
分布式训练topic由以下几部分组成:
1、Pytorch 显存管理机制
1.1 原理
Pytorch 内部有自己的缓存管理系统,能够加速显存分配
(1)申请tensor:先申请一块缓存区Cache, 再从存中分配实际显存占用(最小分配单元为512字节/1024字节)。
为小于 1MB 的 size 分配 2MB缓存;
为 1MB ~ 10MB 的 size 分配 20MB缓存;
为 >= 10MB 的 size 分配 { size 向上取整至 2MB 倍数 } MB缓存。
(2)删除tensor:回收该tensor所占用的实际显存,缓存区cache显存不
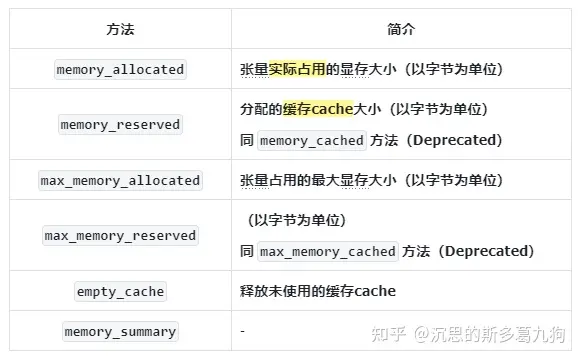
1.2 torch.cuda方法
torch.cuda方法相比 nvidia-smi , 显存占用分析更精准。
1.3 例子分析
以申请一个张量为例:
例子1:申请<512字节(最小分配单元为)的张量

例子2:申请1MB ~ 10MB 的张量

详情代码:
#显存分配import torch#申请4个字节a = torch.tensor(1.0).cuda()#1、memory_allocated –> 从2MB缓存区分配512/1024字节(最小分配单元) 给该申请memory_allocated=torch.cuda.memory_allocated()
#2、memory_reserved –> 从GPU显存分配给缓存区2MBmemory_reserved=torch.cuda.memory_reserved()memory_reserved_MB = memory_reserved/(1024**2)
print(f” 申请显存 torch.cuda.memory_allocated : {memory_allocated} byte “)print(f” 申请显存 torch.cuda.memory_reserved : {memory_reserved_MB} MB “)
del aprint(f” 释放显存 after del a torch.cuda.memory_allocated : {memory_allocated} byte “)print(f” 释放显存 after del a torch.cuda.memory_reserved : {memory_reserved_MB} MB “)
torch.cuda.empty_cache()print(f” 释放缓存 after empty_cache torch.cuda.memory_allocated : {memory_allocated} byte “)print(f” 释放缓存 after empty_cache torch.cuda.memory_reserved : {memory_reserved_MB} MB “)
2、模型训练显存占用
2.1 显存占用分析
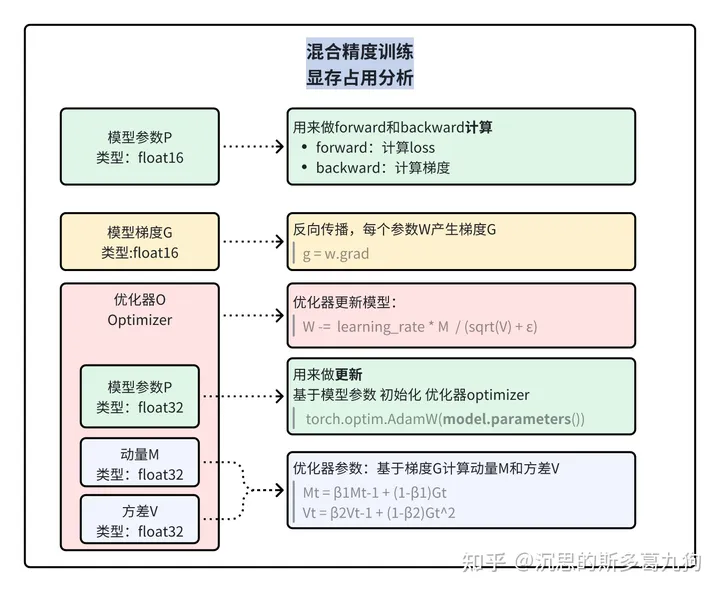
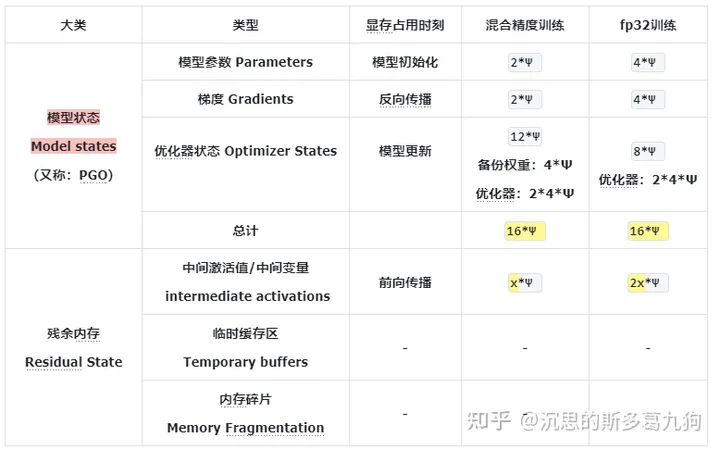
根据ZeRO论文,模型训练过程中,显存占用主要由以下部分组成:
以参数量为 Ψ的模型和 Adam optimzier为例:
2.2 以Linear Model为例
实验设置:fp32训练
实验一:1个线性层















暂无评论内容