作者:吕阿华
链接:https://www.zhihu.com/question/649128048/answer/3438781301
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
论文1:《Evaluating RAG Applications with RAGAs》
简介
第一篇文章介绍了一个用于评估RAG应用的框架,称为RAGAs(Retrieval-Augmented Generation Assessment),这篇文章详细介绍了RAGAS框架,它的核心目标是提供一套综合性的评估指标和方法,以量化地评估RAG管道(RAG Pipeline)在不同组件层面上的性能。RAGAs特别适用于那些结合了检索(Retrieval)和生成(Generation)两个主要组件的RAG系统。
评估体系(原文Evaluation Metrics部分)
文章Evaluation Metrics部分介绍了RAGAs的评估体系:
无参考评估:RAGAs最初设计为一种“无参考”评估框架,意味着它不依赖于人工注释的真实标签,而是利用大型语言模型(LLM)进行评估。
组件级评估:RAGAs允许对RAG管道的两个主要组件——检索器和生成器——分别进行评估。这种分离评估方法有助于精确地识别管道中的性能瓶颈。


检索器和生成器的性能表
综合性评估指标:RAGAs提供了一系列评估指标,包括上下文精度(Context Precision)、上下文召回(Context Recall)、忠实度(Faithfulness)和答案相关性(Answer Relevancy)。这些指标共同构成了RAGAs评分,用于全面评估RAG管道的性能。
评估流程(原文Evaluating a RAG Application with RAGAs部分)
RAGAs的评估流程在文中有比较详细的描述,在此只摘抄关键字。
- 开始:启动准备和设置RAG应用的过程。
- 数据准备:加载和分块处理文档。
- 设置向量数据库:生成向量嵌入并存储在向量数据库中。
- 设置检索器组件:基于向量数据库设置检索器。
- 组合RAG管道:结合检索器、提示模板和LLM组成RAG管道。
- 准备评估数据:准备问题和对应的真实答案。
- 构建数据集:通过推理准备数据并构建用于评估的数据集。
- 评估RAG应用:导入评估指标并对RAG应用进行评估。
- 结束:完成评估过程。
整个流程如下图所示:

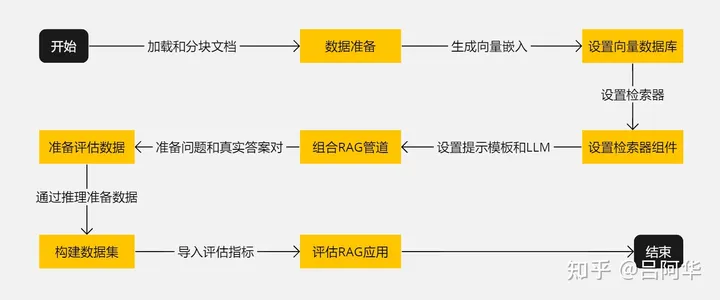
RAGAs评估流程
尽管构建一个概念验证(Proof-of-Concept)的RAG应用相对容易,但要使其性能达到生产就绪状态却非常困难。在拥有评估RAG应用性能的工具的基础上,读者们可以建立一个实验管道,并开始使用各种调优策略来调整性能。
原文地址
论文2:《Evaluating Verifiability in Generative Search Engines》
简介
这篇论文研究了生成式搜索引擎在应对用户查询时,其回应的可验证性(Verifiability)。一个值得信赖的生成式搜索引擎应具备高度的可验证性,即系统应全面(高引用召回率(Citation Recall),所有陈述都有充分引用支持)且准确(高引用精确度(Citation Precision),每个引用都支持其相关陈述)地引用资料。研究通过人类评估对四个流行的生成式搜索引擎 —— Bing Chat、NeevaAI、perplexity.ai 和 YouChat —— 在各种查询中的表现进行了审查。研究发现,尽管这些引擎的回应流畅且看似信息丰富,但经常包含未经支持的陈述和不准确的引用:平均而言,只有51.5%的生成句子得到了引用的完全支持,而仅有74.5%的引用支持其关联的句子。
可验证性评估方法
文中第2节Human Evaluation of Fluency, Perceived Utility, and Verifiability中介绍了4个评估可验证性的维度和方法,分别是流畅性(Fluency)、感知效用(Perceived Utility)、引用召回率和引用精确度。
流畅性的测量方法是通过让评估者对生成回应的流畅性和连贯性进行评分来测量。评估者需要考虑文本的语法正确性和整体的连贯性。然后让评估者使用五点Likert量表(从“强烈不同意”到“强烈同意”)对生成回应的流畅性和连贯性做出评价。
感知效用的测量方法是让评估者根据生成回应是否有助于回答用户的问题,对其有用性进行评价。同样采用五点Likert量表。
引用召回率的测量会首先识别出回应中需要验证的陈述,然后判断对每个陈述,确定是否有引用支持,并评估这些引用是否充分支撑了陈述的内容。
引用精确度的测量会让评估者对每个陈述判断其关联引用提供了多少支持(零/部分/全部),其中对于有多个引用的陈述,评估者还需判断这些引用的综合是否为陈述提供了完全支持。然后根据引用对陈述的支持程度计算引用的精确度。
文中还定义了一个可验证性的综合指标Citation F1,该指标值越大,系统的可验证性越高。
Citation F1 = 引用精确度引用召回率(引用精确度引用召回率)2×引用精确度×引用召回率÷(引用精确度+引用召回率)2\times 引用精确度 \times 引用召回率\div (引用精确度 + 引用召回率)
论文的第4节Results and Analysis部分还列出了前面提到的4个生成式搜索引擎不同维度的评估结果,这里不费篇幅介绍,有兴趣的读者请移步原文了解详情。
原文地址
《Evaluating Verifiability in Generative Search Engines》arxiv.org/pdf/2304.09848.pdf
相关阅读
吕阿华:学习检索增强生成(RAG)技术,看这篇就够了——热门RAG文章摘译(9篇)84 赞同 · 7 评论文章
发布于 2024-03-21 19:39・IP 属地浙江
赞同 3添加评论
分享
收藏喜欢收起
更多回答

大连理工大学 计算机科学与技术硕士
关注
谢邀@骑猪兜风
刚好,我这边也在研究关于 RAG 系统的评估,除了 RAGAS 之外,还可以使用 llama-index 里面提到的几种评测方法。但是这些方法,本质上还是 LLM+提示词工程去评价系统的好坏,并不是很稳定。
以 Llama index 提供的几种方法作为示例:
Evaluation – LlamaIndex v0.10.19


Correctness :就是评价生成的答案和参考答案的正确性,最后会输出对于的得分,以及评价结果。
Faithfulness:评价回答的问题是否可以匹配到召回的数据源,也就是所谓的忠诚度。用于评价,最后输出的内容是否含有幻觉的成分。
Guideline:用于评价回答是否满足用户给出的特定要求(指导信息)。
Pairwise:用于评价两个不同 query 检索方案生成的答案,哪一个更好。注意,这两个 query engine 可以是相同结构、也可以不同。但用于检索的 query 必须一样才有对比的价值。
Relevancy:衡量答案和检索出的上下文信息与用户 query 的相关性。
Semantic similarity: 衡量答案和标准答案的语义相似度得分,这个计算默认是使用的余弦相似度。
除此之外,还可以使用 DeepEval 和 llama-index 进行结合,基本评测的方法都比较类似,就不在重复介绍了,感兴趣的可以去看官网。
https://github.com/confident-ai/deepeval


当然,我这边也写过几篇和 RAGAS 相关的文章,分别是使用本地模型和API 调用去进行实际的系统评估,感兴趣的可以看一下原文,也可以和我一起交流。欢迎,点赞收藏转发一键三连。
赞同添加评论
分享
收藏喜欢收起


京东科技信息技术有限公司 算法工程师
关注
3 人赞同了该回答
目录
收起
评估指标
评估动作
评估工具
参考资料
RAG类应用是当前大模型落地走得最快的方向之一,如何量化评估RAG系统性能是迭代优化的重要基础。和常规AI算法系统一样,我们需明确两个问题:评估指标如何定义?评估数据集构造与评估动作执行[4]。
评估指标
1)没有ground-truth的评估
基于RAG三元组,具体是(query, context, response)。
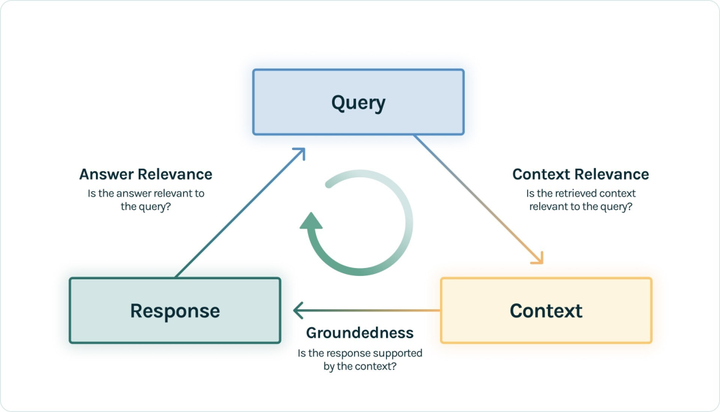

可基于三元组中两两元素的相关度来评估RAG应用的效果。如下做个简单说明:
- context relevance:召回context支持query的程度。
- groundedness:response遵从召回context的程度。
- Answer relevance:response对query提问的相关度。
如何计算这三个得分,有多种方法。常见的是基于最新的GPT-4作为裁判,给每一对元组打分计算相似度。在一些工具中,可能对上述三个指标会进一步细分,如:Ragas中将context relevance细分为:context precision,context relevancy,context recall[1]。
2)具有ground-truth的评估
可以直接计算RAG应用回答和ground truth之间的相关性。Ragas中相应指标有:answer semantic similarity和answer correctness。
如果ground-truth是知识文档中的chunks,即数据集中有query提问和对应文档内容中的ground-truth doc chunks。这种情况只需计算context relevance即可,即ground-truth doc chunks和召回chunks之间的相关性。其本质是评估RAG应用的召回效果。
针对特定文档,如何生成评估数据集? 可以让LLM根据知识文档,来自动生成query, ground-truth(一般也会生成context)。比如: Ragas中的Synthetic Test Data Generation和LlamaIndex中的QuestionGeneration。
3)针对LLM应答的指标
这类指标是针对LLM应答而言的,比如:是否有害、是否友好、是否简洁等。比如LangChain中的Criteria Evaluation[2],Ragas中的Aspect Critique等。
评估动作
上述指标计算需要用若干文字表述,但现在可通过prompt的方式进行管理。比如:设计好一个prompt模板,把具体内容放进去,然后和GPT-4交互,即可得到评分结果。如:LLM-as-a-Judge论文中就有相应的模板样例[3]。但要注意在prompt设计时,要用到few-shot、cot、避免位置偏见等技术。
评估工具
Ragas:专注评估RAG应用的工具,对框架无要求。
LlamaIndex:它可以构建RAG应用,也有一部分评估功能,可对本身搭建的RAG应用进行评估。
Trulens-Eval:可对LangChain和LlamaIndex搭建的RAG应用进行评估。
Phoenix:可以评估embedding效果,可以评估LLM本身。
其他:DeepEval、LangSmith、OpenAI Evals。
参考资料
- https://docs.ragas.io/en/latest/concepts/metrics/index.html
- https://python.langchain.com/docs/guides/evaluation/string/criteria_eval_chain
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
- 如何评估 RAG 应用的质量?最典型的方法论和评估工具都在这里了
作者:吕阿华
链接:https://www.zhihu.com/question/649128048/answer/3438781301
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
论文1:《Evaluating RAG Applications with RAGAs》
简介
第一篇文章介绍了一个用于评估RAG应用的框架,称为RAGAs(Retrieval-Augmented Generation Assessment),这篇文章详细介绍了RAGAS框架,它的核心目标是提供一套综合性的评估指标和方法,以量化地评估RAG管道(RAG Pipeline)在不同组件层面上的性能。RAGAs特别适用于那些结合了检索(Retrieval)和生成(Generation)两个主要组件的RAG系统。
评估体系(原文Evaluation Metrics部分)
文章Evaluation Metrics部分介绍了RAGAs的评估体系:
无参考评估:RAGAs最初设计为一种“无参考”评估框架,意味着它不依赖于人工注释的真实标签,而是利用大型语言模型(LLM)进行评估。
组件级评估:RAGAs允许对RAG管道的两个主要组件——检索器和生成器——分别进行评估。这种分离评估方法有助于精确地识别管道中的性能瓶颈。


检索器和生成器的性能表
综合性评估指标:RAGAs提供了一系列评估指标,包括上下文精度(Context Precision)、上下文召回(Context Recall)、忠实度(Faithfulness)和答案相关性(Answer Relevancy)。这些指标共同构成了RAGAs评分,用于全面评估RAG管道的性能。
评估流程(原文Evaluating a RAG Application with RAGAs部分)
RAGAs的评估流程在文中有比较详细的描述,在此只摘抄关键字。
- 开始:启动准备和设置RAG应用的过程。
- 数据准备:加载和分块处理文档。
- 设置向量数据库:生成向量嵌入并存储在向量数据库中。
- 设置检索器组件:基于向量数据库设置检索器。
- 组合RAG管道:结合检索器、提示模板和LLM组成RAG管道。
- 准备评估数据:准备问题和对应的真实答案。
- 构建数据集:通过推理准备数据并构建用于评估的数据集。
- 评估RAG应用:导入评估指标并对RAG应用进行评估。
- 结束:完成评估过程。
整个流程如下图所示:

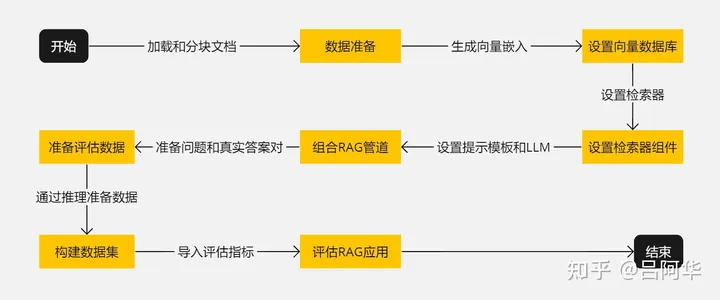
RAGAs评估流程
尽管构建一个概念验证(Proof-of-Concept)的RAG应用相对容易,但要使其性能达到生产就绪状态却非常困难。在拥有评估RAG应用性能的工具的基础上,读者们可以建立一个实验管道,并开始使用各种调优策略来调整性能。
原文地址
论文2:《Evaluating Verifiability in Generative Search Engines》
简介
这篇论文研究了生成式搜索引擎在应对用户查询时,其回应的可验证性(Verifiability)。一个值得信赖的生成式搜索引擎应具备高度的可验证性,即系统应全面(高引用召回率(Citation Recall),所有陈述都有充分引用支持)且准确(高引用精确度(Citation Precision),每个引用都支持其相关陈述)地引用资料。研究通过人类评估对四个流行的生成式搜索引擎 —— Bing Chat、NeevaAI、perplexity.ai 和 YouChat —— 在各种查询中的表现进行了审查。研究发现,尽管这些引擎的回应流畅且看似信息丰富,但经常包含未经支持的陈述和不准确的引用:平均而言,只有51.5%的生成句子得到了引用的完全支持,而仅有74.5%的引用支持其关联的句子。
可验证性评估方法
文中第2节Human Evaluation of Fluency, Perceived Utility, and Verifiability中介绍了4个评估可验证性的维度和方法,分别是流畅性(Fluency)、感知效用(Perceived Utility)、引用召回率和引用精确度。
流畅性的测量方法是通过让评估者对生成回应的流畅性和连贯性进行评分来测量。评估者需要考虑文本的语法正确性和整体的连贯性。然后让评估者使用五点Likert量表(从“强烈不同意”到“强烈同意”)对生成回应的流畅性和连贯性做出评价。
感知效用的测量方法是让评估者根据生成回应是否有助于回答用户的问题,对其有用性进行评价。同样采用五点Likert量表。
引用召回率的测量会首先识别出回应中需要验证的陈述,然后判断对每个陈述,确定是否有引用支持,并评估这些引用是否充分支撑了陈述的内容。
引用精确度的测量会让评估者对每个陈述判断其关联引用提供了多少支持(零/部分/全部),其中对于有多个引用的陈述,评估者还需判断这些引用的综合是否为陈述提供了完全支持。然后根据引用对陈述的支持程度计算引用的精确度。
文中还定义了一个可验证性的综合指标Citation F1,该指标值越大,系统的可验证性越高。
Citation F1 = 引用精确度引用召回率(引用精确度引用召回率)2×引用精确度×引用召回率÷(引用精确度+引用召回率)2\times 引用精确度 \times 引用召回率\div (引用精确度 + 引用召回率)
论文的第4节Results and Analysis部分还列出了前面提到的4个生成式搜索引擎不同维度的评估结果,这里不费篇幅介绍,有兴趣的读者请移步原文了解详情。
原文地址
《Evaluating Verifiability in Generative Search Engines》arxiv.org/pdf/2304.09848.pdf
相关阅读
吕阿华:学习检索增强生成(RAG)技术,看这篇就够了——热门RAG文章摘译(9篇)84 赞同 · 7 评论文章
发布于 2024-03-21 19:39・IP 属地浙江
赞同 3添加评论
分享
收藏喜欢收起
更多回答

大连理工大学 计算机科学与技术硕士
关注
谢邀@骑猪兜风
刚好,我这边也在研究关于 RAG 系统的评估,除了 RAGAS 之外,还可以使用 llama-index 里面提到的几种评测方法。但是这些方法,本质上还是 LLM+提示词工程去评价系统的好坏,并不是很稳定。
以 Llama index 提供的几种方法作为示例:
Evaluation – LlamaIndex v0.10.19


Correctness :就是评价生成的答案和参考答案的正确性,最后会输出对于的得分,以及评价结果。
Faithfulness:评价回答的问题是否可以匹配到召回的数据源,也就是所谓的忠诚度。用于评价,最后输出的内容是否含有幻觉的成分。
Guideline:用于评价回答是否满足用户给出的特定要求(指导信息)。
Pairwise:用于评价两个不同 query 检索方案生成的答案,哪一个更好。注意,这两个 query engine 可以是相同结构、也可以不同。但用于检索的 query 必须一样才有对比的价值。
Relevancy:衡量答案和检索出的上下文信息与用户 query 的相关性。
Semantic similarity: 衡量答案和标准答案的语义相似度得分,这个计算默认是使用的余弦相似度。
除此之外,还可以使用 DeepEval 和 llama-index 进行结合,基本评测的方法都比较类似,就不在重复介绍了,感兴趣的可以去看官网。
https://github.com/confident-ai/deepeval


当然,我这边也写过几篇和 RAGAS 相关的文章,分别是使用本地模型和API 调用去进行实际的系统评估,感兴趣的可以看一下原文,也可以和我一起交流。欢迎,点赞收藏转发一键三连。
赞同添加评论
分享
收藏喜欢收起


京东科技信息技术有限公司 算法工程师
关注
3 人赞同了该回答
目录
收起
评估指标
评估动作
评估工具
参考资料
RAG类应用是当前大模型落地走得最快的方向之一,如何量化评估RAG系统性能是迭代优化的重要基础。和常规AI算法系统一样,我们需明确两个问题:评估指标如何定义?评估数据集构造与评估动作执行[4]。
评估指标
1)没有ground-truth的评估
基于RAG三元组,具体是(query, context, response)。
可基于三元组中两两元素的相关度来评估RAG应用的效果。如下做个简单说明:
- context relevance:召回context支持query的程度。
- groundedness:response遵从召回context的程度。
- Answer relevance:response对query提问的相关度。
如何计算这三个得分,有多种方法。常见的是基于最新的GPT-4作为裁判,给每一对元组打分计算相似度。在一些工具中,可能对上述三个指标会进一步细分,如:Ragas中将context relevance细分为:context precision,context relevancy,context recall[1]。
2)具有ground-truth的评估
可以直接计算RAG应用回答和ground truth之间的相关性。Ragas中相应指标有:answer semantic similarity和answer correctness。
如果ground-truth是知识文档中的chunks,即数据集中有query提问和对应文档内容中的ground-truth doc chunks。这种情况只需计算context relevance即可,即ground-truth doc chunks和召回chunks之间的相关性。其本质是评估RAG应用的召回效果。
针对特定文档,如何生成评估数据集? 可以让LLM根据知识文档,来自动生成query, ground-truth(一般也会生成context)。比如: Ragas中的Synthetic Test Data Generation和LlamaIndex中的QuestionGeneration。
3)针对LLM应答的指标
这类指标是针对LLM应答而言的,比如:是否有害、是否友好、是否简洁等。比如LangChain中的Criteria Evaluation[2],Ragas中的Aspect Critique等。
评估动作
上述指标计算需要用若干文字表述,但现在可通过prompt的方式进行管理。比如:设计好一个prompt模板,把具体内容放进去,然后和GPT-4交互,即可得到评分结果。如:LLM-as-a-Judge论文中就有相应的模板样例[3]。但要注意在prompt设计时,要用到few-shot、cot、避免位置偏见等技术。
评估工具
Ragas:专注评估RAG应用的工具,对框架无要求。
LlamaIndex:它可以构建RAG应用,也有一部分评估功能,可对本身搭建的RAG应用进行评估。
Trulens-Eval:可对LangChain和LlamaIndex搭建的RAG应用进行评估。
Phoenix:可以评估embedding效果,可以评估LLM本身。
其他:DeepEval、LangSmith、OpenAI Evals。














暂无评论内容