
分布式训练topic由以下几部分组成:
数据并行:
- 创建一个模型的多个副本,每个模型副本处理一部分训练数据,并独立执行向前和向后传播。
- 每个GPU拥有完整的模型副本PGO,可以根据算法同步其梯度或更新的参数。
- 基于梯度累加的原理进行模型更新。
- 显存节约:减少中间激活值显存占用。[bs,seq_len, dim] –> [bs/n,seq_len, dim]
- pytorch实现:2种实现,Data Parallel 和 Distributed DataParallel。
1、DP (Data Parallel)
torch.nn.DataParallel
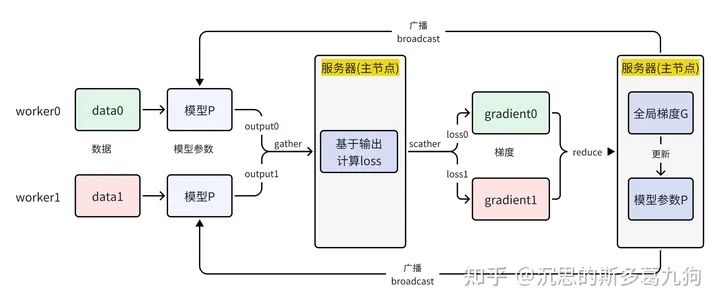
中心化的参数服务器模式,以server作为主节点,worker作为打工人,向老板server汇报工作。
(1)server工作内容如下:
- gather各worker的输出output,在主节点上计算 loss,将loss分发给各worker。
- reduce各worker的梯度gradient,在主节点进行模型参数更新。
- 将更新后的模型参数广播给各个worker。
(2)worker工作内容如下:
- 对各自的输入数据进行 forward,生成各自的输出output.
- 基于loss进行backward,生成各自的gradient。
存在问题:server通信耗时成为性能瓶颈,其他worker只能干等。
2、DDP (Distributed DataParallel)
torch.nn.DistributedDataParallel
论文:PyTorch Distributed: Experiences on Accelerating Data Parallel Training 2020 Facebook
2.1 原理
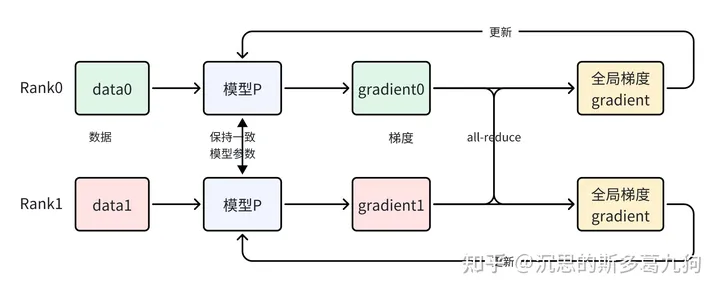
去中心化,移除了参数服务器。
基于各自的batch-data,每个GPU独自计算梯度,通过Ring-AllReduce的通信方式进行梯度同步,然后在各自的GPU中更新模型。(不需要参数广播步骤)
各rank上模型一致性保证:相同的初始模型参数+相同的更新梯度。
核心代码:
optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()average_gradients(model)optimizer.step()
“”” Gradient averaging. “””def average_gradients(model):
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
param.grad.data /= size
2.2 性能优化
问题:
- 梯度规约对分布式训练速度有显著影响,设计一个高效的all-reduce算法。
- 集合通信在小张量上表现不佳,尤其是在LLM中,具有大量的小参数。
2.2.1 Ring-AllReduce
Ring-AllReduce:基于环的算法,更加高效。
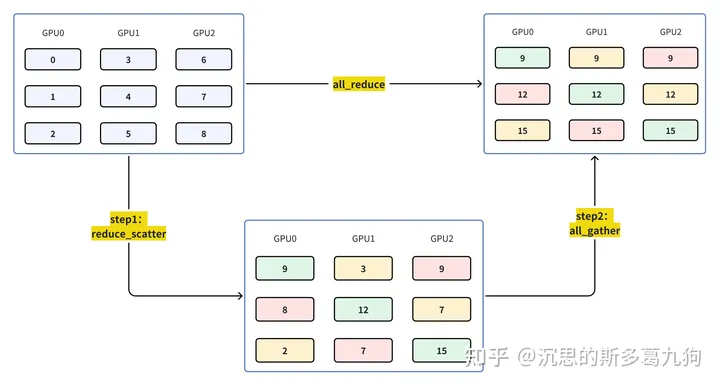
整个算法流程:
- 流程拆分:拆成两步:reduce-scatter和all-gather。
- 数据拆分:有N个GPU,每个GPU上的数据也对应被切成N份。
总通信量:2*Ψ (reduce-scatter和all-gather各1次,详情分析见下文)
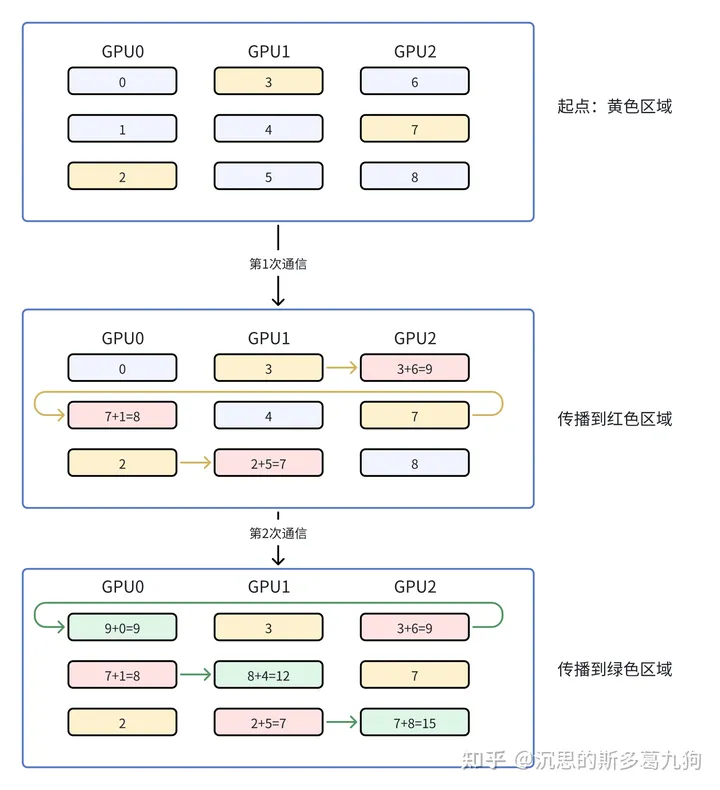
(1)基于环的reduce-scatter:
通信量分析:通讯量均衡分布到每个GPU上。
- 每个GPU一次通信量:Ψ/N
- 每个GPU通信次数:(N-1)
- 单个GPU通信量:Ψ/N * (N-1) = Ψ-Ψ/N ≈ Ψ
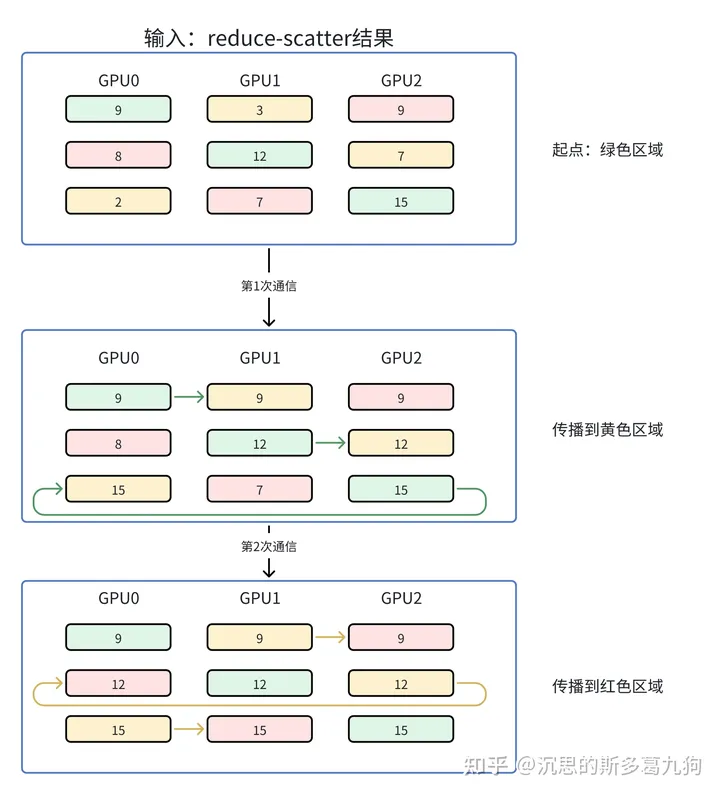
(2)基于环的all-gather:
通信量分析:同理,单个GPU通信量Ψ
2.2.2 Gradient Bucketing
Motivation:集合通信在大张量上更有效。
Idea:在短时间内等待并将多个梯度存储到一个数据桶,然后进行AllReduce操作。而不是对每个参数梯度立刻启动AllReduce操作。
2.3 Megtron-LM的ddp实现
源码:/megatron/model/distributed.py
- DistributedDataParallel:梯度初始化、对梯度进行reduce操作
- MemoryBuffer:预先为梯度分配的连续内存,可以减少内存碎片。
2.3.1 初始化
梯度通过MemoryBuffer类进行预分配连续内存。
将模型参数广播给ddp数据进程组。

源码分析
class DistributedDataParallel(DistributedDataParallelBase):
“”” _grad_buffers:{}, 存储参数梯度的连续内存 {“float32”:MemoryBuffer, “float16”:MemoryBuffer} _grad_buffer_param_index_map:{}, 存储每个参数、以及对应梯度在连续内存区的起始位置 {“float32”:{“W0”:(13, 14), “W1”:(9, 13), “W2”:(0, 9)}} Parameter containing:tensor([[0.0], dtype=torch.float32, requires_grad=True): (13, 14), broadcast_params()方法:将参数广播到ddp数据并行组的其他rank “””
def __init__(self):
super(DistributedDataParallel, self).__init__(module)
#为梯度分配的连续内存
self._grad_buffers = None
#存储每个参数梯度在连续内存的起始位置
self._grad_buffer_param_index_map = None
def broadcast_params(self):
for param in self.module.parameters():
torch.distributed.broadcast(param.data,
src=mpu.get_data_parallel_src_rank(),
group=mpu.get_data_parallel_group())
2.3.2 梯度reduce
采用2种方法进行梯度reduce:
- 方法1:基于连续内存MemoryBuffer进行梯度规约
- 方法2:用数据桶的方法来归并
源码分析:
class DistributedDataParallel(DistributedDataParallelBase):
“”” _grad_buffers:{}, 存储参数梯度的连续内存 {“float32”:MemoryBuffer, “float16”:MemoryBuffer} allreduce_gradients()方法:基于连续内存 or 桶的方法进行梯度reduce “””
def allreduce_gradients(self):
#方法1:基于连续内存MemoryBuffer进行梯度规约
if self._grad_buffers is not None:
for _, buffer_ in self._grad_buffers.items():
buffer_.data /= mpu.get_data_parallel_world_size()
#参数W对应的梯度:buffer_.data
torch.distributed.all_reduce(
buffer_.data, group=mpu.get_data_parallel_group())
#方法2:用桶的方法来归并
else:
buckets = {}
# Pack the buckets.
for param in self.module.parameters():
if param.requires_grad and param.grad is not None:
tp = param.data.type()
if tp not in buckets:
buckets[tp] = []
buckets[tp].append(param)
# For each bucket, all-reduce and copy all-reduced grads.
for tp in buckets:
bucket = buckets[tp]
grads = [param.grad.data for param in bucket]
#梯度打平成一维进行规约
coalesced = _flatten_dense_tensors(grads)
coalesced /= mpu.get_data_parallel_world_size()
torch.distributed.all_reduce(
coalesced, group=mpu.get_data_parallel_group())
for buf, synced in zip(grads, _unflatten_dense_tensors(
coalesced, grads)):
buf.copy_(synced)
3、DP和DDP区别

参考
https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
















暂无评论内容