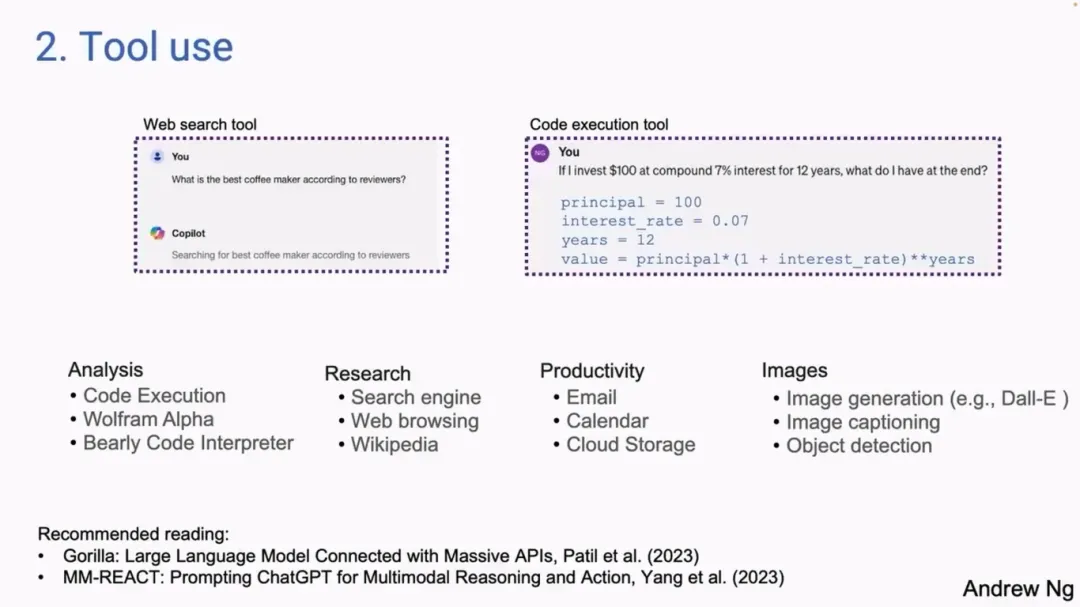
第一个例子是用微软的 BIng Copilot 进行提示,询问「根据评论者的说法,最好的咖啡机是什么?」,此时 Copilot 可能会决定进行网络搜索并下载一个或多个网页以获取上下文。
早期的 LLM 开发者意识到,仅仅依靠预训练的 Transformer 来生成输出 tokens 是有限制的,而为 LLM 提供网络搜索工具则可以让它做更多的事情,有了这样的工具,LLM 要么被微调,要么被提示生成一个特殊的字符串,比如用:
{tool: web-search, query: “coffee maker reviews”}
来请求调用搜索引擎。接着后处理步骤会查找此类字符串,并使用相关参数调用网络搜索函数,并将结果作为附加输入传递回 LLM,来进一步处理上下文。
而第二个例子,就是询问 GPT-4 提示词「如果我以 7%的复利投资 100 美元 12 年,我最后会得到什么?」,此时 LLM 就不会尝试直接使用 Transformer 或网络来生成答案,而是会使用代码执行工具来运行 Python 命令来计算,字符串为:
{tool: python-interpreter, code: “100 *(1+0.07)**12”}
但吴恩达认为,现在的智能体工作流中的「工具使用」则更进一步,比如开发人员正在使用工具来搜索不同的来源(网络、维基百科、arXiv 等)、与生产力工具交互(发送电子邮件、读写日历条目等)、生成或解释图像等等。
吴恩达表示,我们可以使用给出许多函数详细描述的上下文来提示 LLM,而这些描述可能包括函数功能的文本描述以及函数期望的参数的详细信息。他还表示他希望 LLM 能够自动选择正确的函数调用来完成工作。
与此同时正在构建的系统中,LLM 可访问数百种工具,在这种设置中,可能有太多函数可供使用,无法将它们全部放入 LLM 上下文中,因此吴恩达推荐使用启发法选择最相关的子集,以便在当前处理步骤中将其包含在 LLM 上下文中。
吴恩达也谈到,在 LLM 发展的早期,当时大型多模态模型(LMM)还没被广泛使用,LLM 无法直接处理图像,因此当时的 CV 社区就在「工具使用」上开展了大量工作。当时基于 LLM 的系统处理图像的唯一方法就是调用函数来执行对象识别或其他功能,「工具使用」开始呈爆炸式增长。而 GPT-4 的函数调用功能公布,则是迈向「通用工具使用」的重要一步。
规划(Planning)
吴恩达表示,对于现在的智能体工作流来讲,「反思」与「工具使用」设计模式已经表现得相当可靠,而另外两种设计模式——「规划」与「多智能体协作」则正在兴起当中。吴恩达说在使用过程中甚至有时对它们的工作效果感到震惊,但至少在目前这个时刻,他觉得还无法让其可靠地工作。
对于「规划」,吴恩达认为对没有接触过规划算法的人来讲,「规划」模式的震撼程度不亚于「ChatGPT 时刻」。大部分系统可能在现场演示时出现错误,而智能体自主则会绕过错误自动完成任务。吴恩达以一篇改编自 HuggingGPT 的论文为例,输入的提示词是:请生成一张图像,一个女孩在看书,她的姿势和图像中的男孩一样。然后用你的声音描述这张新图像。

处理这个问题,现在的 AI 智能体首先会判断男孩的姿势,然后找一个合适的模型,或者是从 Hugging Face 上自动找到提取姿势的信息。接着就是找到一个生成模型来合成一张女孩的图像,姿势要和所提供的例子一致,再用图转文模型生成描述,最后用文转语音合成语音。
吴恩达表示目前这种系统还不是 100%靠谱,还是有些不稳定,但是如果成功其效果将相当惊艳。而且智能体还可以通过循环往复,从过去的失败中吸取教训。吴恩达承认自己有些时候不想自己上网查资料,就把一些任务交给研究助手,几分钟后再看它的效果,尽管这些工作结果时好时坏,但是已成为他工作流中的一个重要环节。
多智能体协作(Multi-agent collaboration)
最后一种设计模式就是「多智能体协作」,实际效果更是超乎想象。
吴恩达以开源项目 ChatDev 举例。在这个项目存在着多个智能体,通过提示,就可以让一个语言模型扮演 CEO、设计师、产品经理、开发人员等不同角色,从而自动「调教」智能体相互协作,展开一段冗长的对话。如果需求是开发一款 GUI 游戏的话,那么这些智能体则会自动写代码、测试、迭代,最后形成一套相当复杂的程序。尽管这套流程还算不上成功,但是效果已经足够惊人,而且技术也在不断进步。
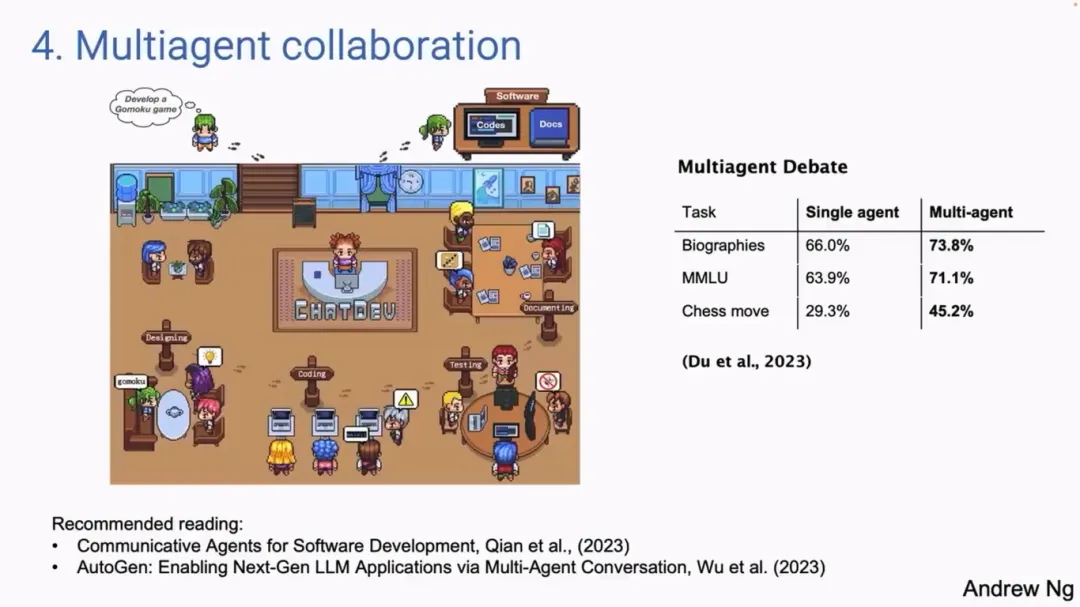
此外,「多智能体协作」的另一形式就是多智能体辩论,比如让 ChatGPT 与 Gemini 进行辩论,这实际上也能带来性能上的提升。吴恩达表示,让多个模拟智能体系统工作,将成为一种非常强大的设计模式。
03.
结语
在演讲最后,吴恩达对 AI 智能体做出了总结,认为如果我们在工作流中采用上述这些模式,就可以在短时间内大幅提升工作效率,智能体推理的设计模式将会变得越来越重要。

吴恩达还对 AI 智能体进行了大胆展望。他预计,得益于智能体工作流,人工智能的能力范围将会在今年得到大幅扩展。
但吴恩达认为还有一点需要所有人去适应,那就是我们在提示语言模型时总是希望它立即给出回应,但这或许是由于人们长期使用「搜索引擎」的使用习惯导致;而对于 AI 智能体来讲,我们需要学会把任务交给 AI 智能体,并耐心等待几分钟或几个小时,才能完成任务。
另一个吴恩达谈及的重要趋势,就是 token 的快速生成。在智能体工作流中,需要反复迭代,语言模型要生成大量 token 以供自己阅读。吴恩达还提了一个引发争议的想法,他认为即便质量略低一点,如果能够更快速地生成更多 token,那可能比高质量但生成速度慢的模型更有效。对吴恩达来讲,因为这样做可以用更快的迭代速度来弥补单词输出质量的不足。

吴恩达也非常期待未来将出现的 GPT-5、Gemini 2.0、Claude 等优秀的基座大模型,但认为如果现在就能够以零样本的方式获得 GPT-5 类似的体验,那么他认为现在使用 AI 智能体应用或许就可以接近同一水平了。
最后吴恩达也坦言,通往 AGI 的道路或许更像是一段旅程而不是目的地,那么 AI 智能体工作流或许可以帮助我们在这漫长的旅程中向前迈出一小步。














暂无评论内容