
分布式训练topic由以下几部分组成:
微软一共发布了4篇论文:
ZeRO: Memory optimizations Toward Training Trillion Parameter Models 2019/10 microsoft
提出了ZeRO-DP和 ZeRO-R
ZeRO-Offload: Democratizing Billion-Scale Model Training 2021/01 microsoft
ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning 2021/03 microsoft
ZeRO++: Extremely Efficient Collective Communication for Giant Model Training 2023/06 microsoft
1、ZeRO
1.1 概览
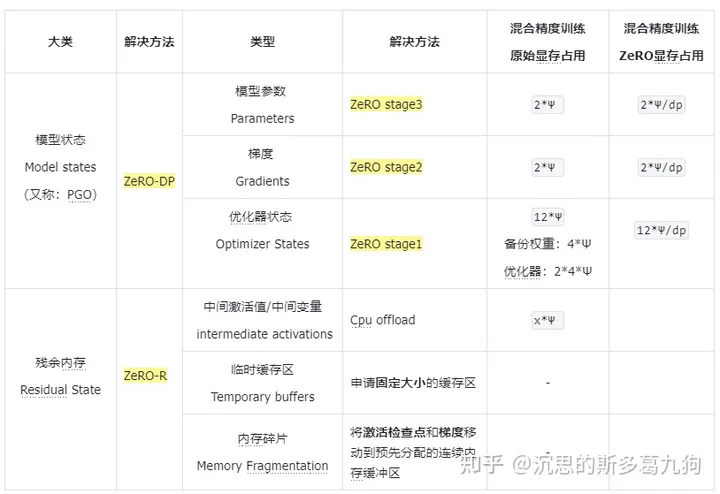
ZeRO有两组优化:
(1)ZeRO-DP:希望减少模型状态PGO的显存占用
(2)ZeRO-R:希望减少剩余显存的消耗。
1.2 ZeRO-DP
目标:数据并行具有较好的通信和计算效率,但显存冗余严重,希望最小化通信量和降低模型状态PGO的显存冗余。
本质:数据并行机制,不同的输入数据data,用完整的参数P进行计算。
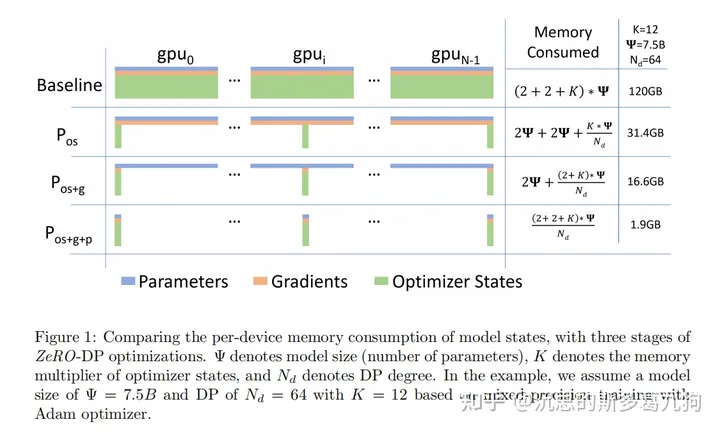
原理:使用动态通信策略来将优化器状态、梯度和参数进行分区。假设数据并行度为Nd,将PGO均匀的分配Nd个相等分区,也就是显存被平均分配到每个GPU之上。
实现:通过对模型参数P进行分区,所以梯度(梯度是参数的成员变量,G = P.grad)也被分区了。分区的参数Pi被初始化到优化器之中(O=AdamW(P)),所以优化器只会优化本分区的参数Pi。
两个原则
- 用完即删
- 需要用时去取
类型:
- ZeRO-Stage 1:Optimizer States
- ZeRO-Stage 2:Optimizer States + Gradients
- ZeRO-Stage 3:Optimizer States + Gradients + Parameters
1.2.1 ZeRO-Stage 1
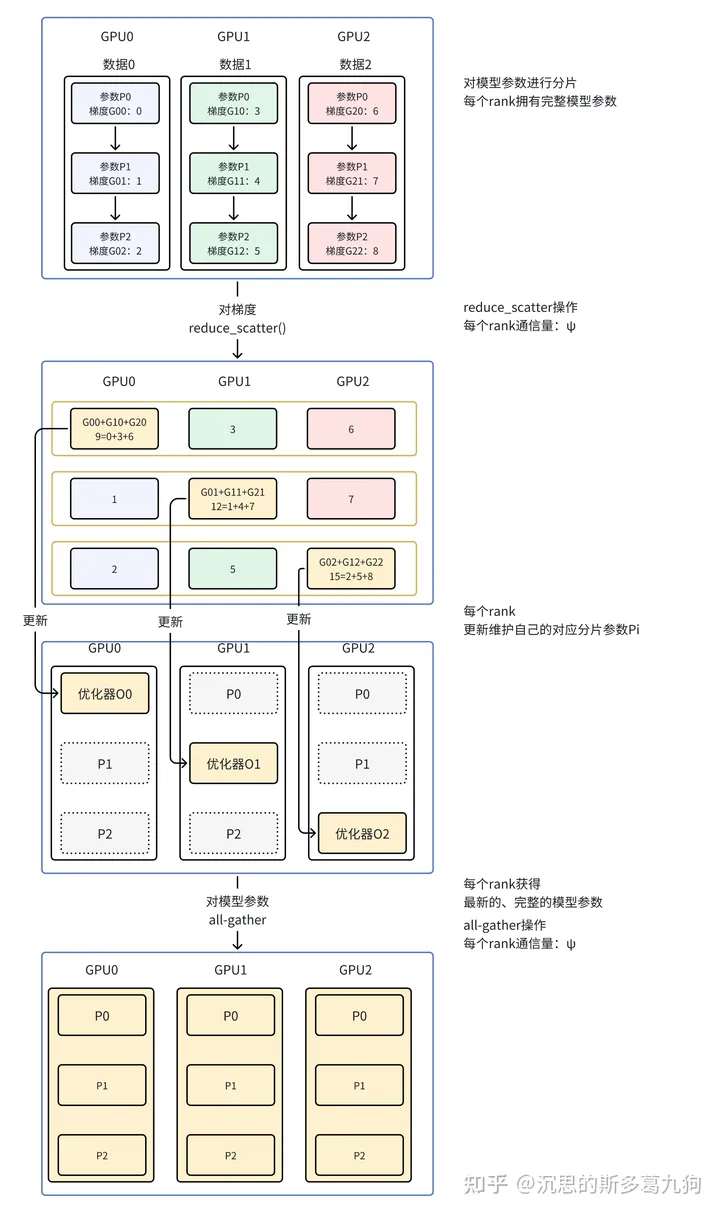
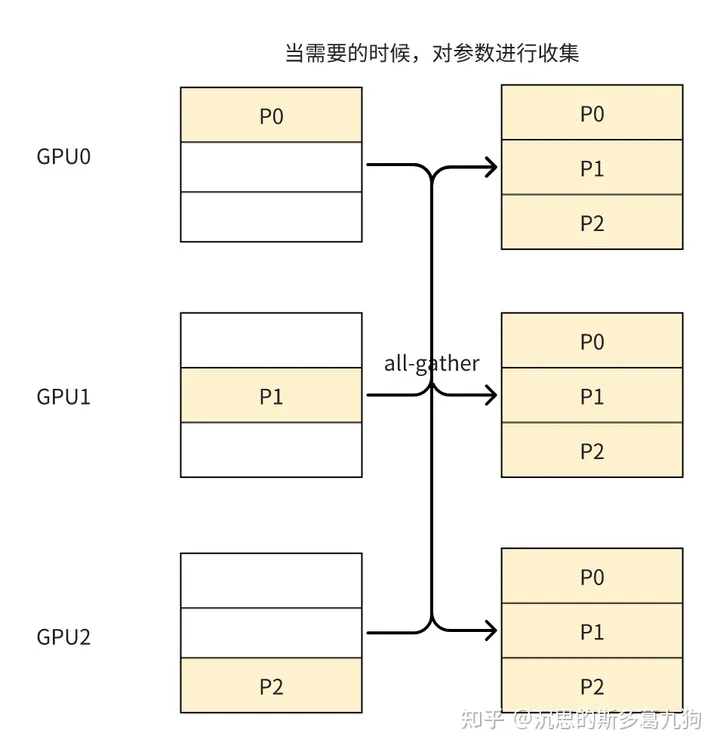
原理:对优化器状态Optimizer States的显存占用进行分区,每个rank占1/N。利用这1/N的Optimizer States更新与之对应的1/N参数Pi之后,再把所有参数收集起来,构成完整的模型。
流程:
- reduce-scatter:获得该分片参数Pi完整的梯度(对各个rank上的梯度进行平均),用于更新各自rank对应的分片参数Pi。
- all-gather:对各个rank上已经更新好的参数Pi进行收集,获得最新的、完整的模型参数P。通信量为ψ。
通信分析:单个GPU总通信量为2*ψ。
- 梯度reduce-scatter操作(通信量ψ )
- 参数all-gather操作(通信量ψ)。
1.2.2 ZeRO-Stage 2
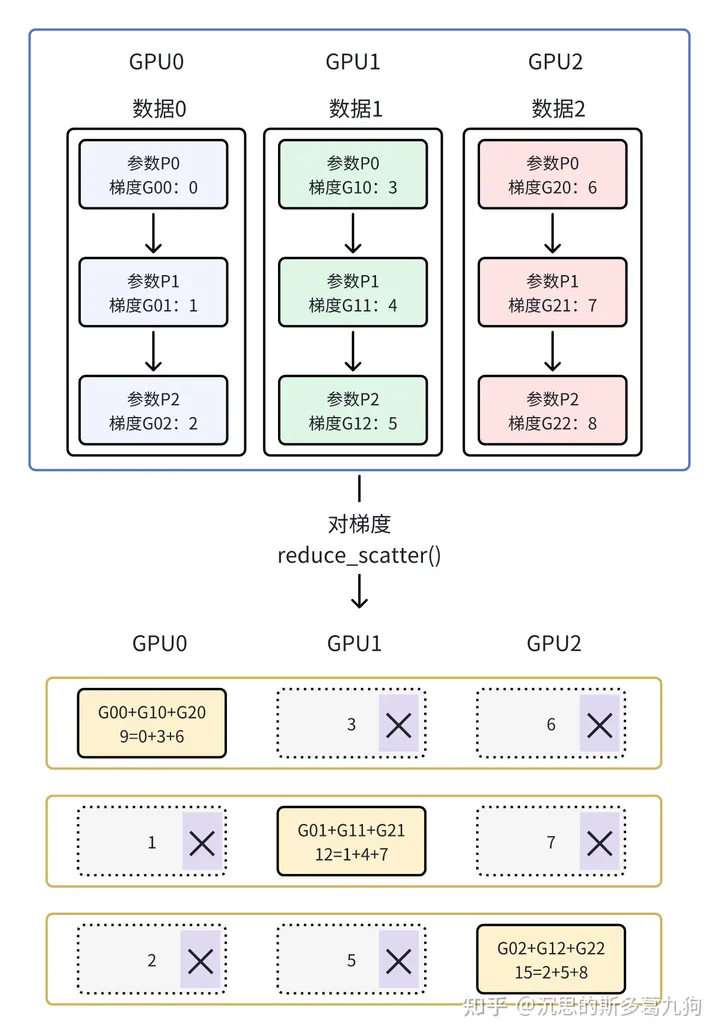
在Stage1的基础上,对梯度Gradients进行分区。
ZeRO-2会分割Optimizer States与Gradients。
用完即删原则:每个rank只对自己负责的那部分参数Pi的梯度进行规约。在规约之后,每个rank只需要自己参数分区对应的梯度G(对应下图黄色的部分),对于其他的梯度不再需要(对应下图打×的部分),所以它们的显存可以被释放。
通信分析:同ZeRO-Stage1,单个GPU总通信量为2*ψ。
1.2.3 ZeRO-Stage 3
在Stage1/Stage2的基础上,对模型参数Parameters进行分区。
ZeRO-3会分割Optimizer States、Gradients和Parameters。
需要用时去取原则:在计算特定layer的时候,对参数进行all-gather,每个rank获得该layer完整的模型参数。
新增通信量ψ:在forward的时候,需要对参数进行all-gather。
通信分析:单个GPU总通信量为3*ψ。
- 梯度reduce-scatter操作(通信量ψ )
- 参数all-gather操作(通信量ψ)。
- 前向传播过程,需要对模型参数进行all-gather操作(通信量ψ)。
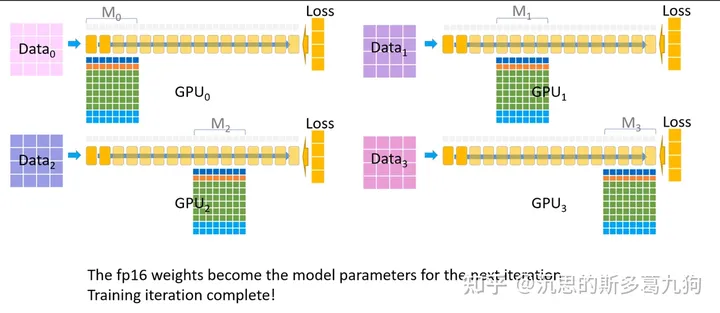
1.2.4 动画视频
The video below shows how ZeRO (with all three stages) performs a training step including forward pass, backward pass, and parameter update.

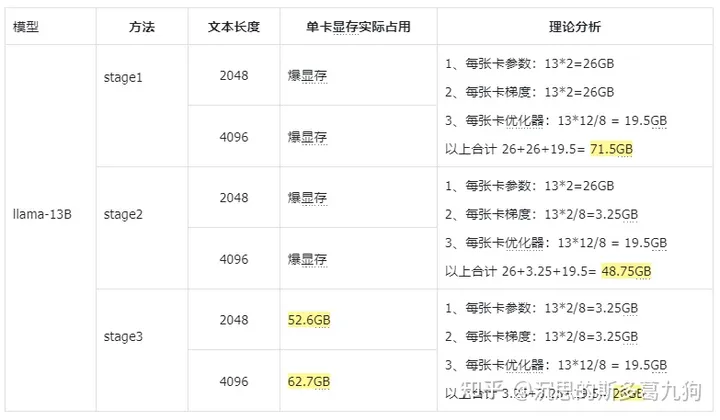
1.2.5 实验效果
实验配置:80G 8*A800 、全参训练,bs=1,checkpointing=True 。
实验结论:全参训练,最多只能跑13B模型,34B模型跑不起来。
1.2.6 ZeRO-DP VS DDP
-
共同点:
- 前向计算和后向计算都是利用完整模型。
-
显存占用:
- DDP:每个GPU上都有一个模型副本,向前和向后传递的序列只在自己的数据上进行运行。
- ZeRO-DP:每个GPU上存的是模型的分片。
-
通信量:
- DDP:单个GPU总通信量为2*Ψ 。对梯度采用基于环的reduce(详情见:LLM训练04 数据并行)。
-
ZeRO-DP:
- Zero Stage1/ Stage2:通信量为2*ψ。
- Zero Stage3:通信量为3*ψ。
1.3 ZeRO-R
1.3.1 中间激活值
认为checkpoint方法虽然有用,但在大型LLM中激活值仍然占用很大的显存。
eg:100B的LLM,bs=32,激活值显存占用60GB。
方法:Offload到CPU中。
1.3.2 临时缓存区
在梯度reduce操作中,用于存储中间结果的临时缓冲区会消耗大量显存。
方法:申请固定大小的缓存区 constant size buffers 。
self.ipg_buffer = []buf_0 = torch.empty(int(self.reduce_bucket_size),
dtype=self.dtype,
device=get_accelerator().current_device_name())self.ipg_buffer.append(buf_0)
1.3.3 内存碎片
原因:内存碎片是tensor生命周期错配的结果,即短生命周期内存对象和长生命周期内存对象交错分配的结果。在checkpoint方法中,会创建短期内存(丢弃的激活)和长期内存(检查点的激活)的交错,导致内存碎片。
问题:即使有足够的显存,可能会因为缺少连续内存而使得内存分配失败。
方法:ZeRO为激活检查点和梯度预先分配连续内存块,并在初始化时将它们复制到预先分配的连续内存中。
2、ZeRO-Offload
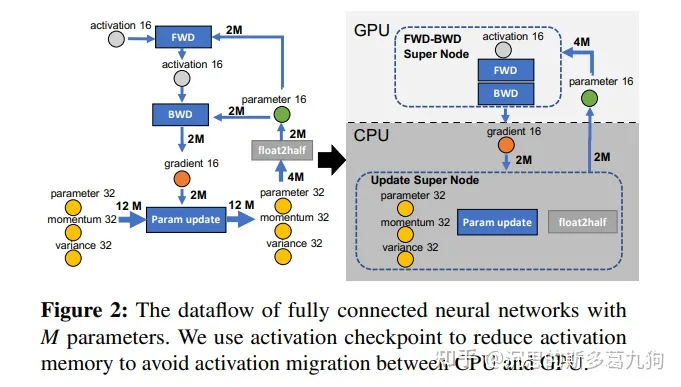
GPU显存不足,利用CPU内存。
CPU:参数更新在CPU完成。在CPU内存中分配所有的fp32模型状态以及fp16梯度。
GPU:前向和后向的计算在GPU上完成。在GPU显存中分配fp16参数。
3、ZeRO-Infinity
GPU显存不足,利用外接存储设备。
4、ZeRO++
to do…
5、Deepspeed ZeRO源码
5.1 入口
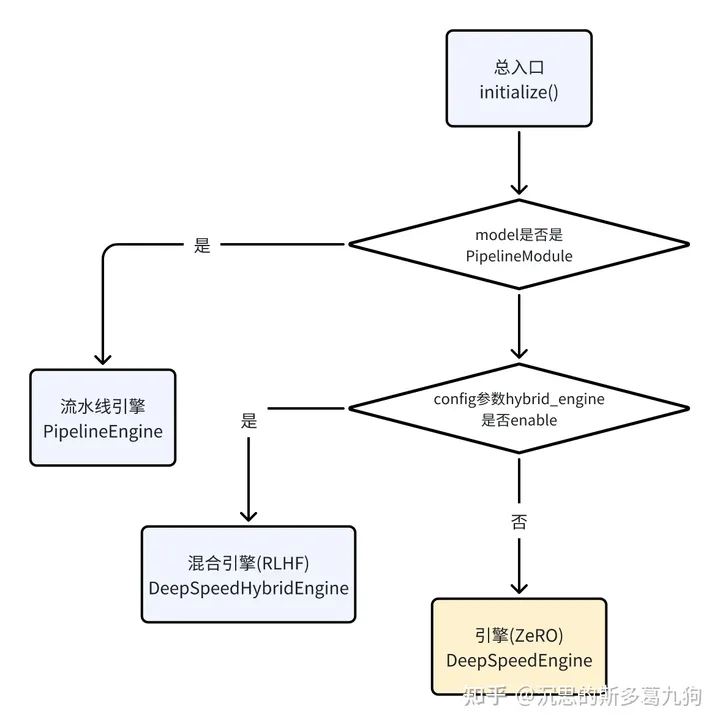
5.1.1 总入口initialize()
源码地址:deepspeed.__init__
简介:选择不同的engin引擎。
5.1.2 ZeRO引擎DeepSpeedEngine
源码地址:deepspeed.runtime.engine
整体流程及关键方法如下所示:
(1)DeepSpeedEngine.init
核心内容::最重要的就是对优化器(Optimizer)的初始化。
ZeRO 的核心特性的实现都在优化器(Optimizer)中,核心方法_configure_zero_optimizer() 。
stage1/2 优化器:DeepSpeedZeroOptimizer
stage3 优化器:DeepSpeedZeRoOffload
(2)DeepSpeedEngine.forward
核心内容:在模型model进行前向传播,返回loss,ZeRO不需要进行特殊处理
(3)DeepSpeedEngine.backward
核心内容:获得各个rank上对应分片参数Pi的梯度Gi。
self.optimizer.backward()
Zero stage1:self.optimizer.reduce_gradients()
Zero stage2:self.overlapping_partition_gradients_reduce_epilogue
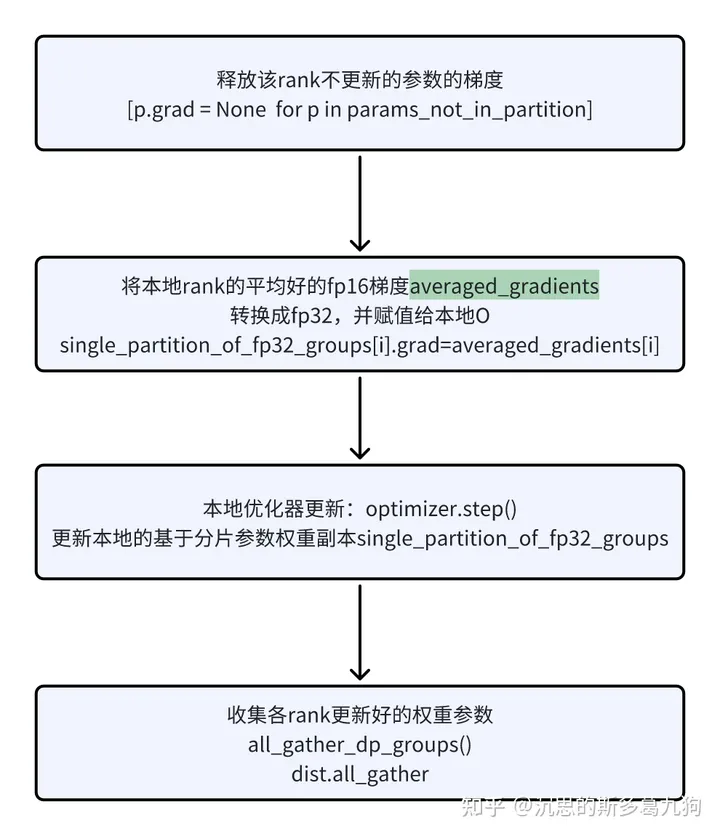
(4)DeepSpeedEngine.step
核心内容:基于梯度Gi更新对应的分片参数Pi,各rank收集最新的、完整的模型参数P
self.optimizer.step()
self.optimizer.zero_grad()
5.2 DeepSpeedZeroOptimizer
源码地址:deepspeed.runtime.zero.stage_1_and_2
简介:stage1/2 优化器,对参数的Optimizer States与Gradients进行分割。
5.2.1 init
核心思路:ZeRO初始化时候会对参数进行均匀切分给各个rank。 通过参数分区,进而实现梯度、优化器的分区。
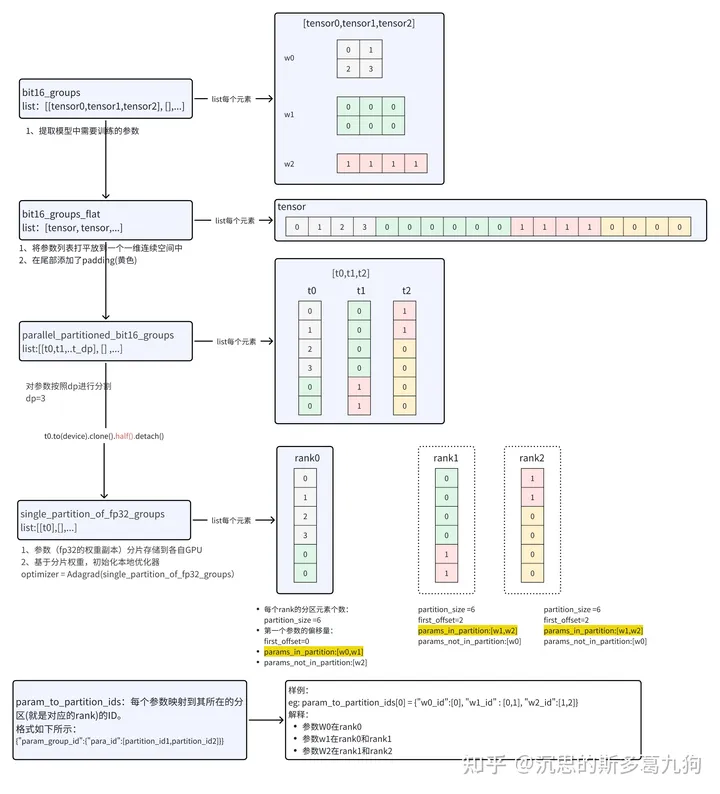
除此之外,注册梯度钩子函数reduce_partition_and_remove_grads(当梯度计算完成时自动调用该函数)
5.2.2 forward
在模型model进行前向传播,返回loss,ZeRO不需要进行特殊处理。
5.2.3 backward
- 申请固定大小(reduce_bucket_size)的缓存ipg_buffer
- 通过 loss_scaler 对损失进行反向传播 ,通常包含对loss的缩放处理(用于解决fp16存在的梯度下溢问题)。
self.ipg_buffer = []
buf_0 = torch.empty(int(self.reduce_bucket_size),
dtype=self.dtype,
device=get_accelerator().current_device_name())
self.ipg_buffer.append(buf_0)
#初始化 loss_scaler : 动态DynamicLossScaler 或者 常量LossScalerself.loss_scaler = CreateLossScaler(dtype=self.dtype,
static_loss_scale=static_loss_scale,
dynamic_scaling=dynamic_loss_scale,
dynamic_loss_args=dynamic_loss_args)
self.loss_scaler.backward(loss.float(), retain_graph=retain_graph)
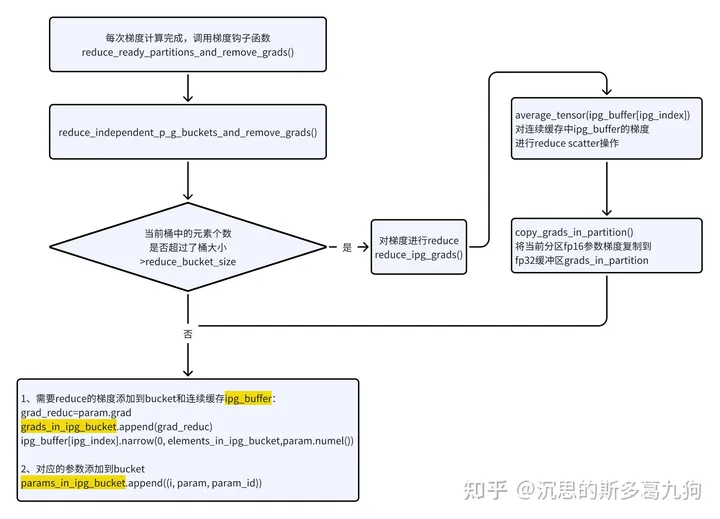
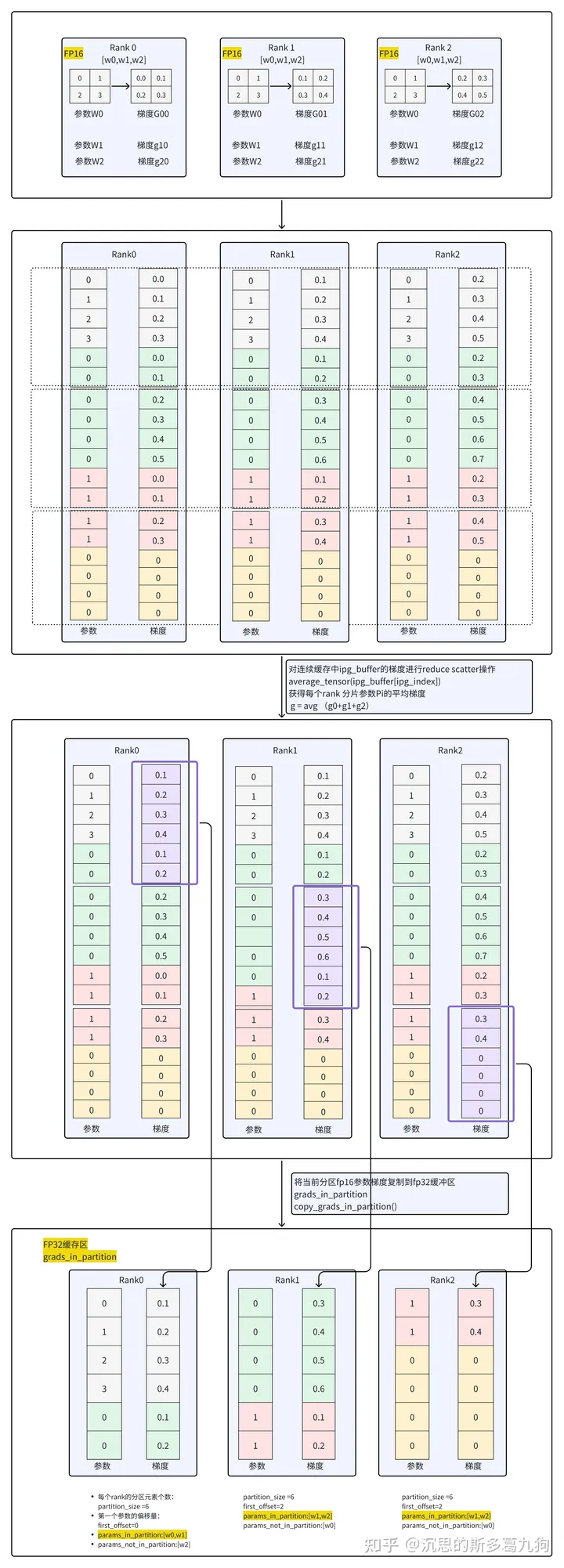
5.2.4 reduce_ipg_grads()
ipg:Independent Parallel Gradient
简介:对连续的ipg梯度进行reduce。
5.2.4 step














暂无评论内容