
分布式训练topic由以下几部分组成:
1、梯度累积 Gradient Accumulation
1.1 简介
存在问题:
- 如果batch_size过大,显存不够用。
- 通常来说,batch_size越大,模型训练稳定。
解决办法:
- 每次反向传播后,先不进行模型参数的迭代更新。
- 本地使用 batch_size 进行N次的正向和反向传播,基于累积的梯度再进行模型更新。相当于基于N *batch_size 的样本进行模型更新,将batch_size扩大了N倍。
梯度累积与数据并行:
- 类似数据并行,都是通过梯度累加的方式进行模型更新。
应用场景:
- 流水线并行中,将一个batch拆分为多个micro-batch,多个micro-batch的权重梯度是累积的。
for i, (inputs, target) in enumerate(train_loader):
# 1. forward
outputs = model(inputs) # 前向传播
loss = criterion(outputs, target) # 计算损失
# 2. backward 累积梯度
# 在 pytorch 中,梯度只要不清零默认是累加的
loss.backward() # 反向传播,计算当前梯度
# 3. 基于累积的梯度进行模型更新
if ((i+1)%accumulation)==0:
# optimizer the net
optimizer.step() # 更新网络参数
optimizer.zero_grad() # reset grdient # 清空过往梯度
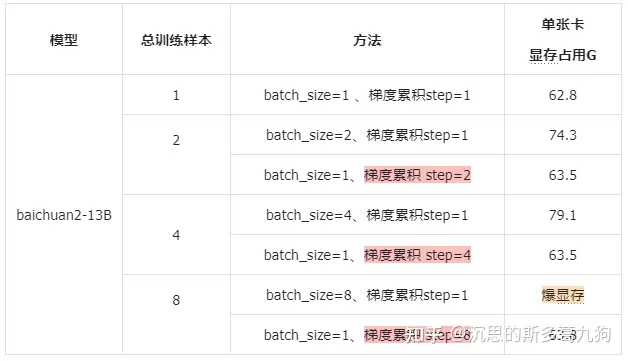
1.2 实验结果
实验配置:80G 8*A800 、全参训练,seq_len = 4096,ZeRO stage3。
应用方式:只需要在TrainingArguments中设置gradient_accumulation_steps=4
training_args = TrainingArguments(gradient_accumulation_steps=4, **default_args)
结论:如果没有梯度累积,真实bs最多到4。 引入梯度累积,真实bs可以到2*8=16
2、梯度检查点 Gradient Checkpointing
论文:Reducing Activation Recomputation in Large Transformer Models. NVIDIA 2022
多种叫法:激活重新计算(activation recomputation)、激活检查点(activation checkpointing)、梯度检查点(gradient checkpointing)
2.1 激活值显存占用
2.1.1 为什么需要激活值
PyTorch 使用反向传播计算梯度。反向传播需要中间变量参与计算,所以在构建计算图时需要随时保存。
2.1.2 激活值理论计算
根据Paper计算,Transformer中每个Layer 激活值显存占用:
(34∗seqLen∗hiddenSize+5∗seqLen2∗attenNums)∗bs
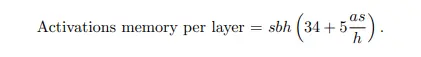
注:由于不同模型结构存在差异,无统一计算公式,且计算复杂。建议直接代码实践,获得显存占用值。
2.1.3 激活值实践结果
- 激活值显存占用与批处理大小bs: O(n)
- 激活值显存与文本长度seqLen: O(n2)
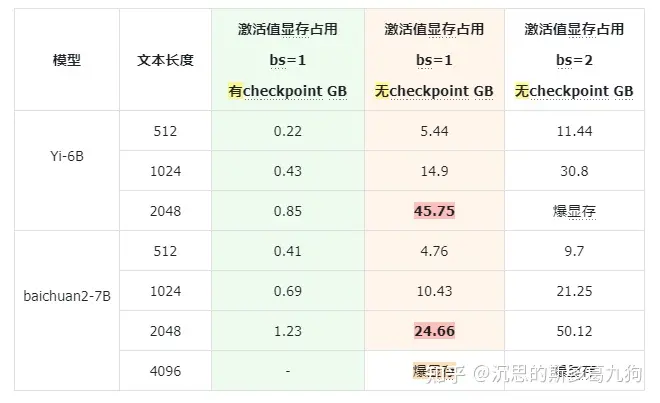
注:baichuan2-7b采用了xformers的memory_efficient_attention计算attention,降低显存占用。
激活值占用代码:
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizermodel_path =“…/pretrain_models/LLMS/yi-6b-200k”model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map=“cuda:0”,
trust_remote_code=True,)model=model.cuda()
max_len = 512bs=2inputs = torch.tensor([[1]*max_len for i in range(bs)]).cuda(0)memory_allocated1=torch.cuda.memory_allocated(0)memory_allocated1_gb=memory_allocated1/(1024**3)print(f”before forward1,分配显存: {memory_allocated1_gb} GB “)
#加入checkpoint策略 model.gradient_checkpointing_enable()model.model.training=Truemodel.config.use_cache = False
#forward计算,没有checkpoint时,会保留中间结果。outpust= model(input_ids=inputs)memory_allocated2=torch.cuda.memory_allocated(0)print(f”after forward1,分配显存: {(memory_allocated2-memory_allocated1)/(1024**3)} GB “)
2.2 gradient checkpoint方法
2.2.1 原理介绍
目标:降低激活值显存占用。 原理:设置一些梯度检查点,检查点之外的中间结果先释放掉,在反向传播的过程中如果发现中间结果不在显存中,就找到最近的梯度检查点再进行前向计算,恢复出被释放的中间结果张量。
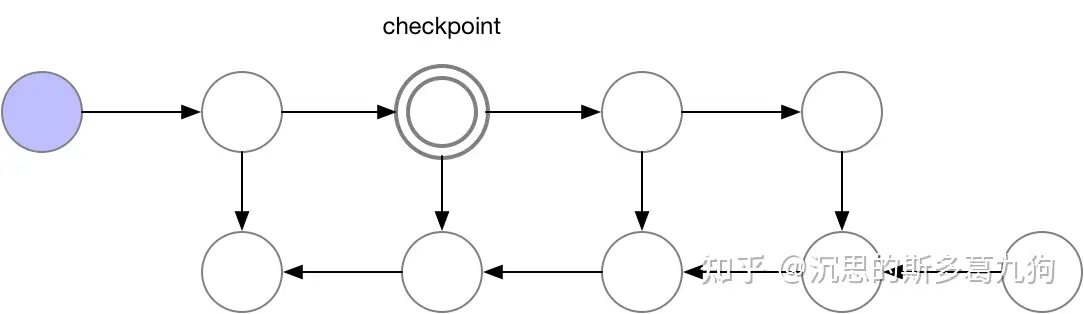
- 前向传播:只保留一部分梯度检查点(下图为2个)。
- 反向传播:基于梯度检查点,按需恢复需要的中间结果。
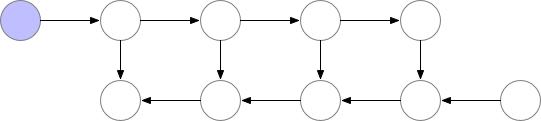
Pytorch实现
torch.utils.checkpoint.checkpoint()方法
class LlamaModel(LlamaPreTrainedModel):
def forward():
…
if self.gradient_checkpointing and self.training:
def create_custom_forward(module):
def custom_forward(*inputs):
# None for past_key_value
return module(*inputs, output_attentions, None)
return custom_forward
#有checkpoint
#decoder_layer的前向计算在torch.no_grad模式,不存储中间激活值
layer_outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(decoder_layer),
hidden_states,
attention_mask,
position_ids,
None,
)
else:
#没有checkpoint
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
…
2.2.2 实验结果
实验配置:80G 8*A800 、全参训练,bs=1,seq_len = 4096。
应用方式:只需要在TrainingArguments中设置gradient_checkpointing = True
training_args = TrainingArguments(gradient_checkpointing =True, **default_args)
结论:
- 在Yi-6B上,引入checkpoint,模型从无法训练(>80G)到可训练(<50G),减少近一半显存。
- 在baichuan2-7B,引入checkpoint,也带来至少20%+的显存性能优化。
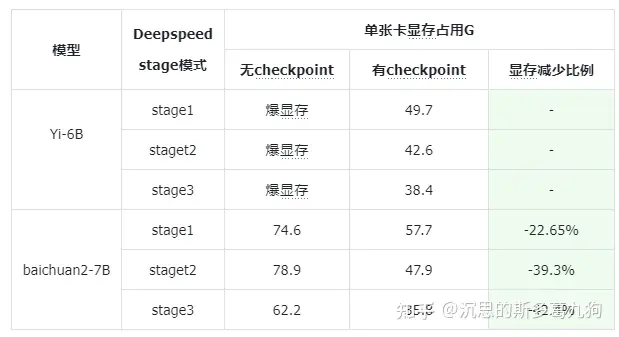
3、混合精度训练 MIXED PRECISION TRAINING
3.1 Float浮点数介绍
浮点数数据类型 由符号位、指数位E(数据范围大小)和尾数位M(数据精度) 3部分组成。
3.11 fp32、fp16与bf16简介
- Float32(FP32):单精度浮点数,指数位8位,尾数位23位。
- Float16 (FP16) :半精度浮点数,指数位5 位,尾数位 10 位。
- Bfloat16 (BF16) :指数位 8 位 (与 FP32 相同),尾数位 7 位。由google brain团发研发。
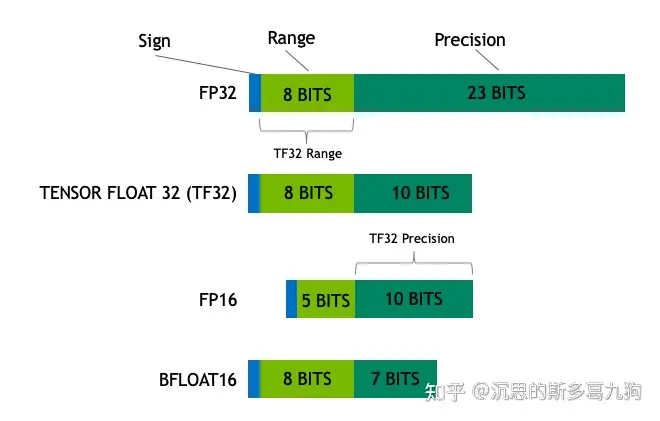
浮点数之间相互转换代码:
import torchtensor = torch.tensor(0.99)# float():转为fp32 位–>float32_tensor = tensor.float()# half():转为fp16 位–>float16_tensor = tensor.half()#bfloat16():转为bf16位bfloat16_tensor = tensor.bfloat16()
3.12 fp32、fp16与bf16对比
- 数值表达范围:fp32=bf16>fp16
- 数值表达精度:fp32>fp16>bf16
- 模型训练/推理速度:bf16=fp16>fp32
- 显存占用:fp32>fp16=bf16
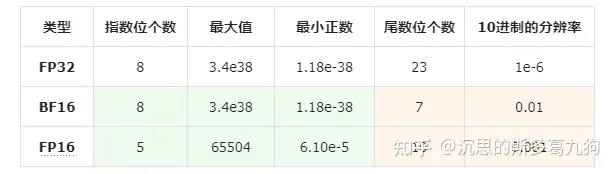
查看各float类型详情,代码实现::
print(torch.finfo(torch.float32))print(torch.finfo(torch.float16))print(torch.finfo(torch.bfloat16))
打印结果:
finfo(resolution=1e-06, min=-3.40282e+38, max=3.40282e+38, eps=1.19209e-07, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=float32)finfo(resolution=0.001, min=-65504, max=65504, eps=0.000976562, smallest_normal=6.10352e-05, tiny=6.10352e-05, dtype=float16)finfo(resolution=0.01, min=-3.38953e+38, max=3.38953e+38, eps=0.0078125, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=bfloat16)
NVIDIA的Volta及Turing架构GPU在使用FP16计算时的特点如下:
- 降低显存需求:这样开发者在相同的硬件条件下可以使用更大更复杂的模型和更大的batch size。
- 减少训练/推理时间:英伟达Volta和Turing架构GPU提供了Tensor Cores技术。Tensor Cores的fp16计算吞吐量是fp32的8倍。
3.2 fp16训练
3.2.1 存在的问题
模型直接采用fp16训练会存在数据溢出(下溢和上溢)和舍入误差问题:
- 下溢问题:Grad Underflow,小于fp16最小正数6.1e-5的数值会变成0 。模型Weight 更新 ≈ gradient∗lr , 学习率lr = 1e-5量级, 所以fp16容易出现参数更新量丢失(因为小于fp16最小非零数(6e-5),就变成0),导致模型不更新。模型训练过程,更容易出现下溢问题。
- 上溢问题:Grad Overflow,大于fp16最大值65504的数值会变成无穷大。
- 舍入误差问题:Rounding Error,float32转为float16时,由于尾数位不一样,会产生精度损失。模型训练时,模型新参数w2=w1+δw , 每次相加,由于精度不足,导致模型更新错误。
溢出问题代码实现:
#下溢问题lr = 1e-5gradient = 0.001float16_tensor = torch.tensor(lr*gradient, dtype=torch.float16)bfloat16_tensor = torch.tensor(lr*gradient, dtype=torch.bfloat16)print(“float16_tensor:”,float16_tensor)print(“bfloat16_tensor:”,bfloat16_tensor)
#上溢问题constant=256float16_tensor = torch.tensor(constant*constant, dtype=torch.float16)bfloat16_tensor = torch.tensor(constant*constant, dtype=torch.bfloat16)
打印结果:
float16_tensor: tensor(0., dtype=torch.float16) #–>参数更新值为0bfloat16_tensor: tensor(1.0012e-08, dtype=torch.bfloat16)
float16_tensor: tensor(inf, dtype=torch.float16)bfloat16_tensor: tensor(65536., dtype=torch.bfloat16)
舍入误差问题代码实现:
w=3.141float32_tensor = torch.tensor(w, dtype=torch.float32)float16_tensor = torch.tensor(w, dtype=torch.float16)print(“float32_tensor:”,float32_tensor)print(“float16_tensor:”,float16_tensor)print(“float16+float16:”,float16_tensor+float16_tensor)print(“float32+float32:”,float32_tensor+float32_tensor)
打印结果:
#f32–> fp16, 有精度损失(舍入误差)float32_tensor: tensor(3.1410)float16_tensor: tensor(3.1406, dtype=torch.float16)
#相比f32+f32, 误差为 0.0008float16+float16: tensor(6.2812, dtype=torch.float16)float32+float32: tensor(6.2820)
在训练SSD网络的时候,如果采用FP16格式,67%的梯度值为0,即存在梯度下溢。
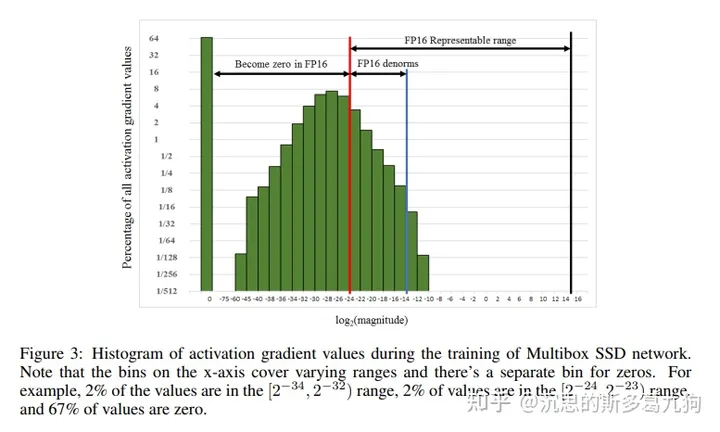
3.2.2 解决办法
| 问题 | 解决办法 |
| 溢出问题 |
方法1:Loss scale(混合精度训练)
方法2:替换fp16,采用bf16训练 |
| 舍入误差问题 | fp32权重备份(混合精度训练) |
3.3 fp16混合精度训练
论文:MIXED PRECISION TRAINING 2018 baidu/NVIDIA
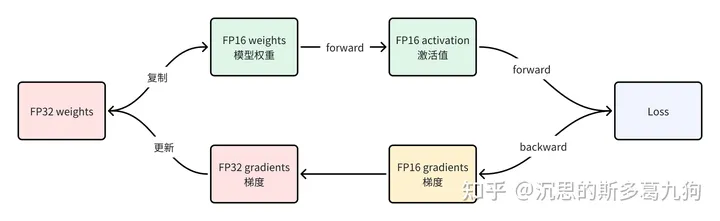
3.3.1 训练流程

- 维护一份fp32的模型主权重
- 维护一份fp16的模型训练权重
-
对于每次迭代:
- forward:基于fp16模型,进行前向传播,获得fp16的激活值
- loss计算:loss scale操作,将loss放大S倍, loss∗S
- backward:基于fp16模型、激活值,进行反向传播,获得fp16的梯度gradient
- 梯度:gradient unscale操作,梯度缩小S倍, gradient/S
- 参数更新:基于fp32模型,fp32的梯度,进行参数更新。
main_param.grad = model_param.main_grad.float()
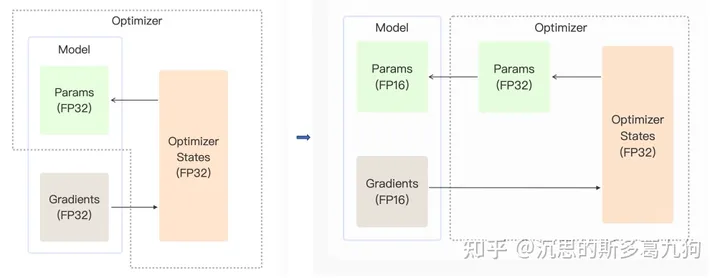
3.3.2 fp32权重备份
- fp32模型:模型主权重,用于模型参数更新,避免舍入误差问题。
- fp16模型:模型训练权重,用于模型forward/backward计算,提升模型训练速度。
论文注释:相比fp32模型训练,这里是增加了50%的模型权重,但对整体显存占用影响不大。根据论文描述,训练过程中主要的显存占用为激活值,由于激活值从fp32变成了fp16,相当于整个训练过程的显存消耗减少一半。
Even though maintaining an additional copy of weights increases the memory requirements for the weights by 50% compared with single precision training, impact on overall memory usage is much smaller. For training memory consumption is dominated by activations, due to larger batch sizes and activations of each layer being saved for reuse in the back-propagation pass. Since activations are also stored in half-precision format, the overall memory consumption for training deep neural networks is roughly halved.
3.3.3 loss scale
通过链式法则,Loss放大S倍,使得计算出来的梯度也放大S倍,进而解决fp16存在的梯度下溢问题。
两种方法:常量损失放大和动量损失放大
- 常量损失放大:固定的缩放因子S。
- 动态损失放大:以一个较大的缩放因子S开始,然后在每次训练迭代中进行动态更新。如果在选定的迭代次数N中没有发生上溢(inf/nan),则增加缩放因子S。如果发生溢出,则跳过权重更新,降低缩放因子S。
#deepspeed实现def unscale_and_clip_grads(self, grad_groups_flat, total_norm):
# compute combined scale factor for this group
combined_scale = self.loss_scale
if self.clip_grad > 0.:
# norm is in fact norm*scale
clip = ((total_norm / self.loss_scale) + 1e-6) / self.clip_grad
if clip > 1:
combined_scale = clip * self.loss_scale
for grad in grad_groups_flat:
if isinstance(grad, list):
sub_partitions = grad
for g in sub_partitions:
g.data.mul_(1. / combined_scale)
else:
grad.data.mul_(1. / combined_scale)
3.3.4 Pytorch实现
PyTorch 就是使用了autocast + GradScaler
autocast:上下文管理器,将forward和loss计算,采用fp16或者bf16
GradScaler:放大loss,防止梯度underflow
autocast作用:
def autocast_operation():
a_float32 = torch.randn(2,4,dtype=torch.float32)
b_float32 = torch.randn(4,2,dtype=torch.float32)
c_output = a_float32@b_float32
print(“输出类型:”,c_output.dtype)
with torch.autocast(device_type=“cpu”,dtype=torch.bfloat16):
d_output = a_float32@b_float32
print(“autocast上下文 输出类型:”,d_output.dtype)
打印结果:
输出类型: torch.float32autocast上下文 输出类型: torch.bfloat16
模型在autocast上下文中进行训练:
# Creates model and optimizer in default precisionmodel = Net().cuda()optimizer = optim.SGD(model.parameters(), …)
for input, target in data:
optimizer.zero_grad()
# Enables autocasting for the forward pass (model + loss)
with torch.autocast(device_type=“cuda”):
output = model(input)
loss = loss_fn(output, target)
# Exits the context manager before backward()
loss.backward()
optimizer.step()
3.3.5 应用方式
只需要在TrainingArguments中设置fp16=True
training_args = TrainingArguments(fp16=True, **default_args)
3.4 bf16混合精度训练
论文:Revisiting BFloat16 Training 2020
3.4.1 简介
将float16替换为bfloat16
注:并非所有的GPU都支持bf16,通过以下代码检查GPU是否支持bf16:torch.cuda.is_bf16_supported()
3.4.2 应用方式
只需要在TrainingArguments中设置bf16=True
training_args = TrainingArguments(bf16=True, **default_args)
注:Rope 和 alibi 位置编码的主流实现在低精度(尤其是 bfloat16) 下存在位置编码碰撞的 bug, 这可能会影响模型的训练和推理。
参考
https://huggingface.co/docs/transformers/main/en/perf_train_gpu_one
https://github.com/cybertronai/gradient-checkpointing
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html
https://huggingface.co/docs/transformers/main_classes/trainer














暂无评论内容