Stable Diffusion 3,它终于来了!

足足酝酿一年之多,相比上一代一共进化了三大能力。
来,直接上效果!
首先,是开挂的文字渲染能力。
且看这黑板上的粉笔字:
Go Big or Go Home (不成功便成仁),这个倒是杀气腾腾啊~
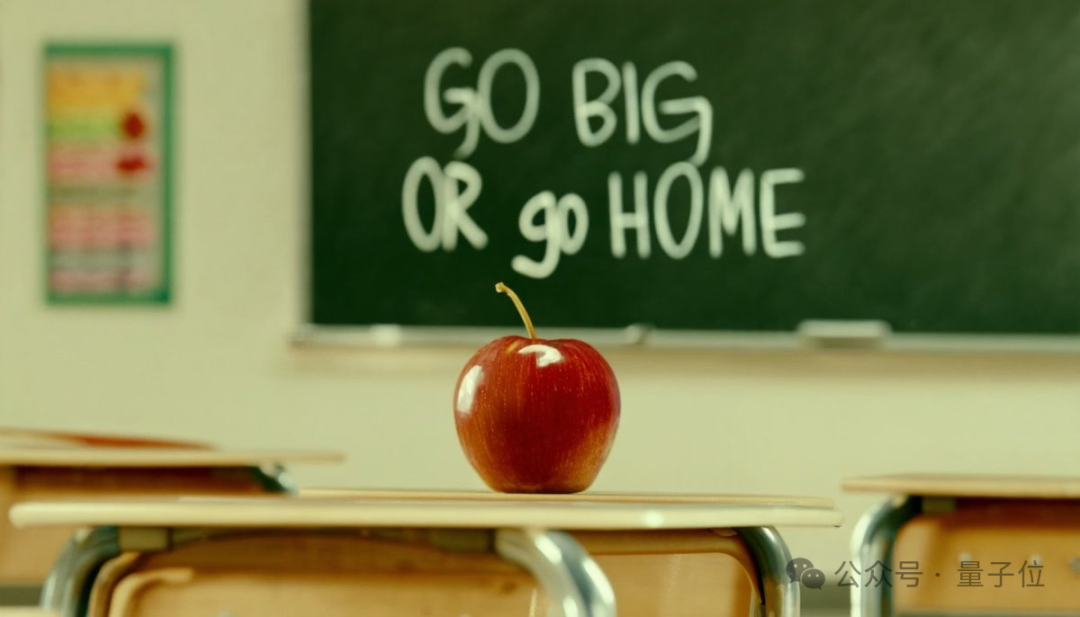
路牌、公交灯牌的霓虹效果:

还有刺绣上“勾”得快要看到针脚的“晚安”:

作品一摆出,网友就大呼:太精确了。

以至于有人表示:赶紧把中文也安排上啊。

其次,多主题提示能力直接拉满。
什么意思?你尽管一次性往提示词中塞入n多“元素”,Stable Diffusion 3:漏一个算我输。
呐,仔细瞅下图,这里面就有“宇航员”、“穿着芭蕾舞裙的小猪”、“粉色雨伞”、“戴着礼帽的知更鸟”,角落里还有“Stable Diffusion”几个大字(可不是什么水印)。

有了这个能力,一幅作品你想多丰富就有多丰富。
最后,当属图像质量,再次进化了一个度。
光看前面这些图,就被冲击到有没有?!
而各种超清特写,那是再信手拈来不过的了。

心动吗?目前官方已开放排队名单,大伙可以前往官网申请。
咳咳,也不得不说,最近这AI圈可真是相当热闹啊。
有网友直呼,我的电脑已经Hold不住了……
Stable Diffusion 3来了!
全新的Stable Diffusion效果有多好,再给大伙奉送一些。
当然,所有出图均来自官方,比如StabilityAI媒体负责人:
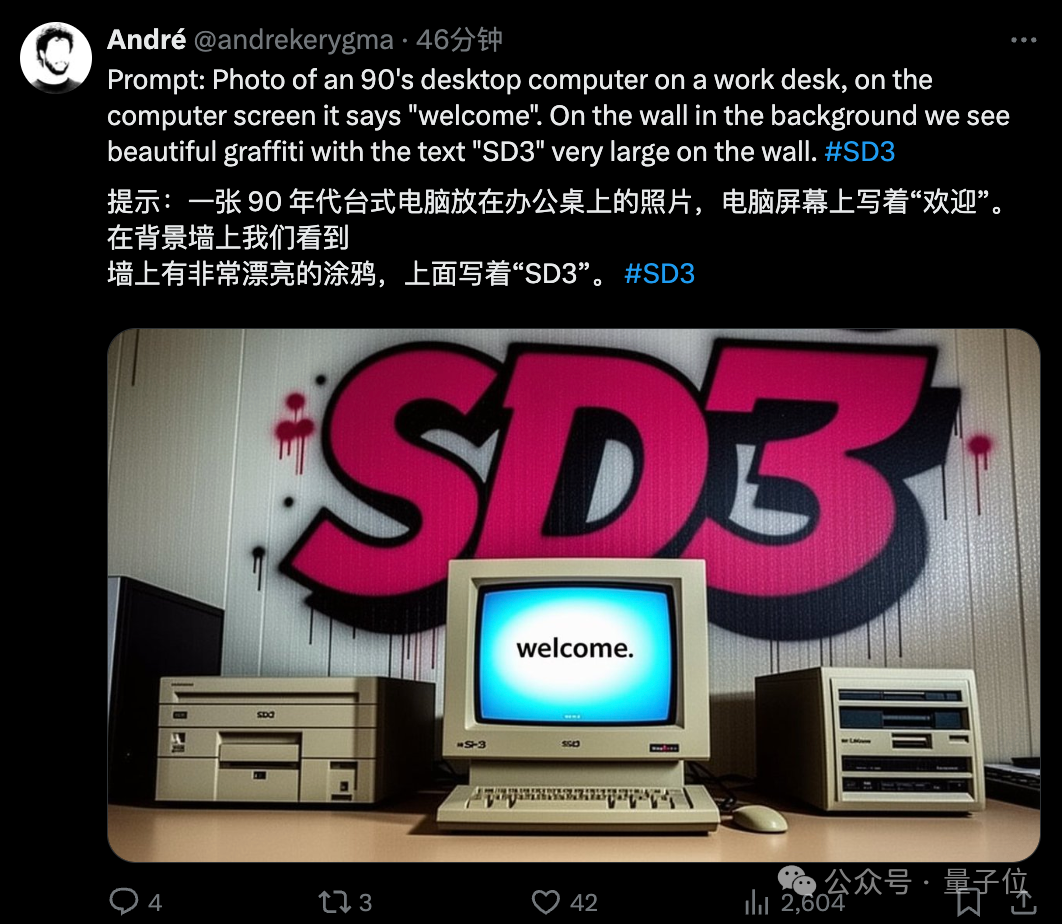
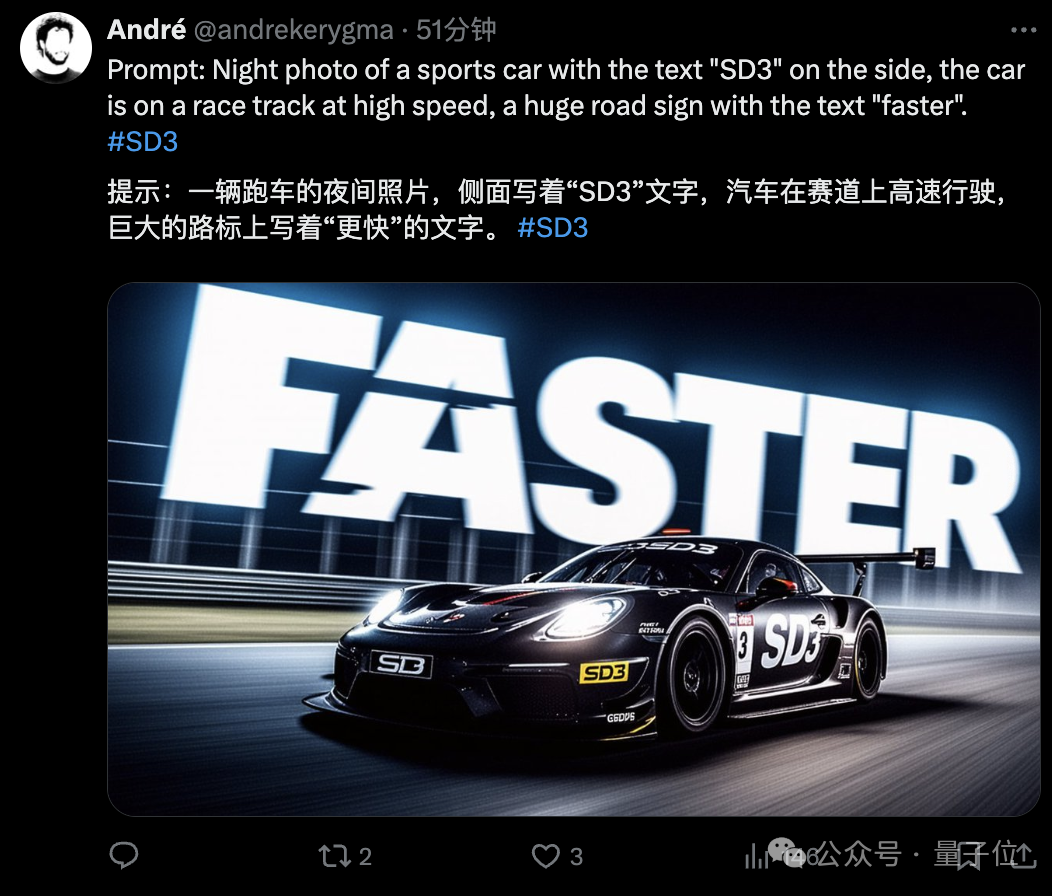
不得不说,文字效果实在最为吸人眼球,各种形式都能呈现得相当清楚和“应景”。

而看到上面这幅图,不得不想到“Midjourney尴尬亮相学术界:为生物学论文乱配图”一事——有了SD3之后,我们是不是可以制作非常专业的学术配图了?
除了这些,SD3的“酒精水墨画”也相当别出心裁:

动漫风格:
again,你可以在上面加清晰的文字了。

由于目前需要排队申请,大伙还不好实际测试摸底。
不过有机智的网友已经用相同的提示词喂给了Midjourney(v 6.0)。
比如开头的那张“红苹果与黑板字”(prompt:cinematic photo of a red apple on a table in a classroom, on the blackboard are the words “go big or go home” written in chalk)
最终Midjourney给出的结果如下:


从这组对比来看,可以说是高下立判——SD3无论是文字拼写还是质量、色彩协调性等方面都更胜一筹。
技术方面,目前,模型可选择的参数范围在800M到8B。
详细的技术报告还未公布,官方目前只透露主要结合了扩散型transformer架构以及flow matching。
前者实际上同Sora一样,附上的技术论文正是22年William Peebles同谢赛宁合写的DiT。

DiT首次将Transformer与扩散模型结合到了一起,相关论文被ICCV 2023录用为Oral论文。
在该研究中,研究者训练了潜在扩散模型,用对潜在 patch进行操作的 Transformer 替换常用的 U-Net 主干网络。他们通过以Gflops衡量的前向传递复杂度来分析扩散 Transformer (DiT) 的可扩展性。
而后者flow matching同样也是来自22年,由Meta AI以及魏茨曼科学研究所的科学家完成。

他们提出了基于连续归一化流(CNFs)的生成模型新范式,以及flow matching的概念,这是一种基于回归固定条件概率路径的矢量场的免模拟CNFs的方法。结果发现使用带有扩散路径的flow matching,可以训练出来的模型更稳健和稳定。
不过最近看了这么多视频生成进展,也有网友表示:

你觉得呢?
One More Thing
除此之外,也就在前一天,他们的视频产品Stable Video正式开放公测。
基于SVD1.1(Stable Video Diffusion 1.1),人人可用。
主要支持文生视频和图生视频两个功能。

参考链接:
[1]https://stability.ai/news/stable-diffusion-3
[2]https://arxiv.org/abs/2212.09748
[3]https://arxiv.org/abs/2210.02747
[4]https://twitter.com/pabloaumente/status/1760678508173660543
Stable Diffusion 3,它终于来了!

足足酝酿一年之多,相比上一代一共进化了三大能力。
来,直接上效果!
首先,是开挂的文字渲染能力。
且看这黑板上的粉笔字:
Go Big or Go Home (不成功便成仁),这个倒是杀气腾腾啊~
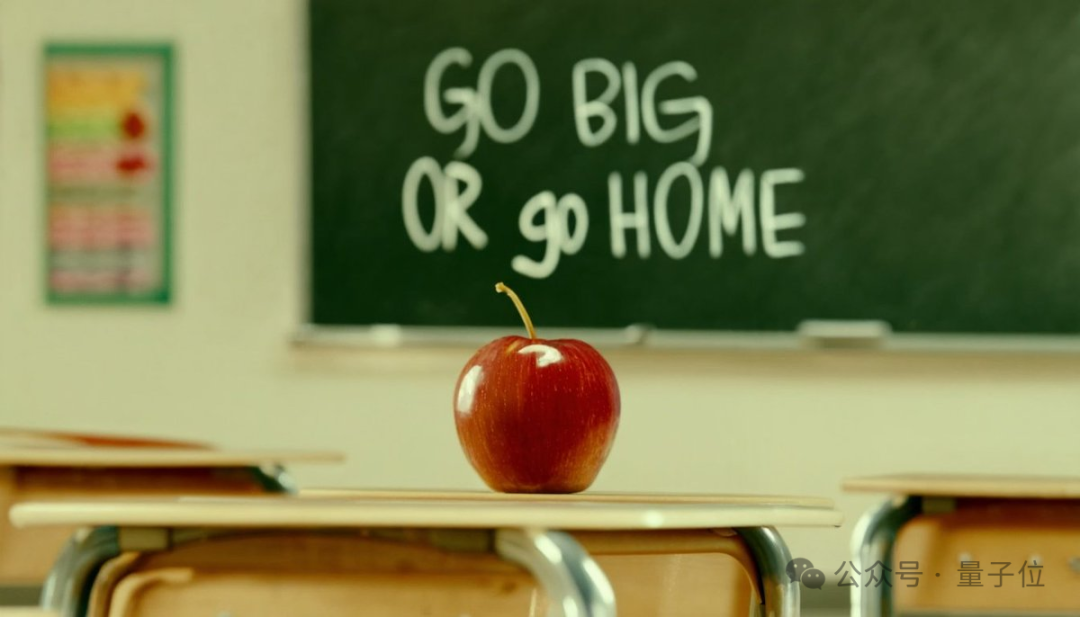
路牌、公交灯牌的霓虹效果:

还有刺绣上“勾”得快要看到针脚的“晚安”:

作品一摆出,网友就大呼:太精确了。

以至于有人表示:赶紧把中文也安排上啊。

其次,多主题提示能力直接拉满。
什么意思?你尽管一次性往提示词中塞入n多“元素”,Stable Diffusion 3:漏一个算我输。
呐,仔细瞅下图,这里面就有“宇航员”、“穿着芭蕾舞裙的小猪”、“粉色雨伞”、“戴着礼帽的知更鸟”,角落里还有“Stable Diffusion”几个大字(可不是什么水印)。

有了这个能力,一幅作品你想多丰富就有多丰富。
最后,当属图像质量,再次进化了一个度。
光看前面这些图,就被冲击到有没有?!
而各种超清特写,那是再信手拈来不过的了。

心动吗?目前官方已开放排队名单,大伙可以前往官网申请。
咳咳,也不得不说,最近这AI圈可真是相当热闹啊。
有网友直呼,我的电脑已经Hold不住了……
Stable Diffusion 3来了!
全新的Stable Diffusion效果有多好,再给大伙奉送一些。
当然,所有出图均来自官方,比如StabilityAI媒体负责人:
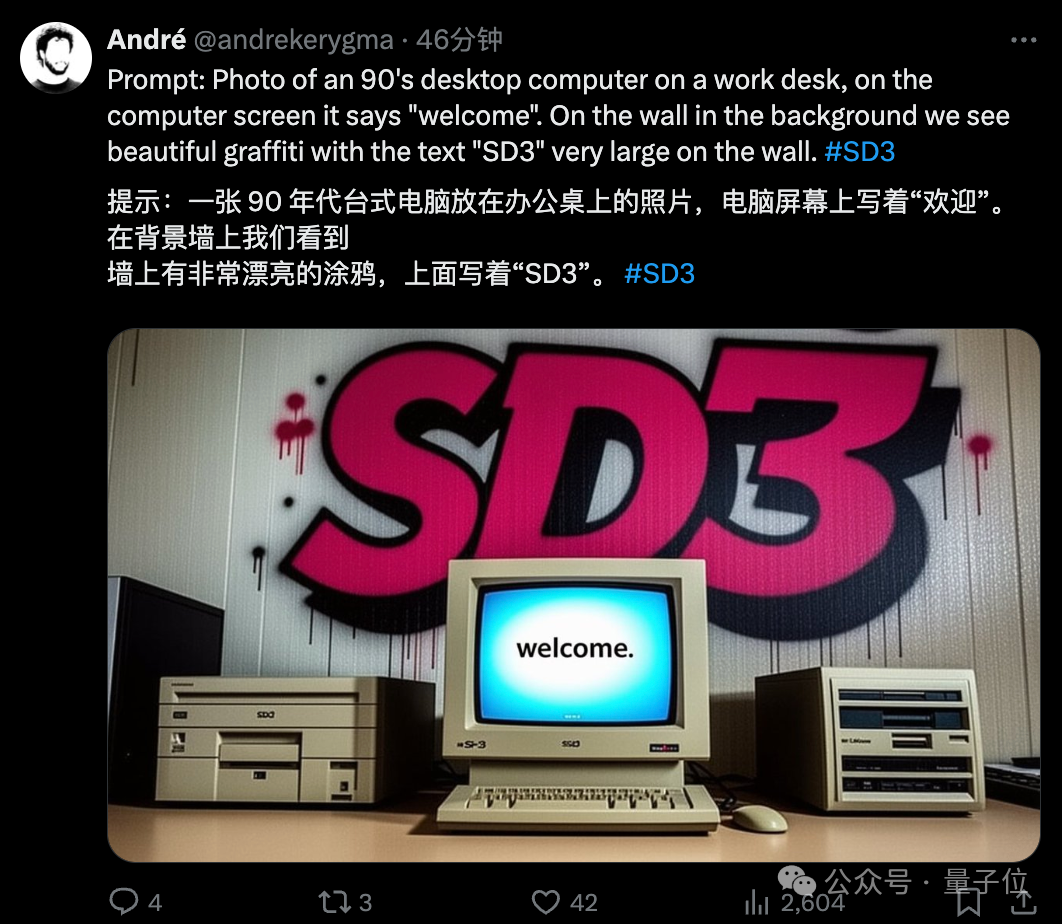
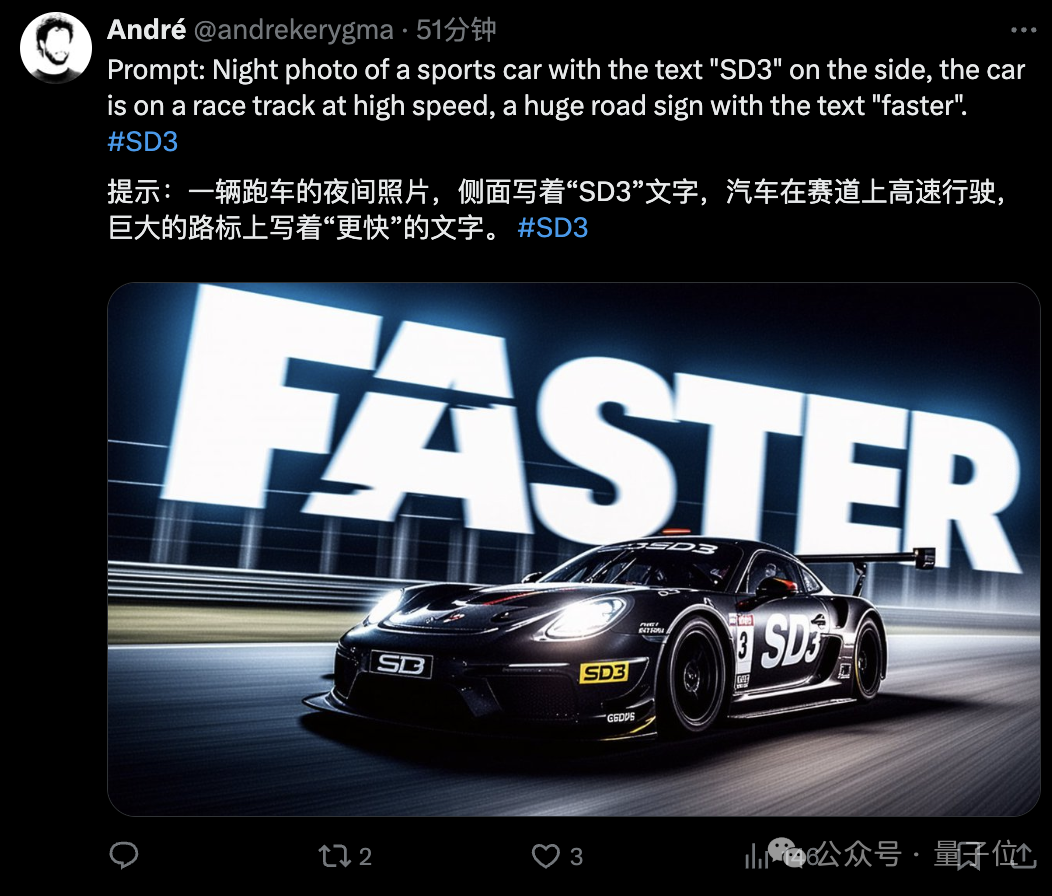
不得不说,文字效果实在最为吸人眼球,各种形式都能呈现得相当清楚和“应景”。

而看到上面这幅图,不得不想到“Midjourney尴尬亮相学术界:为生物学论文乱配图”一事——有了SD3之后,我们是不是可以制作非常专业的学术配图了?
除了这些,SD3的“酒精水墨画”也相当别出心裁:

动漫风格:
again,你可以在上面加清晰的文字了。

由于目前需要排队申请,大伙还不好实际测试摸底。
不过有机智的网友已经用相同的提示词喂给了Midjourney(v 6.0)。
比如开头的那张“红苹果与黑板字”(prompt:cinematic photo of a red apple on a table in a classroom, on the blackboard are the words “go big or go home” written in chalk)
最终Midjourney给出的结果如下:


从这组对比来看,可以说是高下立判——SD3无论是文字拼写还是质量、色彩协调性等方面都更胜一筹。
技术方面,目前,模型可选择的参数范围在800M到8B。
详细的技术报告还未公布,官方目前只透露主要结合了扩散型transformer架构以及flow matching。
前者实际上同Sora一样,附上的技术论文正是22年William Peebles同谢赛宁合写的DiT。

DiT首次将Transformer与扩散模型结合到了一起,相关论文被ICCV 2023录用为Oral论文。
在该研究中,研究者训练了潜在扩散模型,用对潜在 patch进行操作的 Transformer 替换常用的 U-Net 主干网络。他们通过以Gflops衡量的前向传递复杂度来分析扩散 Transformer (DiT) 的可扩展性。
而后者flow matching同样也是来自22年,由Meta AI以及魏茨曼科学研究所的科学家完成。

他们提出了基于连续归一化流(CNFs)的生成模型新范式,以及flow matching的概念,这是一种基于回归固定条件概率路径的矢量场的免模拟CNFs的方法。结果发现使用带有扩散路径的flow matching,可以训练出来的模型更稳健和稳定。
不过最近看了这么多视频生成进展,也有网友表示:

你觉得呢?
One More Thing
除此之外,也就在前一天,他们的视频产品Stable Video正式开放公测。
基于SVD1.1(Stable Video Diffusion 1.1),人人可用。
主要支持文生视频和图生视频两个功能。

参考链接:
[1]https://stability.ai/news/stable-diffusion-3
[2]https://arxiv.org/abs/2212.09748
[3]https://arxiv.org/abs/2210.02747
[4]https://twitter.com/pabloaumente/status/1760678508173660543
Stable Diffusion 3,它终于来了!

足足酝酿一年之多,相比上一代一共进化了三大能力。
来,直接上效果!
首先,是开挂的文字渲染能力。
且看这黑板上的粉笔字:
Go Big or Go Home (不成功便成仁),这个倒是杀气腾腾啊~
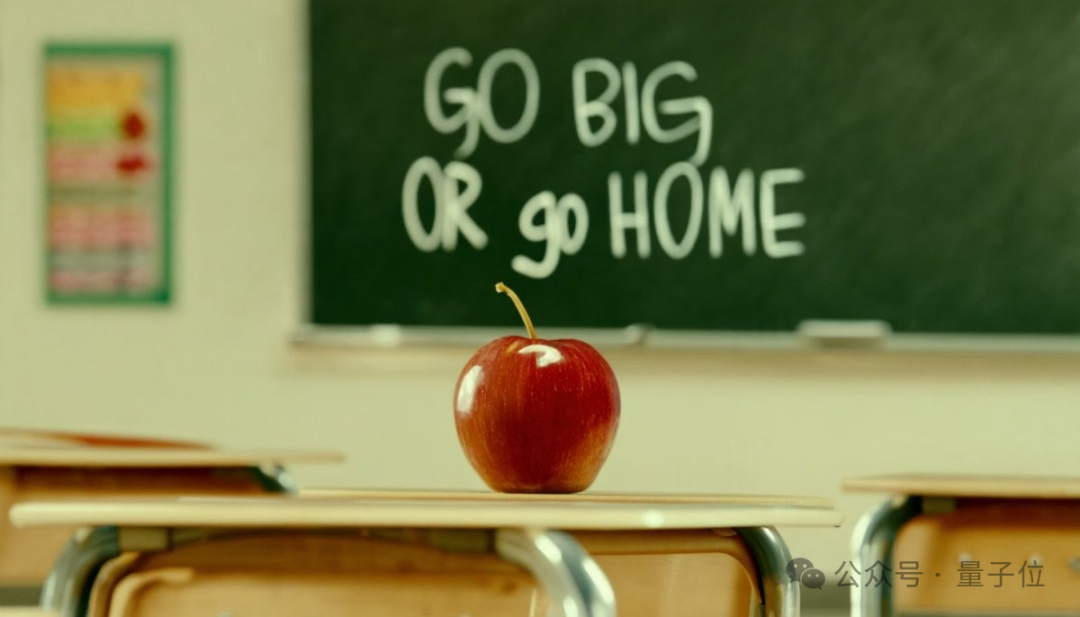
路牌、公交灯牌的霓虹效果:

还有刺绣上“勾”得快要看到针脚的“晚安”:

作品一摆出,网友就大呼:太精确了。

以至于有人表示:赶紧把中文也安排上啊。

其次,多主题提示能力直接拉满。
什么意思?你尽管一次性往提示词中塞入n多“元素”,Stable Diffusion 3:漏一个算我输。
呐,仔细瞅下图,这里面就有“宇航员”、“穿着芭蕾舞裙的小猪”、“粉色雨伞”、“戴着礼帽的知更鸟”,角落里还有“Stable Diffusion”几个大字(可不是什么水印)。

有了这个能力,一幅作品你想多丰富就有多丰富。
最后,当属图像质量,再次进化了一个度。
光看前面这些图,就被冲击到有没有?!
而各种超清特写,那是再信手拈来不过的了。

心动吗?目前官方已开放排队名单,大伙可以前往官网申请。
咳咳,也不得不说,最近这AI圈可真是相当热闹啊。
有网友直呼,我的电脑已经Hold不住了……
Stable Diffusion 3来了!
全新的Stable Diffusion效果有多好,再给大伙奉送一些。
当然,所有出图均来自官方,比如StabilityAI媒体负责人:
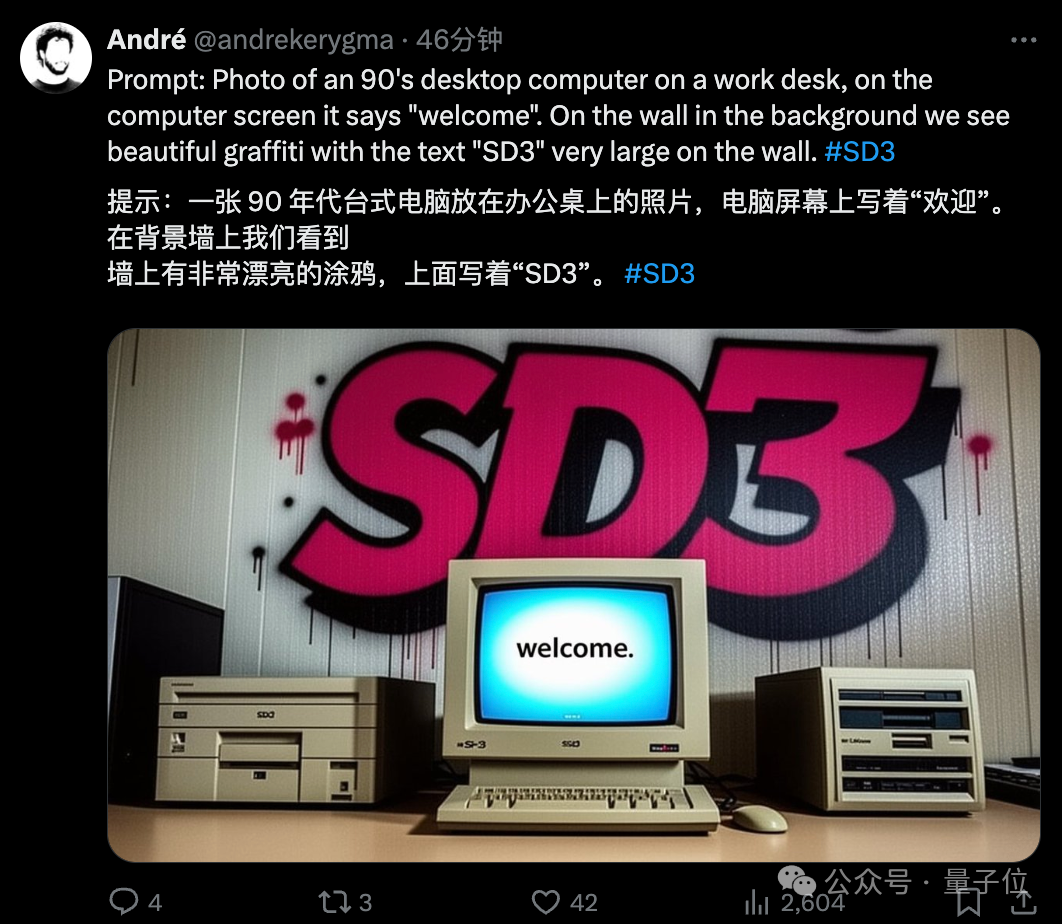
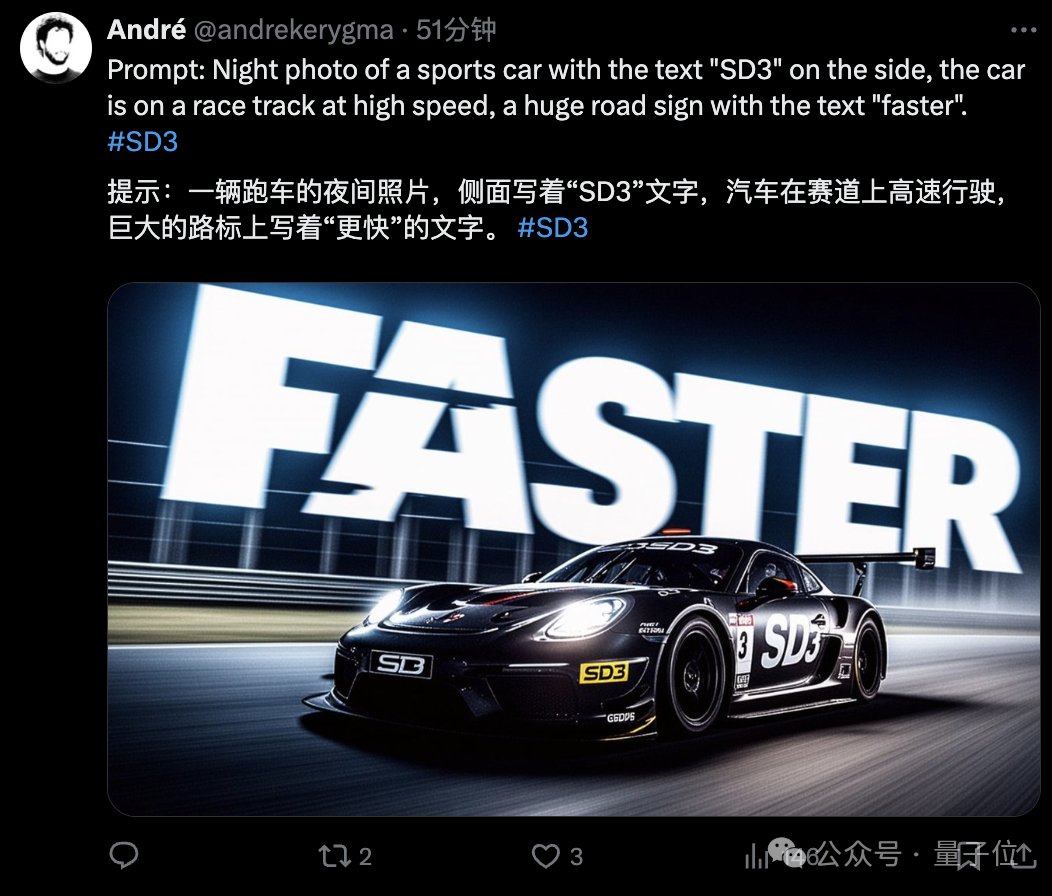
不得不说,文字效果实在最为吸人眼球,各种形式都能呈现得相当清楚和“应景”。

而看到上面这幅图,不得不想到“Midjourney尴尬亮相学术界:为生物学论文乱配图”一事——有了SD3之后,我们是不是可以制作非常专业的学术配图了?
除了这些,SD3的“酒精水墨画”也相当别出心裁:

动漫风格:
again,你可以在上面加清晰的文字了。

由于目前需要排队申请,大伙还不好实际测试摸底。
不过有机智的网友已经用相同的提示词喂给了Midjourney(v 6.0)。
比如开头的那张“红苹果与黑板字”(prompt:cinematic photo of a red apple on a table in a classroom, on the blackboard are the words “go big or go home” written in chalk)
最终Midjourney给出的结果如下:


从这组对比来看,可以说是高下立判——SD3无论是文字拼写还是质量、色彩协调性等方面都更胜一筹。
技术方面,目前,模型可选择的参数范围在800M到8B。
详细的技术报告还未公布,官方目前只透露主要结合了扩散型transformer架构以及flow matching。
前者实际上同Sora一样,附上的技术论文正是22年William Peebles同谢赛宁合写的DiT。

DiT首次将Transformer与扩散模型结合到了一起,相关论文被ICCV 2023录用为Oral论文。
在该研究中,研究者训练了潜在扩散模型,用对潜在 patch进行操作的 Transformer 替换常用的 U-Net 主干网络。他们通过以Gflops衡量的前向传递复杂度来分析扩散 Transformer (DiT) 的可扩展性。
而后者flow matching同样也是来自22年,由Meta AI以及魏茨曼科学研究所的科学家完成。

他们提出了基于连续归一化流(CNFs)的生成模型新范式,以及flow matching的概念,这是一种基于回归固定条件概率路径的矢量场的免模拟CNFs的方法。结果发现使用带有扩散路径的flow matching,可以训练出来的模型更稳健和稳定。
不过最近看了这么多视频生成进展,也有网友表示:

你觉得呢?
One More Thing
除此之外,也就在前一天,他们的视频产品Stable Video正式开放公测。
基于SVD1.1(Stable Video Diffusion 1.1),人人可用。
主要支持文生视频和图生视频两个功能。
参考链接:
[1]https://stability.ai/news/stable-diffusion-3
[2]https://arxiv.org/abs/2212.09748
[3]https://arxiv.org/abs/2210.02747
[4]https://twitter.com/pabloaumente/status/1760678508173660543














暂无评论内容