
分布式训练topic由以下几部分组成:
1、背景
1.1 符号说明
p:流水线并行大小,对应get_pipeline_model_parallel_world_size()、pipeline_model_parallel_size
t:张量并行大小,对应get_tensor_model_parallel_world_size()、 tensor_model_parallel_size
d:数据并行大小,对应get_data_parallel_world_size()、data_parallel_size
N:GPU总个数, p*t*d=N
bs:全局的batch size大小
1.2 3D并行
简介:数据并行+流水线并行+张量并行
原理:
- 首先,模型的各层首先被划分到不同的流水线阶段。
- 其次,把每个阶段的层通过模型并行进一步进行划分。
- 最后,采用ZeRO 支持的数据并行功能,进一步扩展训练规模。
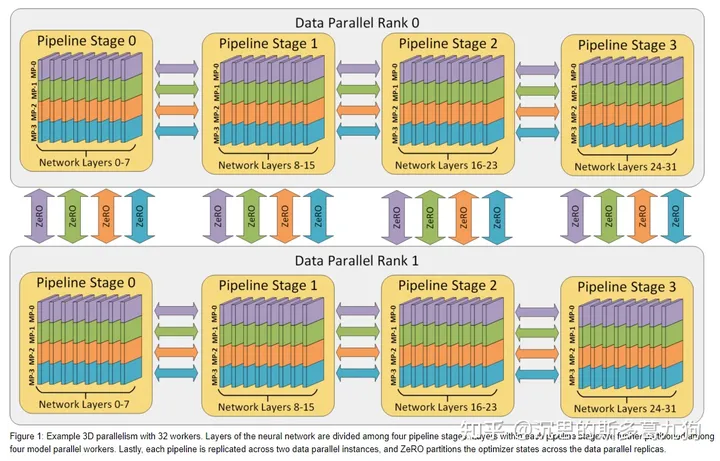
如下图所示:32 个worker的 3D 并行示例。模型的层被分为4个流水线阶段。每个流水线阶段内的层在4个张量并行worker之间进一步划分。最后,每个流水线阶段都跨2个数据并行实例进行复制,ZeRO 在这两个数据并行副本之间对优化器状态进行分区。
1.3 Megatron-LM简介
Megatron-LM由NVIDIA开发,用来训练Transformer模型,专攻张量并行和流水并行。
Microsoft开发的DeepSpeed,专攻零冗余优化器(ZeRO)和CPU卸载(CPU-offload)。
2、megatron-LM 源码分析
2.1 入口
pretrain()方法
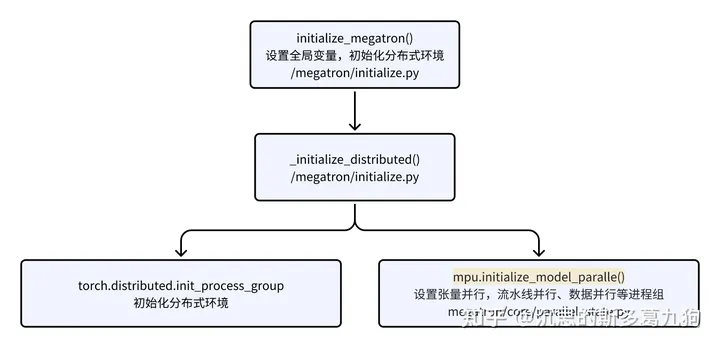
2.2 初始化
/megatron/initialize.py:初始化分布式环境。
/megatron/core/parallel_state.py:设置/获取/判断每个rank的所属进程组。后续的分布式操作算子(eg:torch.distributed.all_reduce)都在进程组进行。
2.2.1 初始化进程组
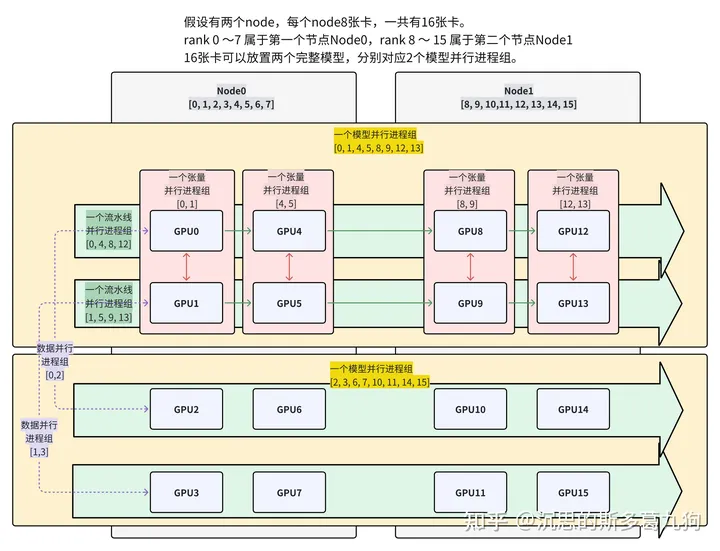
整体思路:d*p*t=N
3D并行实验配置如下:
- 2个Node,每个Node有8张卡,总卡数N=16
- 数据并行数d=2、流水线并行数p=4、张量并行数t =2
全局进程组如下:
全局进程组如下:
(1)_TENSOR_MODEL_PARALLEL_GROUP :当前 rank 所属于的张量并行进程组。
-
- 8个张量并行进程组:[0, 1], [2, 3], [4, 5], [6, 7], [8, 9], [10, 11], [12, 13], [14, 15]。
- TP的组数:8 = N/t = 16/2
(2)_PIPELINE_MODEL_PARALLEL_GROUP :当前 rank 所属于的流水线进程组。
-
- 4个流水线进程组:[0, 4, 8, 12], [1, 5, 9, 13], [2, 6, 10, 14], [3, 7, 11, 15]。
- PP的组数:4 = N/p = 16/4
(3)_MODEL_PARALLEL_GROUP :当前 rank 所属于的模型并行进程组(和数据并行数一致,完整模型被复制了X份)
-
- 2个模型并行进程组:[0, 1, 4, 5, 8, 9, 12, 13],[2, 3, 6, 7, 10, 11, 14, 15]
(4)_DATA_PARALLEL_GROUP :当前 rank 所属于的数据并行进程组。
-
- 8个数据并行进程组:[0, 2], [1, 3], [4, 6], [5, 7], [8, 10], [9, 11], [12, 14], [13, 15]。
- DP的组数:8 = N/d = 16/2
(5)_EMBEDDING_GROUP : embedding对应的进程组。
代码实现:
import torch
# t * p 就是一个模型所需要的 GPU# 数据并行 d = 总GPU个数 / (一个模型需要的GPU) = n / (t*p)world_size = 16tensor_model_parallel_size = 2 # 2 GPUs to parallelize the model tensorpipeline_model_parallel_size = 4 # 4 GPUs to parallelize the model pipeline## 根据TP_size和PP_size,求出DP_sizedata_parallel_size = world_size // (tensor_model_parallel_size *
pipeline_model_parallel_size) # 2#TP的组数num_tensor_model_parallel_groups = world_size // tensor_model_parallel_size # 8#PP的组数num_pipeline_model_parallel_groups = world_size // pipeline_model_parallel_size # 4#DP的组数num_data_parallel_groups = world_size // data_parallel_size # 8
# Build the data-parallel groups.print(“—— 创建 数据并行组 —–“)all_data_parallel_group_ranks = []for i in range(pipeline_model_parallel_size):
start_rank = i * num_pipeline_model_parallel_groups
end_rank = (i + 1) * num_pipeline_model_parallel_groups
for j in range(tensor_model_parallel_size):
ranks = range(start_rank + j, end_rank,
tensor_model_parallel_size)
all_data_parallel_group_ranks.append(list(ranks))print(all_data_parallel_group_ranks)
# Build the model-parallel groups.print(“—— 创建 模型并行组 —–“)for i in range(data_parallel_size):
ranks = [data_parallel_group_ranks[i]
for data_parallel_group_ranks in all_data_parallel_group_ranks]
print(list(ranks))
# Build the tensor model-parallel groups.print(“—— 创建 张量并行组 —–“)for i in range(num_tensor_model_parallel_groups):
ranks = range(i * tensor_model_parallel_size,
(i + 1) * tensor_model_parallel_size)
print(list(ranks))
# Build the pipeline model-parallel groups and embedding groups# (first and last rank in each pipeline model-parallel group).print(“—— 创建 流水线并行组 —–“)for i in range(num_pipeline_model_parallel_groups):
ranks = range(i, world_size,
num_pipeline_model_parallel_groups)
print(list(ranks))
打印结果
—— 创建 数据并行组 —–[[0, 2], [1, 3], [4, 6], [5, 7], [8, 10], [9, 11], [12, 14], [13, 15]]—— 创建 模型并行组 —–[0, 1, 4, 5, 8, 9, 12, 13][2, 3, 6, 7, 10, 11, 14, 15]—— 创建 张量并行组 —–[0, 1][2, 3][4, 5][6, 7][8, 9][10, 11][12, 13][14, 15]—— 创建 流水线并行组 —–[0, 4, 8, 12][1, 5, 9, 13][2, 6, 10, 14][3, 7, 11, 15]
2.2.2 全局参数
获得p/t/d:每个进程组中rank的个数。
#流水线并行大小p=4def get_pipeline_model_parallel_world_size():
“””Return world size for the pipeline model parallel group.”””
global _MPU_PIPELINE_MODEL_PARALLEL_WORLD_SIZE
if _MPU_PIPELINE_MODEL_PARALLEL_WORLD_SIZE is not None:
return _MPU_PIPELINE_MODEL_PARALLEL_WORLD_SIZE
return torch.distributed.get_world_size(group=get_pipeline_model_parallel_group())
#张量并行大小t=2def get_tensor_model_parallel_world_size():
“””Return world size for the tensor model parallel group.”””
global _MPU_TENSOR_MODEL_PARALLEL_WORLD_SIZE
if _MPU_TENSOR_MODEL_PARALLEL_WORLD_SIZE is not None:
return _MPU_TENSOR_MODEL_PARALLEL_WORLD_SIZE
return torch.distributed.get_world_size(group=get_tensor_model_parallel_group())
#数据并行大小d=2def get_data_parallel_world_size():
“””Return world size for the data parallel group.”””
return torch.distributed.get_world_size(group=get_data_parallel_group())
#模型并行大小–>张量并行大小def get_model_parallel_world_size():
assert get_pipeline_model_parallel_world_size() == 1, “legacy get_model_parallel_world_size is only supported if PP is disabled”
return get_tensor_model_parallel_world_size()
获得当前rank所属的group:在进程组内进行通信。
#流水线并行进程组groupdef get_pipeline_model_parallel_group():
“””Get the pipeline model parallel group the caller rank belongs to. 4个流水线并行组: [0, 4, 8, 12] [1, 5, 9, 13] [2, 6, 10, 14] [3, 7, 11, 15] 返回当前rank所处的PP进程组:[0, 4, 8, 12] “””
return _PIPELINE_MODEL_PARALLEL_GROUP
#张量并行进程组group def get_tensor_model_parallel_group(check_initialized=True):
“””Get the tensor model parallel group the caller rank belongs to.”””
return _TENSOR_MODEL_PARALLEL_GROUP
#数据并行进程组group def get_data_parallel_group():
“””Get the data parallel group the caller rank belongs to.”””
return _DATA_PARALLEL_GROUP
#模型并行进程组group def get_model_parallel_group():
“””Get the model parallel group the caller rank belongs to.”””
return _MODEL_PARALLEL_GROUP
获取当前rank所属group的local rank:
def get_pipeline_model_parallel_rank():
“””Return my rank for the pipeline model parallel group. 当前rank4所处的PP进程组:[0, 4, 8, 12] 返回local rank = 1 “””
global _MPU_PIPELINE_MODEL_PARALLEL_RANK
if _MPU_PIPELINE_MODEL_PARALLEL_RANK is not None:
return _MPU_PIPELINE_MODEL_PARALLEL_RANK
return torch.distributed.get_rank(group=get_pipeline_model_parallel_group())
2.3 模型初始化
获得megatron版本的并行模型model、优化器optimizer、lr_schedual。
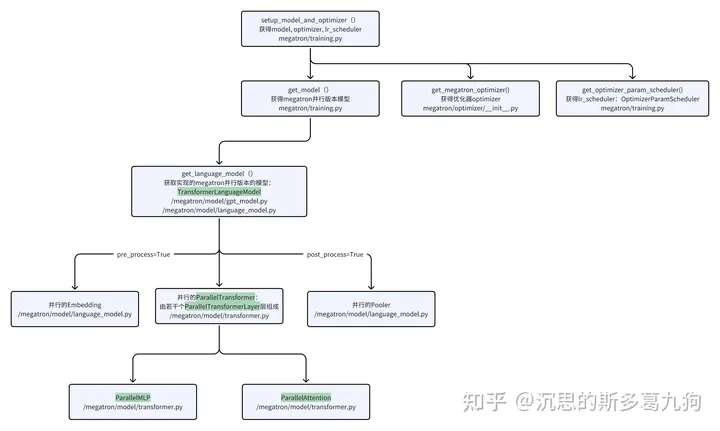
2.3.1 模型初始化
更多模型结构介绍见:LLM训练07 张量并行
2.3.2 优化器初始化
LLM训练,默认采用混合精度训练( fp16 或者bf16 ),返回Float16OptimizerWithFloat16Params
源码位置:/megatron/optimizer/optimizer.py
2.4 数据初始化
获得训练、验证、测试数据集。
在张量并行中,各个GPU用的是同一份数据,需要将src显卡即rank0的数据广播给其他rank。
#将数据flag是从src rank广播给张量并行进程组torch.distributed.broadcast(flags,
get_tensor_model_parallel_src_rank(),
group=get_tensor_model_parallel_group())
2.4.1 对数据进行预处理
源码:/tools/preprocess_data.py
简介:对数据进行tokenizer、向量化、shuffle 并处理成二进制格式(Megatron-LM数据格式)以进行训练。
相关参数:
- workers 数据预处理中使用的线程数量
- chunk_size : 数据预处理中分配给每个线程的数据块大小。
- input :输入数据的文件名,每一行是一条json文件。eg:{“text”: [“句子1″,”句子2”]}
- json-keys :输入json数据的key名称。eg:上文为“text”
- append-eod:每篇文档结尾会加入文档结束符:<|endoftext|> or eos_token_id
- tokenizer-type:tokenizer类型,目前不支持中文LLM对应的tokenizer,需要个人实现处理。
-
dataset-impl 指的是索引数据集的实现方式,可选项有: [‘lazy’, ‘cached’, ‘mmap’]。
- ‘mmap’–>MMapIndexedDatasetBuilder
- ‘lazy’ 或者 ‘cached’ –> IndexedDatasetBuilder
生成以下两个文件用于模型训练:
(1)megatron_text_document.bin:文档token_id的numpy的数组。
(2)megatron_text_document.idx:每篇文档的句子个数,每个句子的token个数。
python tools/preprocess_data.py \
–input input_data.json \
–output-prefix megatron \
–vocab vocab.json \
–dataset-impl mmap \
–tokenizer-type GPT2BPETokenizer \
–merge-file merges.txt \
–json-keys text \
–workers 8 \
–chunk-size 25 \
–append-eod
# megatron_text_document.bin
“{}_{}_{}.bin”.format(output_prefix,key, level)
# megatron_text_document.idx
“{}_{}_{}.idx”.format(output_prefix,key, level)
2.5 模型训练
常规的模型训练流程:
在流水线并行,需要 schedule 如何具体训练。更多详情见:LLM训练06 流水线并行
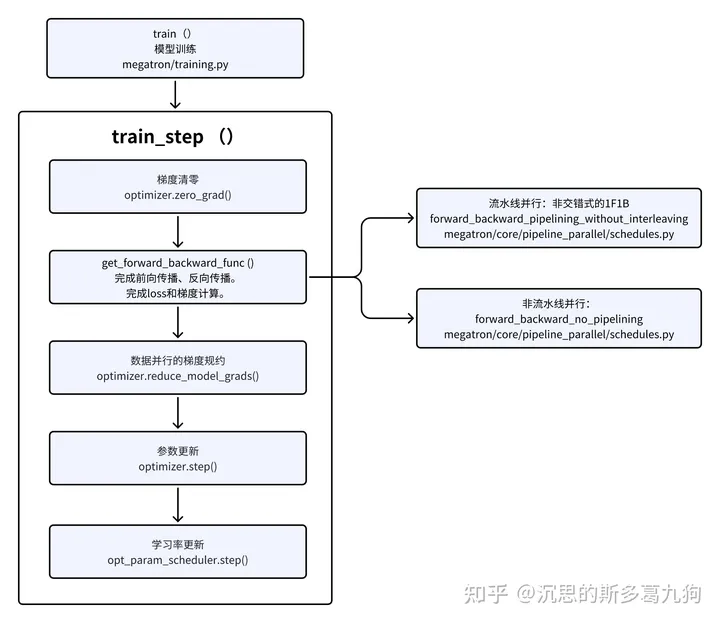














暂无评论内容