一、开发背景
残差神经网络(ResNet)是由微软研究院的何恺明、张祥雨、任少卿、孙剑等人提出的, 斩获2015年ImageNet竞赛中分类任务第一名, 目标检测第一名。残差神经网络的主要贡献是发现了“退化现象(Degradation)”,并针对退化现象发明了 “直连边/短连接(Shortcut connection)”,极大地消除了深度过大的神经网络训练困难问题。神经网络的“深度”首次突破了100层、最大的神经网络甚至超过了1000层。在正式讲解之前,我为大家整理了计算机视觉方向的顶级会议CVPR最前沿的98篇论文(持续更新),包含了目前放榜的所有优质论文。不仅可以为你提供新的研究方向,启发论文创新点,还能帮你快速了解领域的发展情况,前沿主流方法和具体技术实现细节,并且每篇论文都能直接复现,包含的代码都可以直接跳转。

1.根据上述内容,引出问题,什么是退化现象?随着CNN的发展和普及,人们发现增加神经网络的层数可以提高训练精度,但是如果只是单纯的增加网络的深度,可能会出现“梯度弥散”和“梯度爆炸”等问题。传统的解决方法则是权重的初始化(normalized initializatiton)和批标准化(batch normlization),虽然解决了梯度问题,但是深度加深了,却带来了另外的问题,就是网络性能的退化现象,可以简单的理解为,随着训练轮数(epoch)的增加,精度到达一定程度后,就开始下架了。
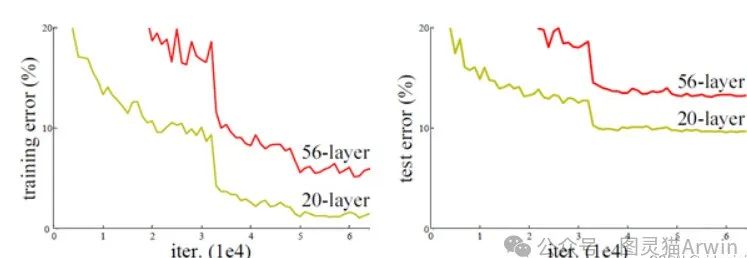
由上图可以看出,56层的神经网络比22层的神经网络在训练集和测试集的准确率都要差得多,也就是所说的退化现象。如果只是简单的增加网络的深度,可能会导致神经网络模型退化,进而丢失网络前面获取的特征。假如当层数为40层的时候已经达到了最佳的模型,然后继续增加网络的层数,因为激活函数以及卷积等效果,只会增加整体(网络)的非线性,所以效果会变得更差。该现象的实质:通过多个非线性层来近似恒等映射可能是困难的(恒等映射亦称恒等函数:是一种重要的映射,对任何元素,象与原象相同的映射)。随着网络层数的增多,而我们优化参数需要反向传播,这一过程会不断地传播梯度,但是假设在层数较深的位置梯度很小或者很大,那么传到浅层的时候是不是就会变得非常小,那样还能优化参数吗?也就导致了无法有效地对前面网络进行有效调整。从信息论的角度讲,由于DPI(数据处理不等式)的存在,在前向传输的过程中,随着层数的加深,Feature Map包含的图像信息会逐层减少,而ResNet的直接映射的加入,保证了 l+1 层的网络一定比 l 层包含更多的图像信息。基于这种使用直接映射来连接网络不同层直接的思想,残差网络应运而生。2.为什么深度过大而神经网络难以训练?原因也很简单,主要就是出现了梯度消失和梯度爆炸的现象。其他原因比如说是计算资源的消耗,这类原因可以通过GPU集群来解决,而过拟合的问题,可以通过采集海量的数据集和Dropout正则化可以有效解决,梯度消失和爆炸虽然也可以利用Batch Normalization解决,但根据实验发现并不如人愿望。Batch Normalization(批量归一化):由Google在2015年提出,是近年来DL(深度学习)领域最重要的进步之一。该方法依靠两次连续的线性变换,希望转化后的数值满足一定的特性(分布),不仅可以加快了模型的收敛速度,也一定程度缓解了特征分布较散的问题,使深度神经网络(DNN)训练更快、更稳定。具体的过程就是通过方法将该层的特征值分布重新拉回到标准正态分布,特征值降落在激活函数对于输入较为敏感的区间,输入的小变化可导致损失函数较大的变化,使得梯度变大,避免梯度消失,同时也可加快收敛。
 梯度消失:我们知道神经网络在进行反向传播(BP算法)的时候会对参数W进行更新,梯度消失就是靠后面网络层(如layer3)能够正常的得到一个合理的偏导数,但是靠近输入层的网络层,计算的到的偏导数近乎零,W几乎无法得到更新。原因:反向传播的时候的链式法则,越是浅层的网络,其梯度表达式可以展现出来连乘的形式,而这样如果都是小于1的,这样的话,浅层网络参数值的更新就会变得很慢,这就导致了深层网络的学习就等价于了只有后几层的浅层网络的学习了。梯度爆炸:靠近输入层的网络层,计算得到的偏导数极其大,更新后W变成一个很大的数(爆炸)。原因:类似于上述的原因,假如都是大于1的时候,那么浅层的网络的梯度过大,更新的参数变量也过大,所以无论是梯度消失还是爆炸都是训练过程会十分曲折的,都应该尽可能避免。
梯度消失:我们知道神经网络在进行反向传播(BP算法)的时候会对参数W进行更新,梯度消失就是靠后面网络层(如layer3)能够正常的得到一个合理的偏导数,但是靠近输入层的网络层,计算的到的偏导数近乎零,W几乎无法得到更新。原因:反向传播的时候的链式法则,越是浅层的网络,其梯度表达式可以展现出来连乘的形式,而这样如果都是小于1的,这样的话,浅层网络参数值的更新就会变得很慢,这就导致了深层网络的学习就等价于了只有后几层的浅层网络的学习了。梯度爆炸:靠近输入层的网络层,计算得到的偏导数极其大,更新后W变成一个很大的数(爆炸)。原因:类似于上述的原因,假如都是大于1的时候,那么浅层的网络的梯度过大,更新的参数变量也过大,所以无论是梯度消失还是爆炸都是训练过程会十分曲折的,都应该尽可能避免。
 3.残差网络解决的问题神经网络越来越深的时候,反传回来的梯度之间的相关性会越来越差,最后接近白噪声。图像具有局部相关性,可以认为梯度也应该具备类似的相关性,这样更新的梯度才有意义,如果梯度接近白噪声,那梯度更新可能根本就是在做随机扰动。基于这种退化问题,作者通过浅层网络等同映射构造深层模型,结果深层模型并没有比浅层网络有等同或更低的错误率,推断退化问题可能是因为深层的网络并不是那么好训练,也就是求解器很难去利用多层网络拟合同等函数。如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那当前要解决的就是学习恒等映射函数了。如果更深层次的网络都能够学习到恒等映射,那么准确率起码不会降低,所以这正是残差网络的解决的问题。
3.残差网络解决的问题神经网络越来越深的时候,反传回来的梯度之间的相关性会越来越差,最后接近白噪声。图像具有局部相关性,可以认为梯度也应该具备类似的相关性,这样更新的梯度才有意义,如果梯度接近白噪声,那梯度更新可能根本就是在做随机扰动。基于这种退化问题,作者通过浅层网络等同映射构造深层模型,结果深层模型并没有比浅层网络有等同或更低的错误率,推断退化问题可能是因为深层的网络并不是那么好训练,也就是求解器很难去利用多层网络拟合同等函数。如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那当前要解决的就是学习恒等映射函数了。如果更深层次的网络都能够学习到恒等映射,那么准确率起码不会降低,所以这正是残差网络的解决的问题。
二、残差块原理
一个残差块的数学模型如下图所示,残差网络和之前的网络最大的不同之处就是多了一条自身的捷径分支。正是因为这一个分支的存在,使得网络在反向传播的时候,损失可以通过这条捷径将梯度直接传向更前的网络,从而减缓网络退化问题,我们前边了解到梯度之间具有相关性的。我们在有个梯度相关性这个指标之后,作者分析了许多的结构和激活函数,发现了正是我们这个网络在保持梯度相关性上是很强的。除了这一点之外,残差网络并没有增加新的参数,只是多了一步加法,计算量相对而言也没有增加。
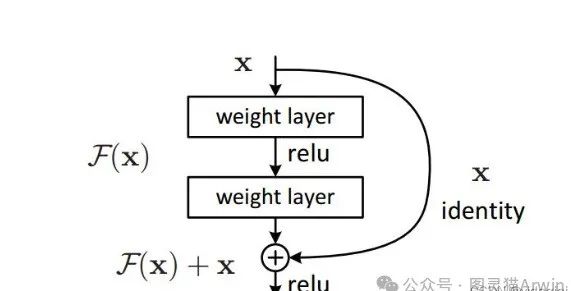
下边这句话就是我们可以转换为学习一个残差函数:F(x) = H(x)- x,主要F(x)= 0 就构成了一个恒等变换,而且拟合残差肯定更容易。
F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是:
F(5)′=5.1
引入残差后是:H(5)=5.1,H(5.1)=F(5)+5,F(5)=0.1
这里的F′和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如S输出从5.1变到5.2,映射的输出F′增加了2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化。
三、残差网络讨论
对以下6种结构(图2)的残差结构进行实验比较,shortcut是X/2的就是第二种,结果发现还是第一种效果好。
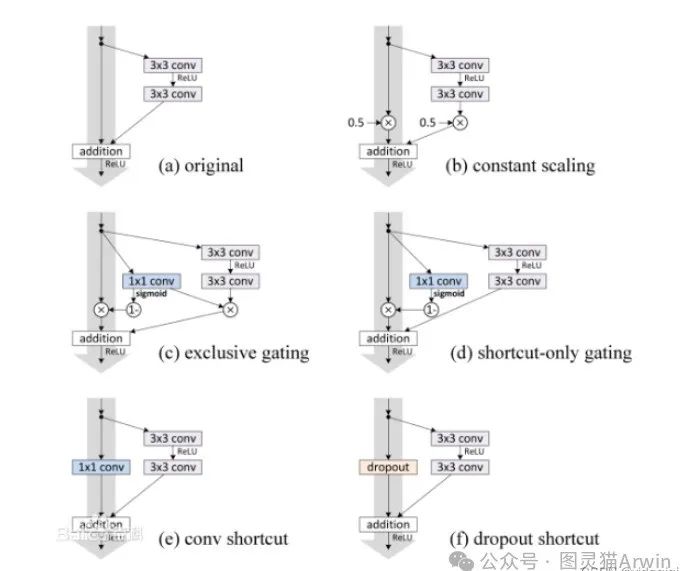
这种残差学习结构可以通过前向神经网络+shortcut连接实现,如结构图1所示。
而且shortcut连接相当于简单执行了同等映射,不会产生额外的参数,也不会增加计算复杂度。而且,整个网络可以依旧通过端到端的反向传播训练。
就是因为多个层在理论上可以拟合任何的函数,恒等函数仍然可以是用多层网络去拟合的,但是拟合残差函数相对来说比那种更加简单,也就是更加利于学习。这种残差形式是由退化问题激发的。根据前文,如果增加的层被构建为同等函数。那么理论上,更深的模型的训练误差不应当大于浅层模型,但是出现的退化问题表明,求解器很难去利用多层网络拟合同等函数。但是,残差的表示形式使得多层网络近似起来要容易的多,如果`同等函数可被优化近似,那么多层网络的权重就会简单地逼近0来实现同等映射,即 F(x)=0。网络结构:残差网络是由一系列的残差块加上一些其他层组成的,残差块由两部分组成直接映射部分和残差部分。

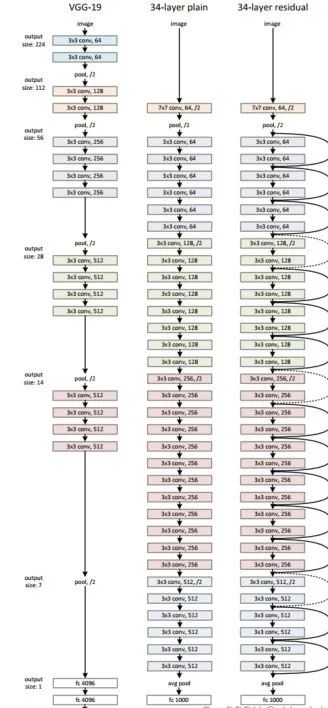
整体的网络塔尖分为两步:
使用VGG公式搭建Plain VGG网络
在Plain VGG的卷积网络之间插入Identity Mapping,注意需要升维或者降维的时候加入 1×1 卷积。
四、代码实现,我跑了一遍,然后有四个类别,效果很好
- spilit_data.py:划分给定的数据集为训练集和测试集
- model.py :定义ResNet网络模型
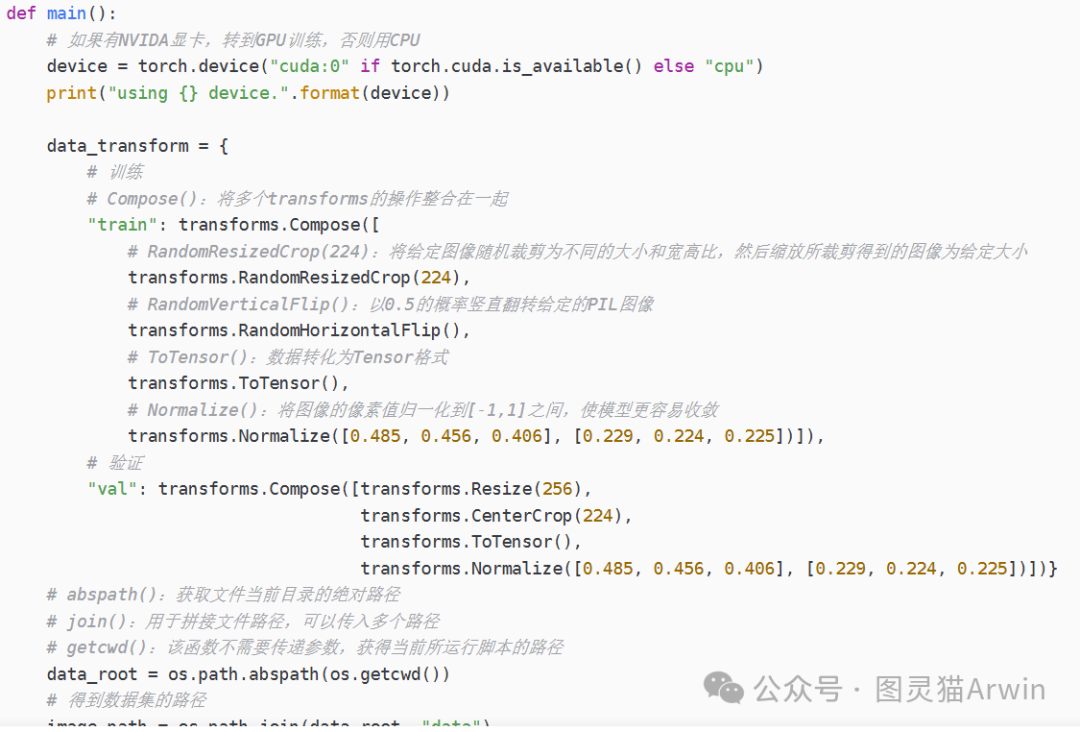
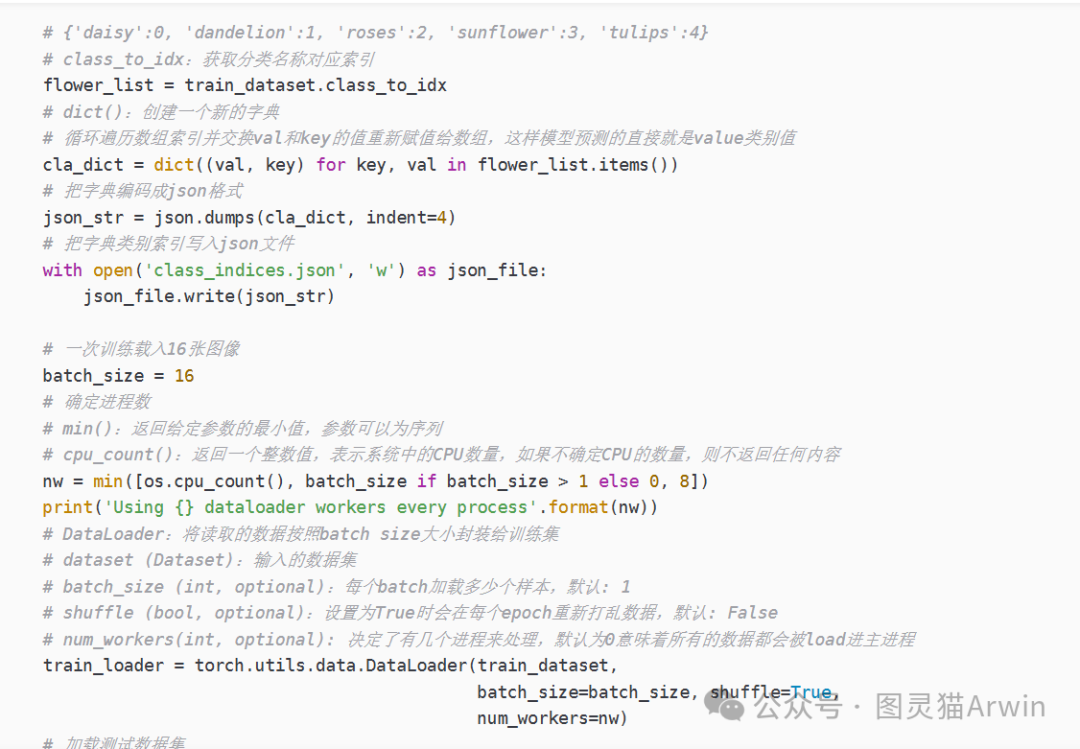
- train.py:加载数据集并训练,计算loss和accuracy,保存训练好的网络参数
- predict.py:用自己的数据集进行分类测试
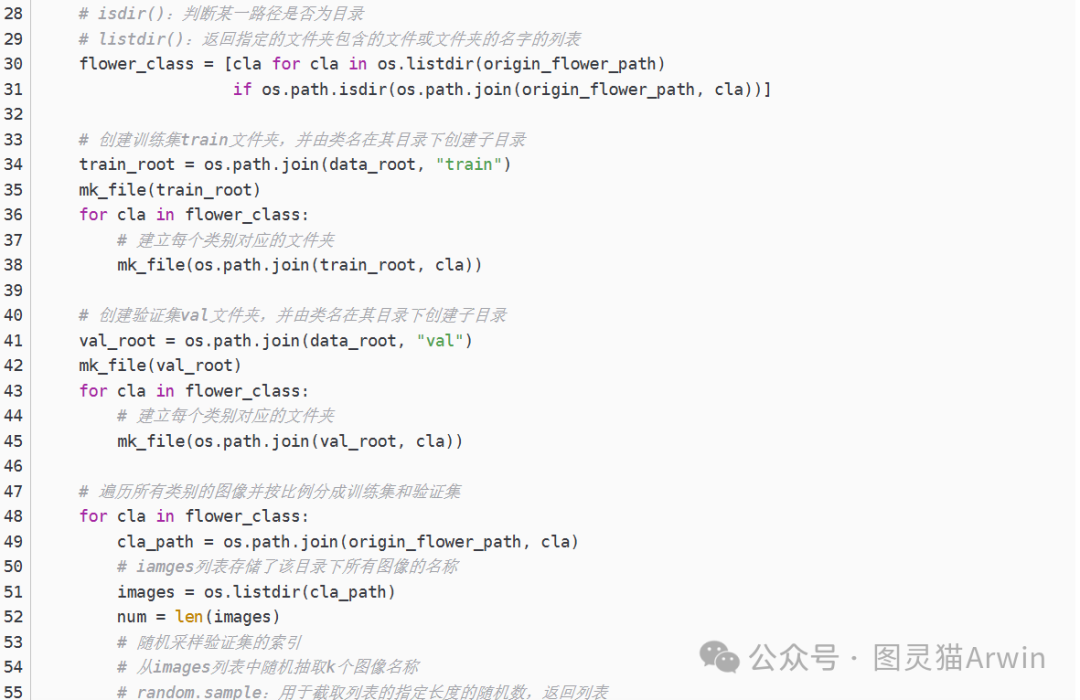
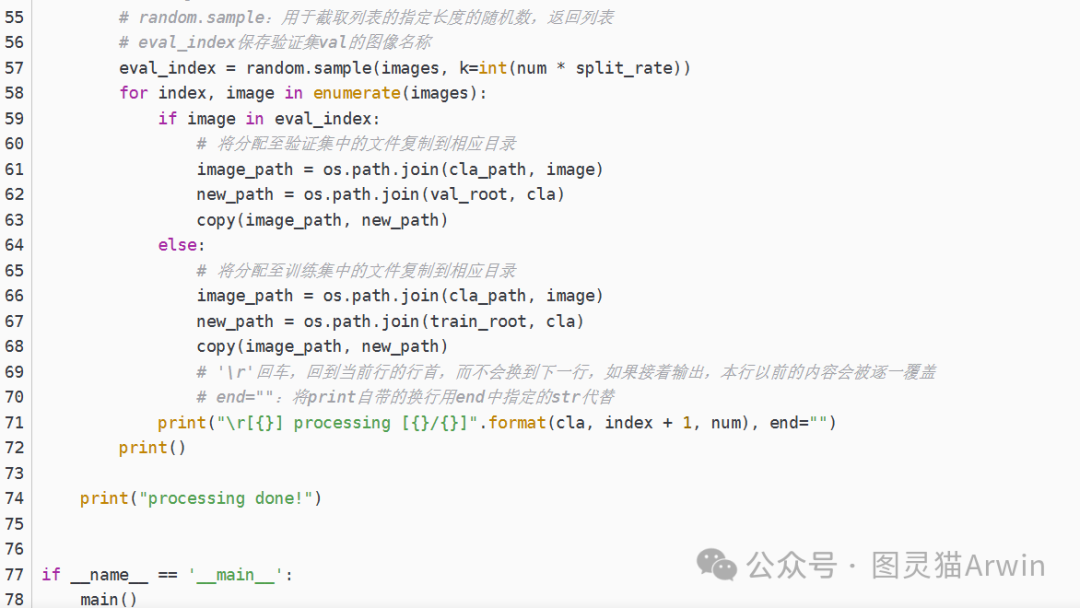
(1)spilit_data.py 实现数据集的划分,只有训练集和验证集的划分没有其他的
(2)model.py模型的构建
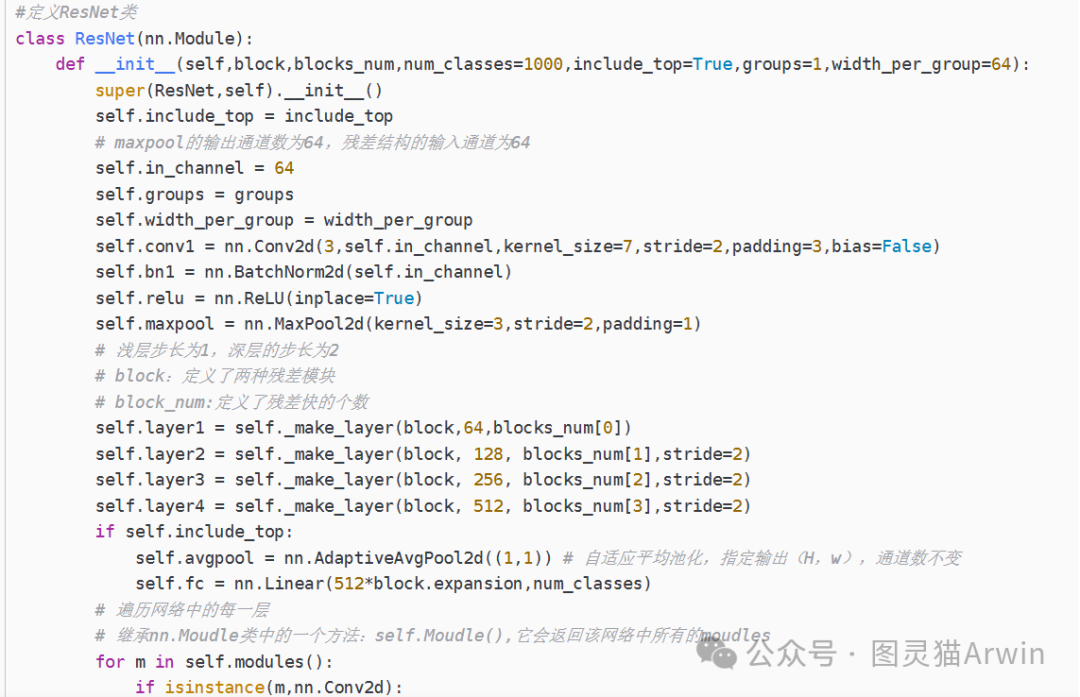
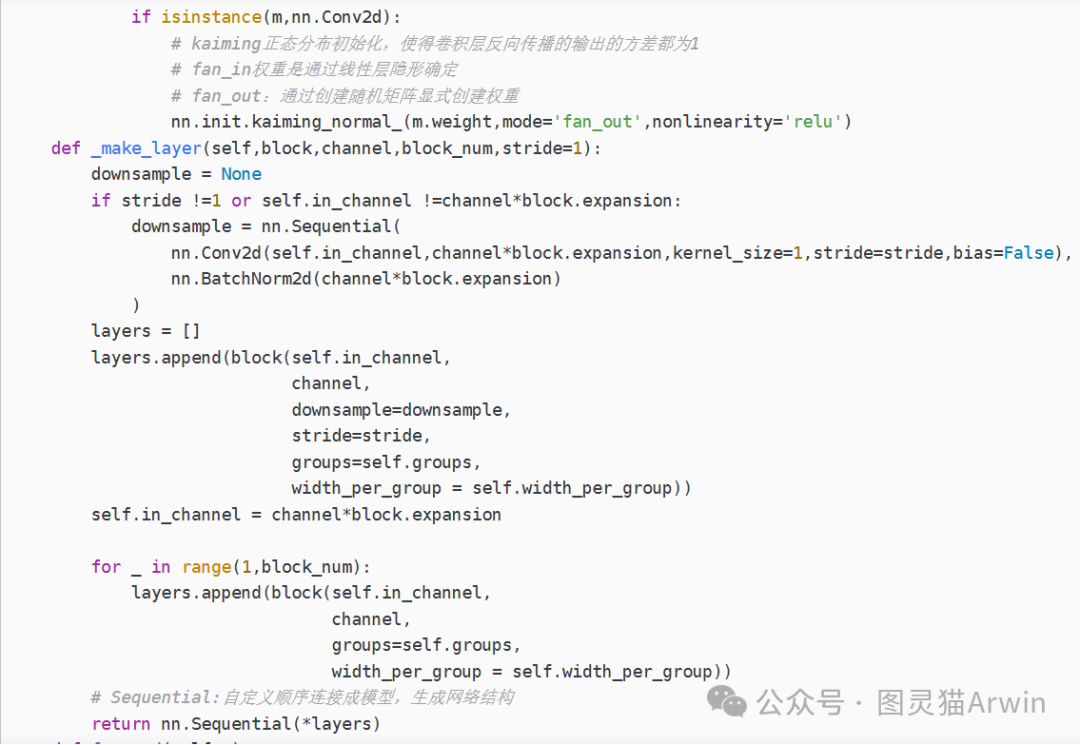
(3)利用模型进行训练
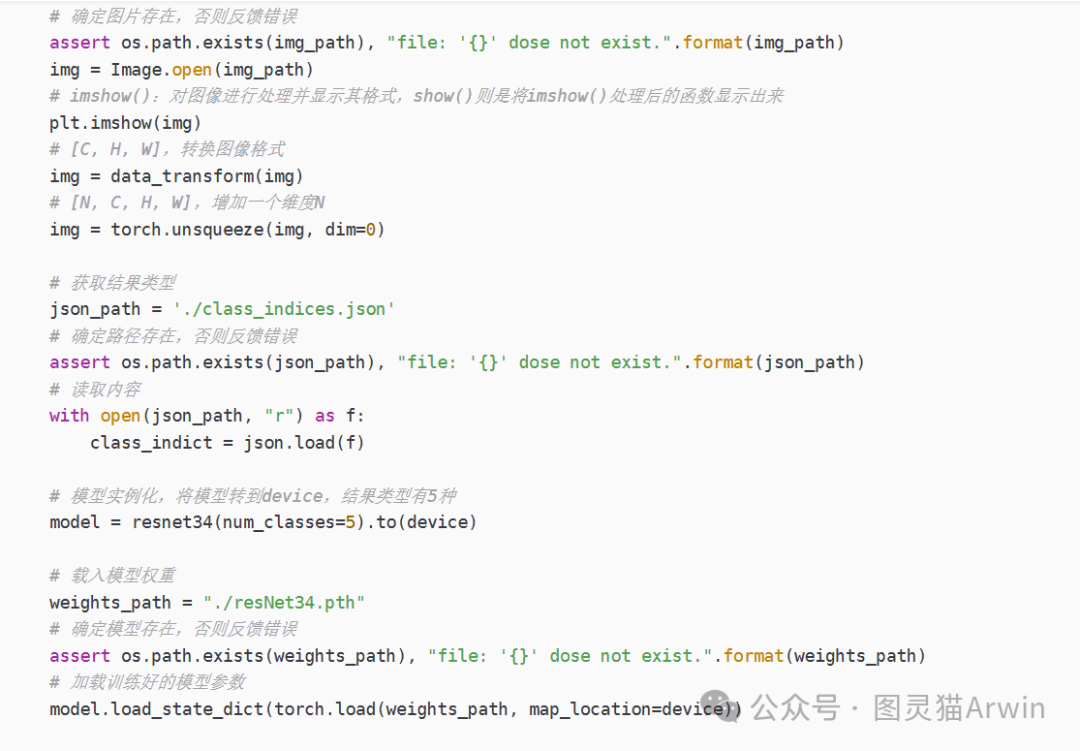
(4)预测图片
五、训练结果
1000多张训练集,四个类别,效果如下:















暂无评论内容