字节提出了一种名为LatentSync的端到端唇同步框架,它基于音频驱动的潜在扩散模型(latent diffusion models),完全摒弃了中间的动作表示。与之前的基于像素扩散或两阶段生成的唇同步方法不同,LatentSync可以直接利用Stable Diffusion的强大能力来建模复杂的音视频关联。
此外,发现基于扩散的唇同步方法由于不同帧的扩散过程不一致,通常在时间连贯性上表现较差。为了解决这个问题,提出了一个叫做时间表征对齐(Temporal REPresentation Alignment, 简称TREPA)的方法,能够在保证唇同步准确度的同时,显著提升时间上的连贯性。具体来说,TREPA通过大规模自监督视频模型提取的时间表征,将生成的帧与真实帧进行对齐,从而让生成结果更流畅、更自然。
01 技术原理
—
在唇动同步领域,基于 GAN 的方法仍然是主流方法。基于 GAN 的方法的主要问题是,由于训练不稳定和模式崩溃,它们在处理大型和多样化数据集时存在困难,难以扩展。最近的研究提出了基于扩散的方法,用于唇动同步,使得模型能够轻松地在不同个体之间进行泛化,而无需对特定身份进行进一步的微调。然而,这些方法仍然存在一些局限性。硬件要求过高,限制了其生成高分辨率视频的能力。
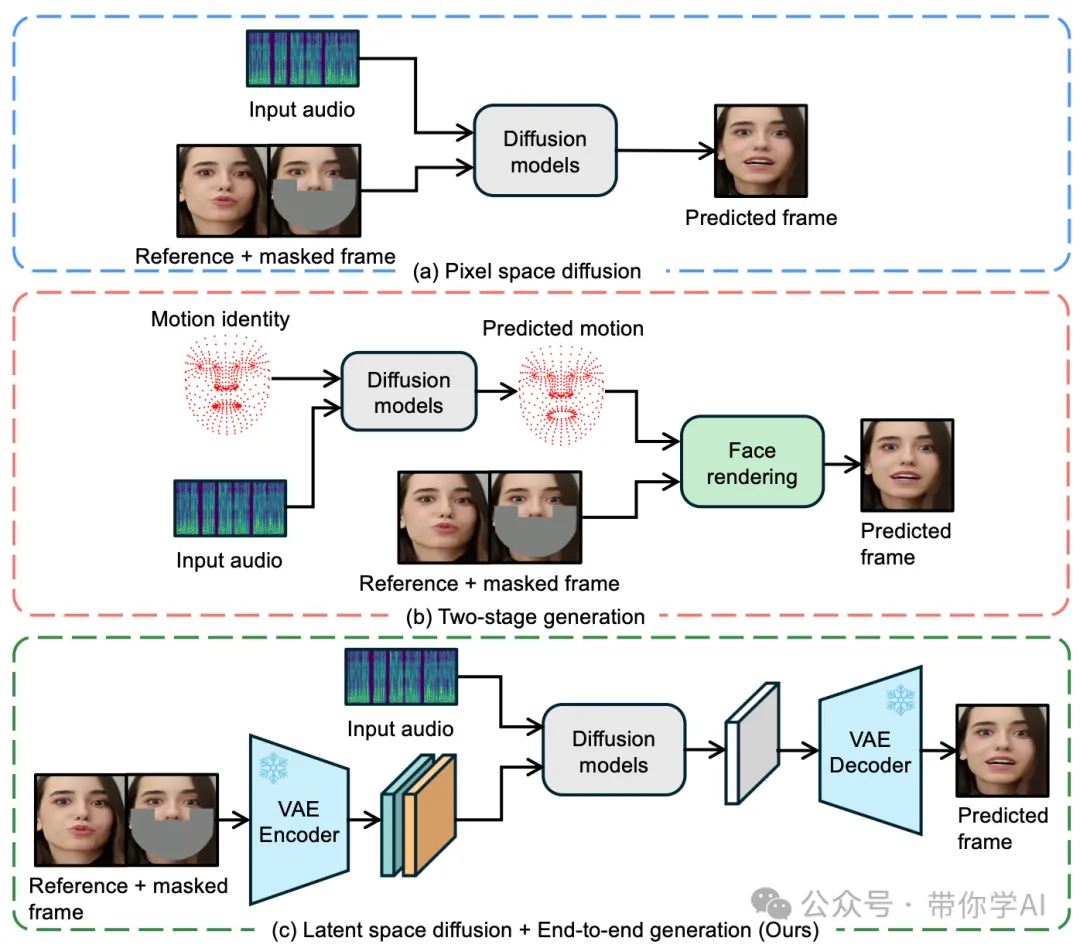
LatentSync 框架概述如下:使用 Whisper将梅尔频谱图转换为音频嵌入,然后通过交叉注意力层将其集成到 U-Net 中。参考帧和掩膜帧与带噪声的潜变量按通道级别拼接,作为 U-Net 的输入。在训练过程中,采用一步法从预测的噪声中获得估计的干净潜变量,然后解码得到估计的干净帧。在像素空间中加入了 TREPA、LPIPS和 SyncNet 损失。
02 演示效果
—
研究团队深入探讨了 SyncNet 的收敛问题,并通过大量实证研究,找出了影响 SyncNet 收敛的主要因素,这些因素包括模型架构、训练超参数和数据预处理方法。通过对这些因素进行优化,SyncNet 在 HDTF 测试集上的准确率从 91% 提升至 94%。
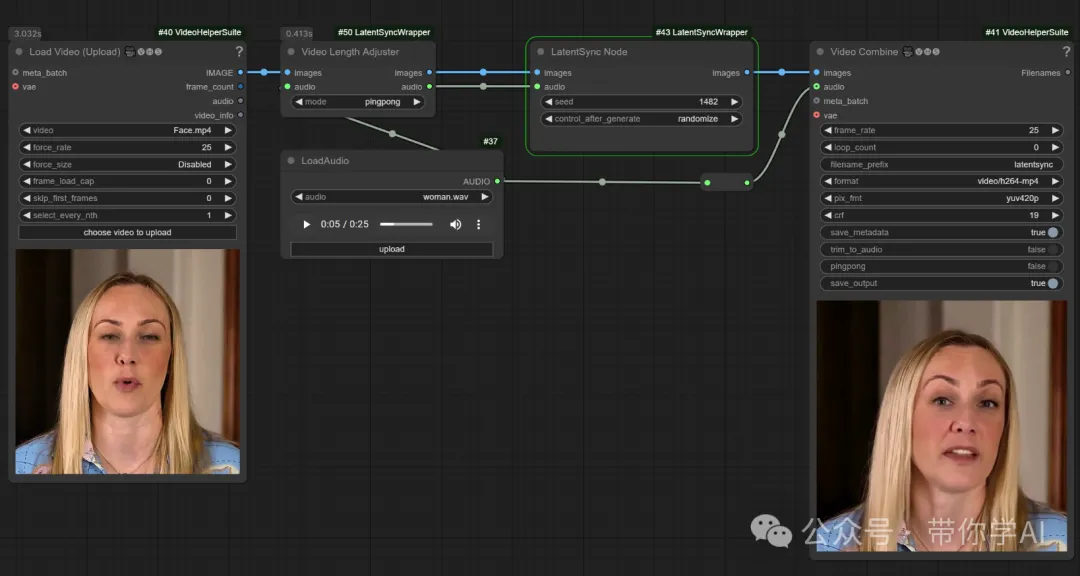
同时LatentSync也支持在线体验和ComfyUI,链接同样在文章底部。














暂无评论内容