大语言模型的竞争越来越白热化了。
刚刚,OpenAI 的主要竞争对手之一 Anthropic 推出了最新的 Claude 3 大模型,并宣称为广泛的认知任务树立了新的行业基准。
Anthropic 由 OpenAI 前高管创立,投资者包括谷歌、Salesforce、亚马逊、高通等科技巨头,估值超过 150 亿美元。
Claude 3 模型家族包括三种最先进的型号:Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus。Haiku、Sonnet 和 Opus 分别指“俳句、十四行诗、音乐艺术大作”,可见 Anthropic 似乎有很高的艺术追求。
Anthropic 表示,按照顺序 Claude 3 的三个模型性能依次越来越强大,允许用户为其特定应用选择智能、速度和成本的最佳平衡。
Opus 和 Sonnet 现已可在 claude.ai 中使用,而 Claude API 现已在 159 个国家/地区(不包括中国大陆)广泛使用。Haiku 即将推出。

Claude 3模型家族
1.全面超越GPT-4
![]()
Anthropic 从不同的角度介绍了 Claude 3 模型家族的能力。
智能的新标准
Anthropic 表示,Opus 是最智能的模型,在人工智能系统的大多数常见评估基准上都优于同行,包括本科水平专家知识(MMLU)、研究生水平专家推理(GPQA)、基础数学(GSM8K)等。Opus 在复杂任务上表现出接近人类水平的理解力和流畅性。
所有 Claude 3 模型都显示出在分析和预测、细致内容创建、代码生成以及西班牙语、日语和法语等非英语语言对话方面的增强能力。
Claude 3 模型与同行模型在多个性能基准比较中,全面领先 GPT-4、Gemini等模型,成为基准测试中的“最强模型”。

近乎即时的结果
Claude 3 模型可以支持实时客户聊天、自动完成和数据提取任务,这些任务要求响应必须立即且实时。
Haiku是市场上同类智能模型中速度最快且最具成本效益的。它可以在不到三秒的时间内阅读 arXiv 上包含图表和图形的信息和数据密集的研究论文(约 10k 个 token)。发布后,性能预计会进一步提高。
对于绝大多数工作负载,Sonnet 的速度比 Claude 2 和 Claude 2.1 快 2 倍,且智能水平更高。它擅长执行需要快速响应的任务,例如知识检索或销售自动化。Opus 的速度与 Claude 2 和 2.1 相似,但智能水平更高。
强大的视觉能力
Claude 3 具有与其他领先型号相当的复杂视觉功能。他们可以处理各种视觉格式,包括照片、图表、图形和技术图表。Anthropic 表示,特别高兴能为其企业客户提供这种新模式,其中一些客户的知识库高达 50% 以各种格式编码,例如 PDF、流程图或演示幻灯片。
Claude 3模型具有与其他领先模型相媲美的复杂视觉能力。它们可以处理包括照片、图表、图形和技术图示在内的多种视觉格式。在视觉能力测试中,Claude 3模型全面领先GPT-4,但部分能力低于Gemini 1.0 Ultra。
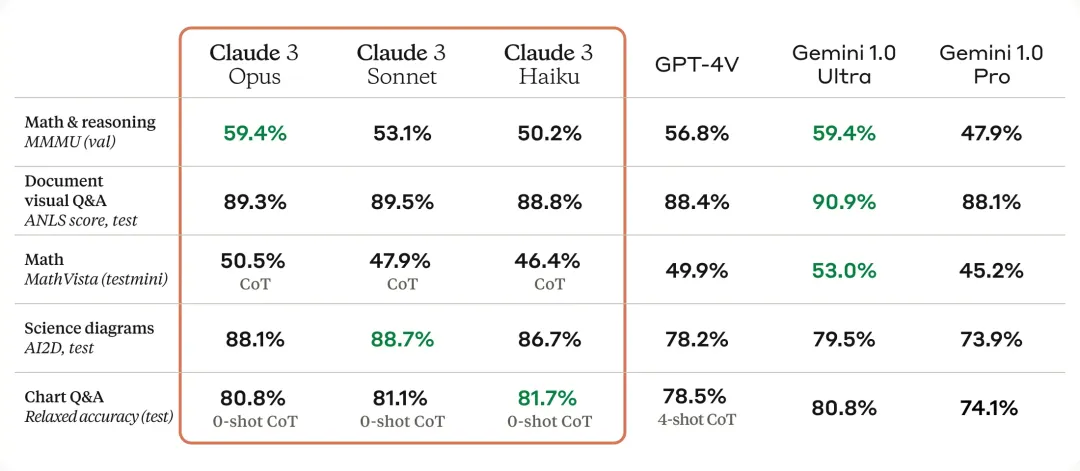
Anthropic表示,特别兴奋地为企业客户提供这种新的模态,其中一些客户的知识点库有高达50%的内容是以PDF、流程图或演示幻灯片等各种格式编码的。
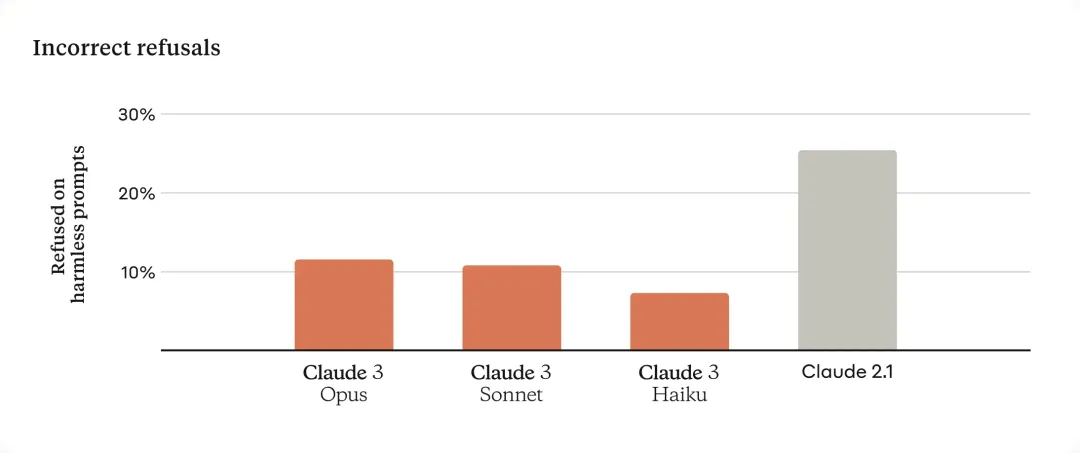
减少拒绝
Claude 过去的模型常常被诟病“过于保守”,经常对用户做出不必要的拒绝。这是模型缺乏语境理解的表现。
随着 Claude 3 的发布,Anthropic 在这一领域取得了有意义的进展:与前几代模型相比,Opus、Sonnet 和 Haiku 拒绝回答接近系统护栏的提示的可能性明显降低。
如下所示,Claude 3 模型对请求表现出更细致的理解,能够识别真正的伤害,并且拒绝回答无害提示的频率要少得多。
提高准确性
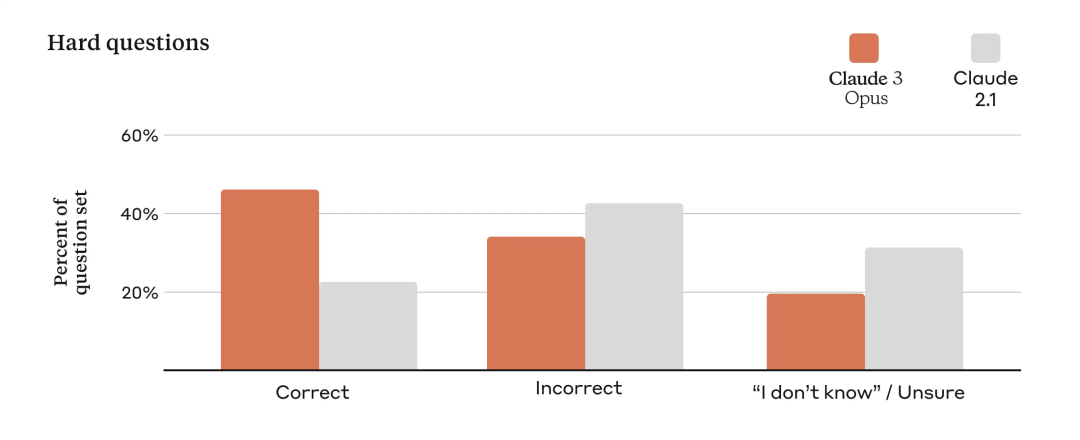
Anthropic 表示,各种规模的企业都依赖其模型来为其客户提供服务,因此模型输出必须保持大规模的高精度。
为了评估这一点,Anthropic 使用了大量复杂的事实问题来针对当前模型中已知的弱点。Anthropic 将答案分为正确答案、错误答案(或幻觉)和承认不确定性,其中模型表示它不知道答案,而不是提供不正确的信息。与 Claude 2.1 相比,Opus 在这些具有挑战性的开放式问题上的准确性(或正确答案)提高了一倍,同时也减少了错误答案的水平。
除了产生更值得信赖的回复之外,Anthropic 表示很快还将在 Claude 3 模型中启用引用功能,以便他们可以指向参考材料中的精确句子来验证他们的答案。
长上下文和近乎完美的回忆
Claude 3 系列型号在发布时最初将提供 200K 上下文窗口。然而,所有三种模型都能够接受超过 100 万个 token 的输入,Anthropic 表示可能会将其提供给需要增强处理能力的精选客户。
为了有效地处理长上下文提示,模型需要强大的记忆能力,“大海捞针”(Needle In A Haystack,简称NIAH)评估衡量了模型从大量数据中准确回忆信息的能力。
Anthropic 通过在每个提示中使用 30 对随机的”针/问题”对之一,并在多样化的众包文档语料库上进行测试,增强了这一基准的稳健性。Claude 3 Opus不仅实现了近乎完美的回忆能力,准确率超过99%,而且在某些情况下,它甚至通过识别出“针”句子似乎是被人为插入到原始文本中的,指出了评估本身的局限性。

负责任的设计
Anthropic 表示,Claude 3 系列型号不仅功能强大,而且值得信赖。
Anthropic 有多个专门的团队负责跟踪和减轻各种风险,这些风险范围广泛,包括错误信息和儿童性虐待材料(CSAM)、生物滥用、选举干预和自主复制技能。Anthropic 表示继续开发诸如宪法人工智能(Constitutional AI)等方法,以提高模型的安全性和透明度,并调整模型以减轻新模态可能引发的隐私问题。
解决日益复杂的模型中的偏见是一个持续的努力,Anthropic 在这个新版本中取得了进展。正如模型卡片所示,根据问题回答偏见基准(Bias Benchmark for Question Answering,简称BBQ),Claude 3表现出的偏见比之前的模型要少。Anthropic 致力于推进减少偏见和促进模型更大中立性的技术,确保它们不会偏向任何特定的党派立场。
虽然 Claude 3模型系列在生物知识、网络相关知识和自主性等关键指标上比之前的模型有所进步,但根据Anthropic的负责任扩展政策,它仍然处于人工智能安全等级2(AI Safety Level 2,简称ASL-2)。Anthropic 的红队评估(根据Anthropic对白宫的承诺和2023年美国行政命令进行)得出结论,这些模型目前对灾难性风险的潜在可能性微不足道。Anthropic 表示将继续仔细监控未来的模型,以评估它们接近ASL-3阈值的程度。

更容易使用
Claude 3模型更擅长遵循复杂的多步骤指令。它们特别擅长遵守品牌语调和响应指南,并开发用户可以信赖的客户面向体验。此外,Claude 3模型在生成流行的结构化输出方面做得更好,如JSON格式——这使得指导Claude进行自然语言分类和情感分析等用例变得更简单。
2.如何使用?成本如何?
![]()
Claude 3 Opus 是 Anthropic 最智能的模型,在高度复杂的任务上具有市场最佳的性能。它可以以惊人的流畅性和类似人类的理解能力来导航开放式提示和看不见的场景。
Claude 3 Sonnet在智能和速度之间实现了理想的平衡,特别是对于企业工作负载。与同类产品相比,它以更低的成本提供强大的性能,并且专为大规模人工智能部署中的高耐用性而设计。
Claude 3 Haiku是最快、最紧凑的模型,具有近乎即时的响应能力。它以无与伦比的速度回答简单的查询和请求。用户将能够构建模仿人类交互的无缝人工智能体验。

表格由KimiChat生成
Opus 和 Sonnet 现在可以在 Anthropic 的 API 中使用。该 API 现已普遍可用,使开发人员能够立即注册并开始使用这些模型。Haiku 即将推出,Sonnet 正在为 claude.ai 提供免费体验,Opus 可供 Claude Pro 订阅者使用。
Sonnet 现已通过 Amazon Bedrock 提供,并在 Google Cloud 的 Vertex AI Model Garden 上提供私人预览版,Opus 和 Haiku 也即将推出。
Anthropic 认为,模型智能还没有达到极限,并计划在未来几个月内频繁发布 Claude 3 模型系列的更新。Anthropic还会发布一系列功能来增强模型的功能,特别是对于企业用例和大规模部署。这些新功能将包括工具使用(又名函数调用)、交互式编码(又名 REPL)和更高级的代理功能。
当突破人工智能能力的界限时,Anthropic 同样致力于确保安全护栏跟上这些性能飞跃的步伐。Anthropic 的假设是,处于人工智能发展的前沿是引导其走向积极社会成果的最有效方式。














暂无评论内容