
分布式训练topic由以下几部分组成:
1.1 配置初始化
torch.distributed:pytorch的分布式包,可实现跨进程和跨机器集群的并行计算。
为了运行后续介绍的一系列通信方法,先通过以下代码进行分布式初始化。
1.1.1 初始化
- torch.distributed.init_process_group():初始化进程组
- torch.distributed.new_group(ranks=[0,1,2]):新建一个子进程组,进程组包含rank0、rank1和rank2
import osimport torchimport torch.distributed as distimport torch.multiprocessing as mp
#初始化进程组和执行function
def init_process(rank,world_size,fn,backned=“nccl”):
os.environ[‘MASTER_ADDR’] = “127.0.0.1”
os.environ[‘MASTER_PORT’] = “29500”
#初始化进程组:init_process_group
#world_size:总进程个数
dist.init_process_group(backned,rank=rank,world_size=world_size)
#启动rank个进程,各进程执行func
fn(rank,world_size)
def run(rank, world_size):
#新建一个group,ranks是该group的rank成员, 在集合通信中应用
group = dist.new_group(ranks=list(range(world_size)))
“”” 在这里实现具体的Collective Operations. “””
if __name__ == ‘__main__’:
world_size = 2
processes = []
mp.set_start_method(“spawn”)
for rank in range(world_size):
#在各算子操作中,替换run方法
p = mp.Process(target=init_process,args=(rank,world_size,run))
p.start()
processes.append(p)
for p in processes:
p.join()
1.1.2 基础概念
- node:节点个数
- group :进程组,用于集体通信,各个rank会在进程组内进行相互通信。
- torch.distributed.new_group(ranks=[]):初始化进程组
- world_size:进程组group的rank个数。
-
torch.distributed.get_world_size(group) :
- 该rank不在group,则返回-1。
- 该rank在group,返回该group的rank个数。
-
torch.distributed.get_world_size(group) :
- local_rank:进程组group的局部rank编号。
-
torch.distributed.get_rank(group)
- 该rank不在group,则返回-1。
- 返回在group的局部rank。
-
torch.distributed.get_rank(group)
- rank:全局GPU资源列表,进组中的唯一标识。从 0 到 world_size 的连续整数。
-
torch.distributed.get_global_rank(group,group_rank):
- 如果group_rank不在group,则报错。
- 依据local_rank/group_rank,返回全局rank。
-
torch.distributed.get_global_rank(group,group_rank):
- backned:后端配置,GPU训练 –> “nccl” 、 CPU训练 –> “gloo”
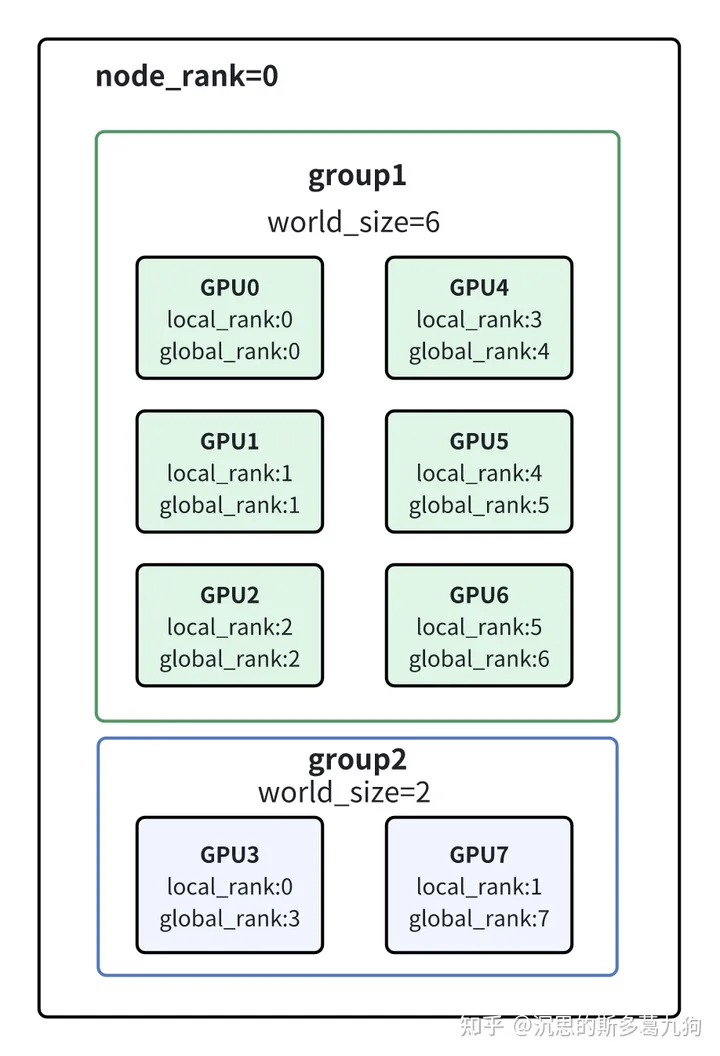
def run(rank,world_size):
#初始化进程组
group1 = dist.new_group(ranks=[0,1,2,4,5,6])
group2 = dist.new_group(ranks=[3,7])
#1、返回进程组world_size
world_size1 = dist.get_world_size(group1)
world_size2 = dist.get_world_size(group2 )
“”” 当前rank不在group中,world_size = -1 如果当前rank在group1中,则返回 world_size1 = 6,world_size2 = -1 如果当前rank在group2中,则返回 world_size1 = -1,world_size2 = 2 “””
#2、返回GPU3的local rank
local_rank1 = dist.get_rank(group1) #
local_rank2 = dist.get_rank(group2) #
“”” local_rank1 = -1 , local_rank不在group1 local_rank2 =0 “””
#3、返回GPU3的global rank
global_rank1 = dist.get_global_rank(group1,local_rank) #
global_rank2 = dist.get_global_rank(group2,local_rank) #
“”” global_rank1 :报错, local_rank不在group1 global_rank2 = 3 “””
1.1.3通信方式
主要有两种:
- Point-to-Point Communication 点对点通信
- Collective Operations 集合通信
接下来主要介绍集合通信。
1.2 集合通信 Collective Operations
1.2.1 广播 broadcast
将src显卡的tensor复制到其他显卡。
torch.distributed.broadcast(tensor, src, group=None, async_op=False)
方法参数:
- tensor:Tensor
- src rank:输入数据
- 非src rank:输出数据
- src:int
- group: 通信的进程组
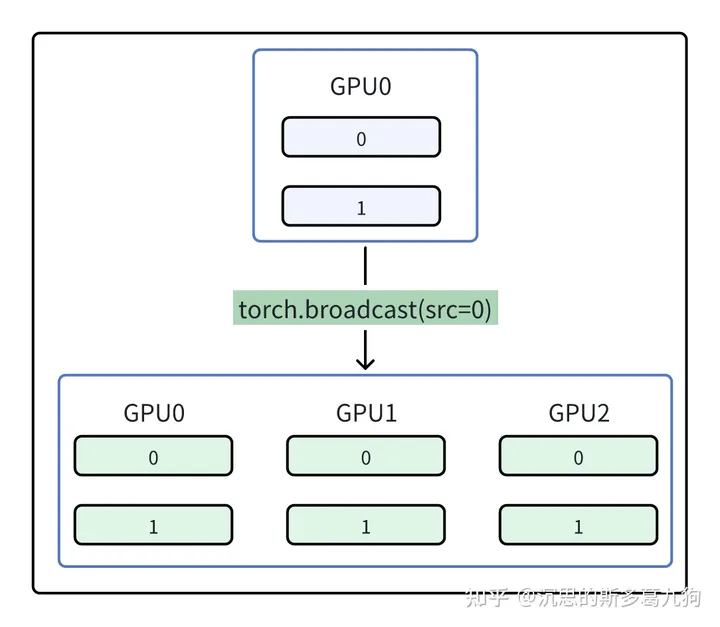
代码实现
def run_broadcast(rank,world_size):
src_rank=0
group = dist.new_group(ranks=list(range(world_size)))
if rank==src_rank:
tensor = torch.tensor([0,1]).to(torch.device(“cuda”,rank))
else:
tensor = torch.empty(2,dtype=torch.long).to(torch.device(“cuda”,rank))
print(f”before rank num is {rank},tensor is{tensor} \n”)
start_time = time.time()
dist.broadcast(tensor, src_rank, group)
end_time = time.time()
print(f” broadcast cost time: {end_time – start_time}s”)
print(f”after broadcast rank num is {rank},tensor is{tensor} \n”)
打印结果
before rank num is 1,tensor istensor([140408140270456, 140408140270456], device=‘cuda:1’) before rank num is 2,tensor istensor([7882826979423645728, 8317129566153437807], device=‘cuda:2’) before rank num is 0,tensor istensor([0, 1], device=‘cuda:0’)
after broadcast rank num is 1,tensor istensor([0, 1], device=‘cuda:1’) after broadcast rank num is 0,tensor istensor([0, 1], device=‘cuda:0’) after broadcast rank num is 2,tensor istensor([0, 1], device=‘cuda:2’)
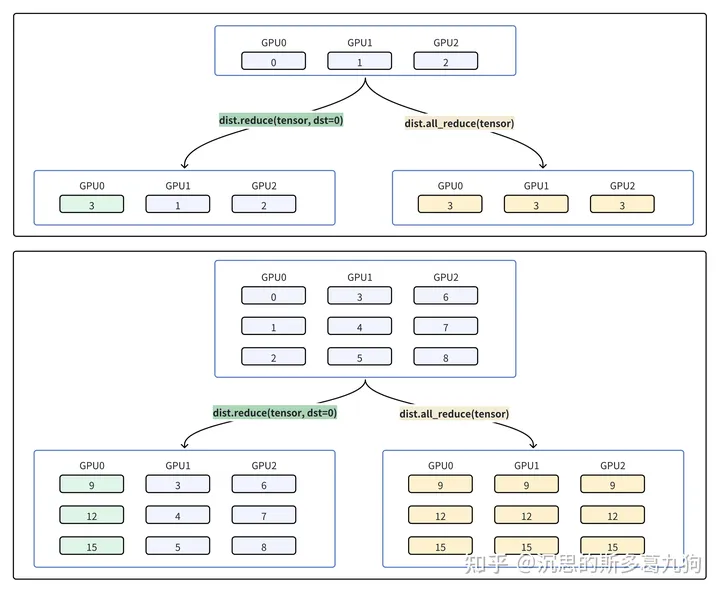
1.2.2 规约 reduce
(1)reduce:将各个显卡的数据进行规约,规约后的结果传给1个指定显卡(dst rank)。
torch.distributed.reduce(tensor, dst, op=<RedOpType.SUM: 0>, group=None, async_op=False)
(2)all-reduce:将各个显卡的数据进行规约,规约后的结果传给所有显卡。
torch.distributed.all_reduce(tensor, op=<RedOpType.SUM: 0>, group=None, async_op=False)
方法参数:
- tensor :Tensor. 输入和输出的tensor
- dst: int,目标rank
- op : 算子操作。eg:求和、最小值等操作。dist.ReduceOp.SUM
- group: 通信的进程组
代码实现
def run_reduce(rank,world_size):
group = dist.new_group(ranks=list(range(world_size)))
tensor = torch.tensor([3 * rank,3 * rank + 1,3 * rank + 2]).to(torch.device(“cuda”, rank))
print(f”before rank num is {rank},tensor is{[i.item() for i in tensor]} \n”)
dst_rank = 0 #目标rank
dist.reduce(tensor=tensor,dst=dst_rank,op=dist.ReduceOp.SUM,group=group)
print(f”after reduce rank num is {rank},tensor is{[i.item() for i in tensor]} \n”)
def run_all_reduce(rank,world_size):
group = dist.new_group(ranks=list(range(world_size)))
tensor = torch.tensor([3 * rank,3 * rank + 1,3 * rank + 2]).to(torch.device(“cuda”, rank))
print(f”before rank num is {rank},tensor is{[i.item() for i in tensor]} \n”)
dist.all_reduce(tensor=tensor,op=dist.ReduceOp.SUM,group=group)
print(f”after all_reduce rank num is {rank},tensor is{[i.item() for i in tensor]} \n”)
打印结果
before rank num is 2,tensor is[6, 7, 8] before rank num is 1,tensor is[3, 4, 5] before rank num is 0,tensor is[0, 1, 2]
after reduce rank num is 1,tensor is[3, 4, 5] after reduce rank num is 0,tensor is[9, 12, 15] after reduce rank num is 2,tensor is[6, 7, 8]
before rank num is 2,tensor is[6, 7, 8] before rank num is 1,tensor is[3, 4, 5] before rank num is 0,tensor is[0, 1, 2]
after all_reduce rank num is 1,tensor is[9, 12, 15] after all_reduce rank num is 2,tensor is[9, 12, 15] after all_reduce rank num is 0,tensor is[9, 12, 15]
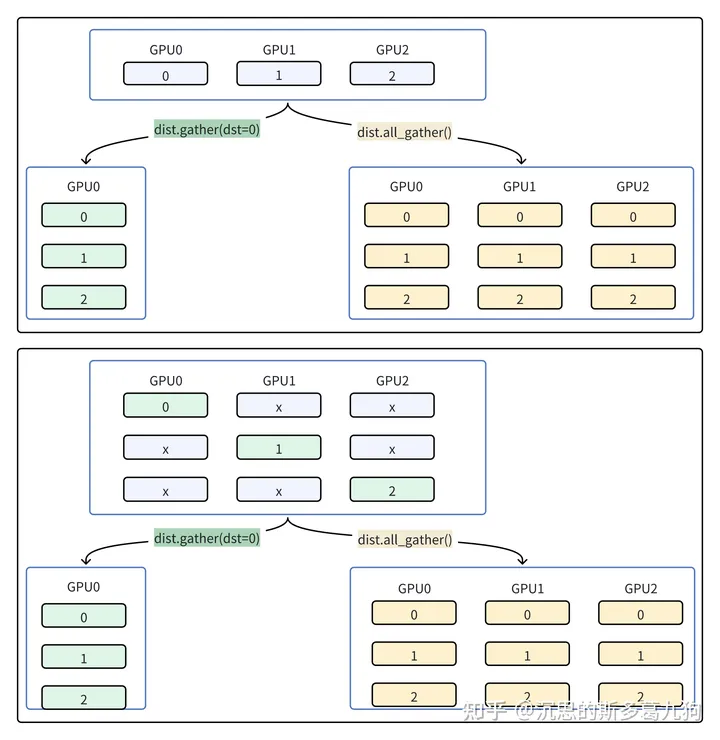
1.2.3 收集 gather
(1)gather:将各个显卡的数据进行收集,收集后的结果传给1个指定显卡。
torch.distributed.gather(tensor, gather_list=None, dst=0, group=None, async_op=False)
方法参数:
- tensor:Tensor,输入
- gather_list:
- 指定dst rank:list[Tensor],输出(收集结果),len(list) == world_size
- 非指定dst rank:None
(2)all-gather: 将各个显卡的数据进行收集,收集后的结果传给所有显卡。
torch.distributed.all_gather(tensor_list, tensor, group=None, async_op=False)
方法参数:
- tensor_list:list[Tensor],输出(收集结果)。len(list) == world_size
- tensor:Tensor,输入
代码实现
def run_gather(rank,world_size):
group=dist.new_group(ranks=list(range(world_size)))
input_ = torch.tensor(rank).to(torch.device(“cuda”, rank))
dst_rank=0
print (f”before,rank num is {rank}, input_:{input_} \n”)
if rank == dst_rank:
gather_list = [torch.tensor(0,device=“cuda:%d”%dst_rank) for _ in range(world_size)]
print (f”before,rank num is {rank}, gather_list:{gather_list} \n”)
else:
gather_list=None
dist.gather(tensor=input_, gather_list=gather_list, dst=dst_rank, group=group)
print (f”after gather,rank num is {rank}, gather_list:{gather_list} \n”)
def run_all_gather(rank,world_size):
group=dist.new_group(ranks=list(range(world_size)))
input_ = torch.tensor(rank).to(torch.device(“cuda”, rank))
tensor_list = [torch.empty_like(input_) for _ in range(world_size)]
tensor_list[rank]=input_
print (f”before,rank num is {rank}, input_:{input_} \n”)
dist.all_gather(tensor_list=tensor_list,tensor=input_,group=group)
print (f”after all_gather,rank num is {rank}, tensor_list:{[i.item() for i in tensor_list]} \n”)
打印结果
before,rank num is 1, input_:1 before,rank num is 2, input_:2 before,rank num is 0, input_:0
before,rank num is 0, gather_list:[tensor(0, device=‘cuda:0’), tensor(0, device=‘cuda:0’), tensor(0, device=‘cuda:0’)]
after gather,rank num is 0, gather_list:[tensor(0, device=‘cuda:0’), tensor(1, device=‘cuda:0’), tensor(2, device=‘cuda:0’)] after gather,rank num is 2, gather_list:None after gather,rank num is 1, gather_list:None
before,rank num is 1, input_:1 before,rank num is 2, input_:2 before,rank num is 0, input_:0
after all_gather,rank num is 1, tensor_list:[0, 1, 2] after all_gather,rank num is 2, tensor_list:[0, 1, 2] after all_gather,rank num is 0, tensor_list:[0, 1, 2]
1.2.4 分发 scatter
将scatter_list 列表中的第 i 个张量(tensor)发送到第 i 个进程中
torch.distributed.scatter(tensor, scatter_list=None, src=0, group=None, async_op=False)
方法参数:
- tensor:Tensor,输出(分发结果)
- scatter_list:src
- 指定src rank:list[Tensor],输入,要分发的数据,len(list) == world_size
- 非指定src rank:None
- src:源 src rank
gather与scatter操作相反。
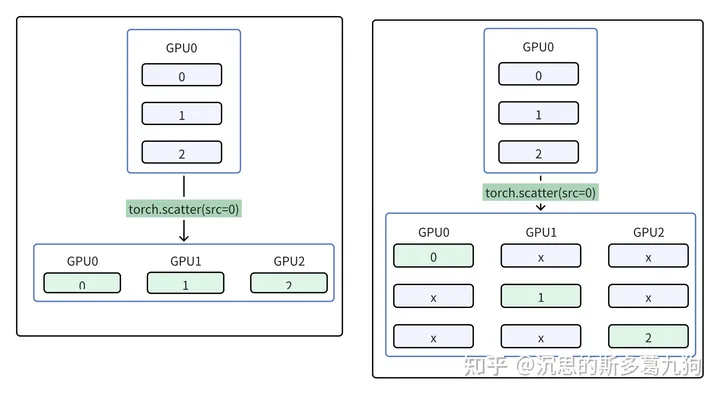
代码实现
def run_scatter(rank,world_size):
group = dist.new_group(ranks=list(range(world_size)))
src_rank =0
output_tensor= torch.tensor(0).to(torch.device(“cuda”, rank))
if rank==src_rank:
input_list = [torch.tensor(i).to(torch.device(“cuda”, rank)) for i in range(world_size)]
print (f”before scatter input_list:{[i.item() for i in input_list]} \n”)
else:
input_list=None
dist.scatter(tensor=output_tensor, scatter_list=input_list,src=src_rank,group=group)
print(f”after scatter rank num is {rank},output_tensor is {output_tensor} \n”)
打印结果
before scatter input_list:[tensor(0, device=‘cuda:0’), tensor(1, device=‘cuda:0’), tensor(2, device=‘cuda:0’)]
after scatter rank num is 1,output_tensor is 1after scatter rank num is 0,output_tensor is 0after scatter rank num is 2,output_tensor is 2
1.2.5 规约分发 reduce_scatter
将各个显卡的数据进行规约,将规约后的结果告诉所有显卡,但每张显卡只得到了一部分结果。
reduce_scatter = reduce + scatter
torch.distributed.reduce_scatter(output, input_list, op=<RedOpType.SUM: 0>, group=None, async_op=False)
方法参数:
- output:Tensor,输出(分发结果)
- input_list:list[Tensor], 输入,len(list) == world_size
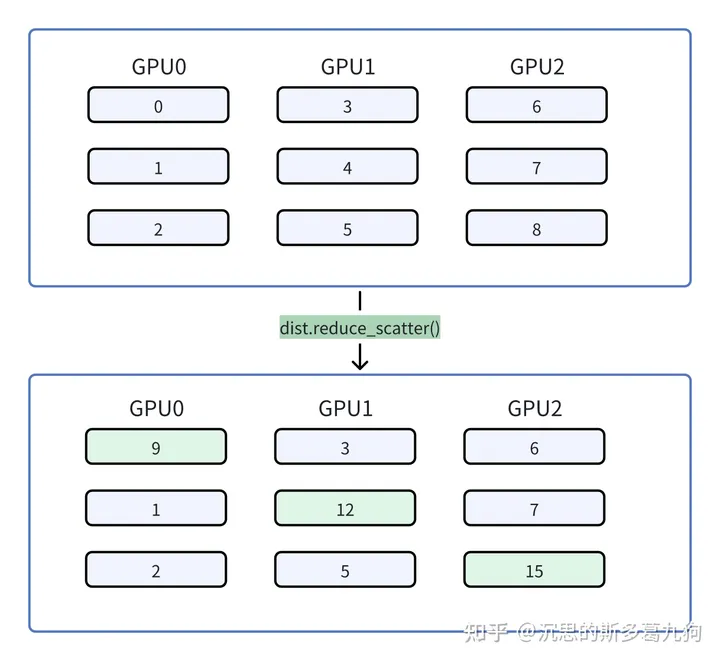
代码实现
def run_reduce_scatter(rank,world_size):
group = dist.new_group(ranks=list(range(world_size)))
output_tensor = torch.tensor(0).to(torch.device(“cuda”, rank))
input_list = [torch.tensor(3*rank).to(torch.device(“cuda”,rank)),torch.tensor(3*rank+1).to(torch.device(“cuda”,rank)),torch.tensor(3*rank+2).to(torch.device(“cuda”,rank))]
print (f”before reduce_scatter,rank num is {rank}, input_list:{[i.item() for i in input_list]} \n”)
dist.reduce_scatter(output=output_tensor,input_list=input_list, op=dist.ReduceOp.SUM, group=group)
print (f”after reduce_scatter ,rank num is {rank}, output_tensor:{output_tensor} \n”)
打印结果
before reduce_scatter,rank num is 1, input_list:[3, 4, 5]before reduce_scatter,rank num is 0, input_list:[0, 1, 2]before reduce_scatter,rank num is 2, input_list:[6, 7, 8]
after reduce_scatter ,rank num is 0, output_tensor:9 (0+3+6)after reduce_scatter ,rank num is 1, output_tensor:12 (1+4+7)after reduce_scatter ,rank num is 2, output_tensor:15 (2+5+8)
参考文章
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/collectives.html














暂无评论内容