MiniMax-Text-01和MiniMax-VL-01开源。
用到了线性注意力,所以在处理长输入的时候有非常高的效率,接近线性复杂度。支持4M上下文的大海捞针。
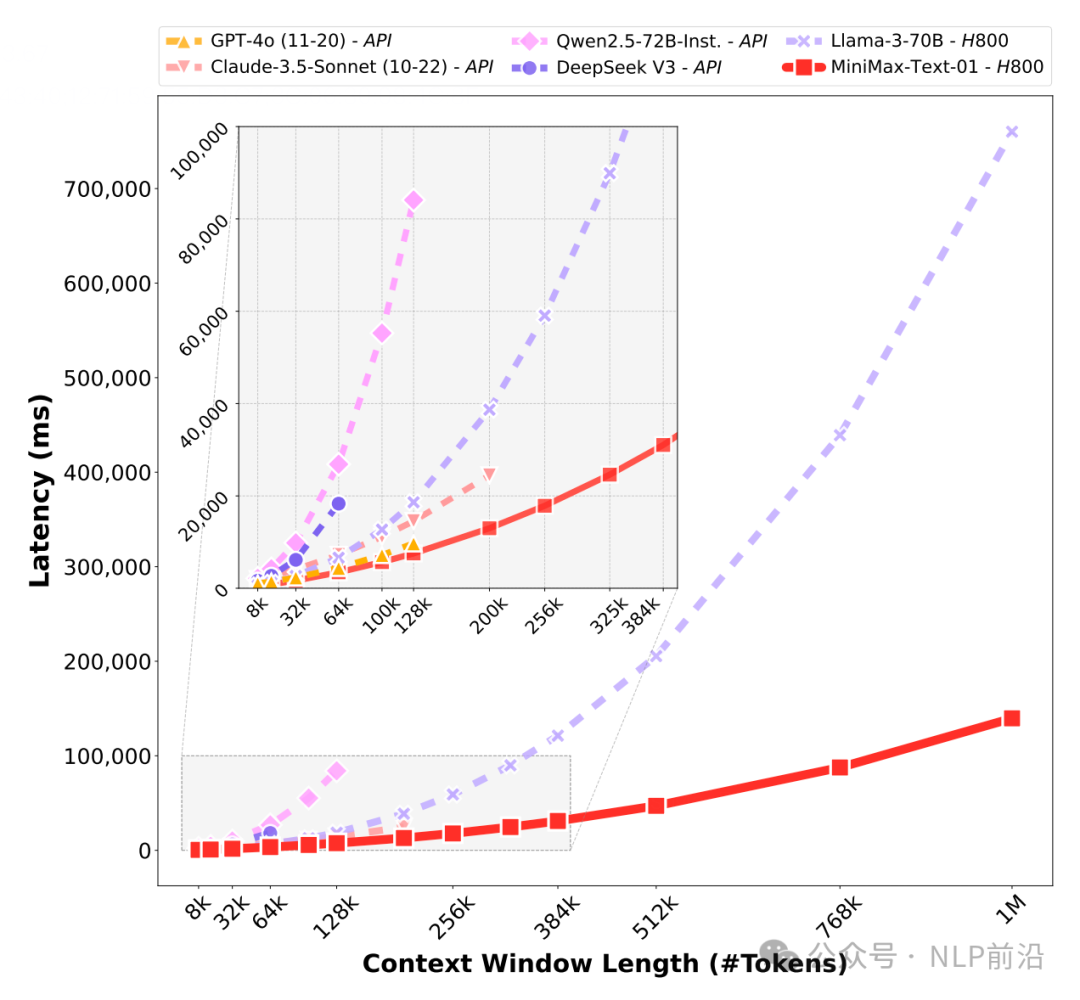
并且得益于新架构,所以推理更快,在其他模型处理256K tokens的时间,Minimax的模型可以处理高达1000k tokens的信息。
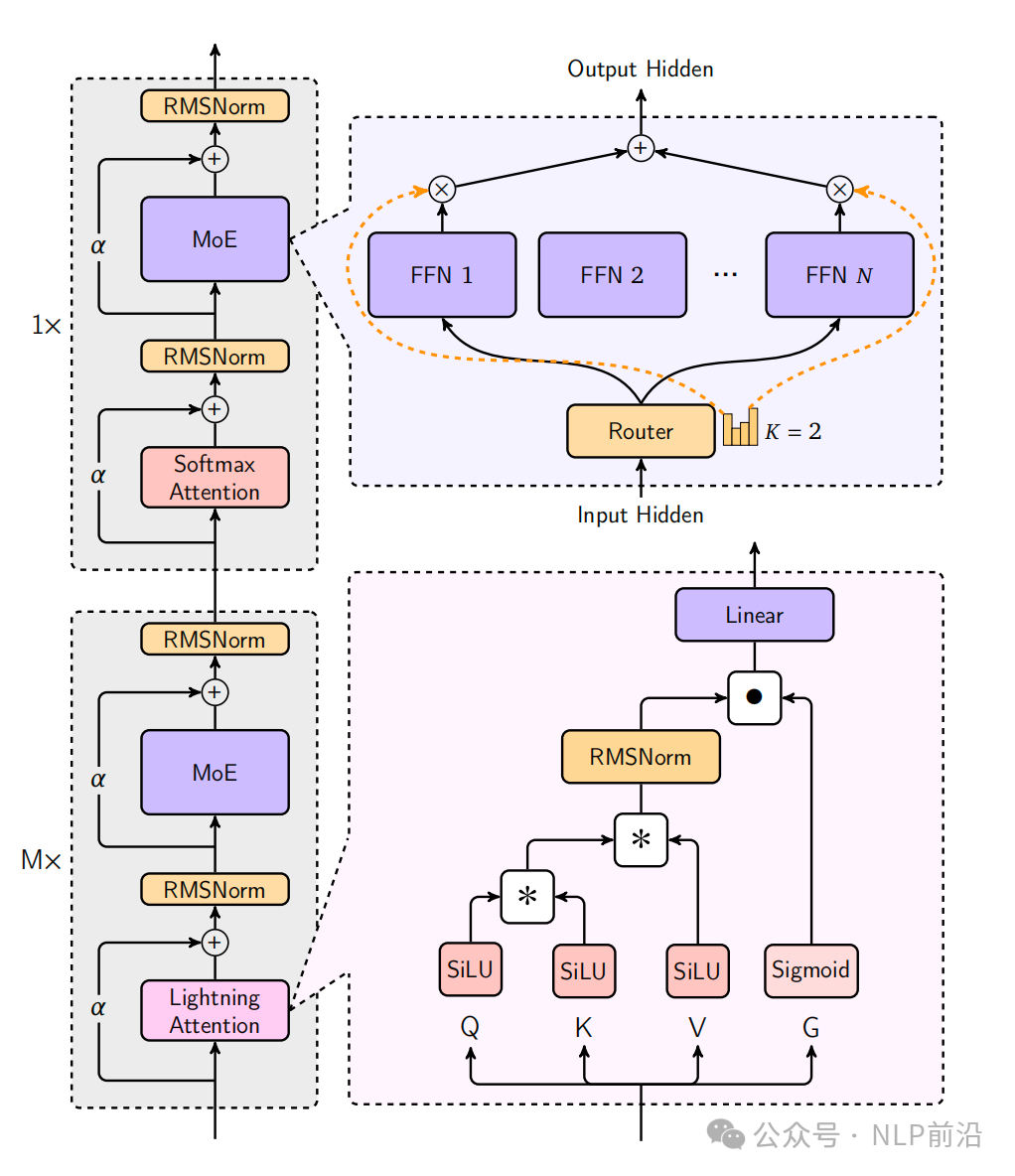
456B的模型,每次激活参数为45.9B,结构图如下:
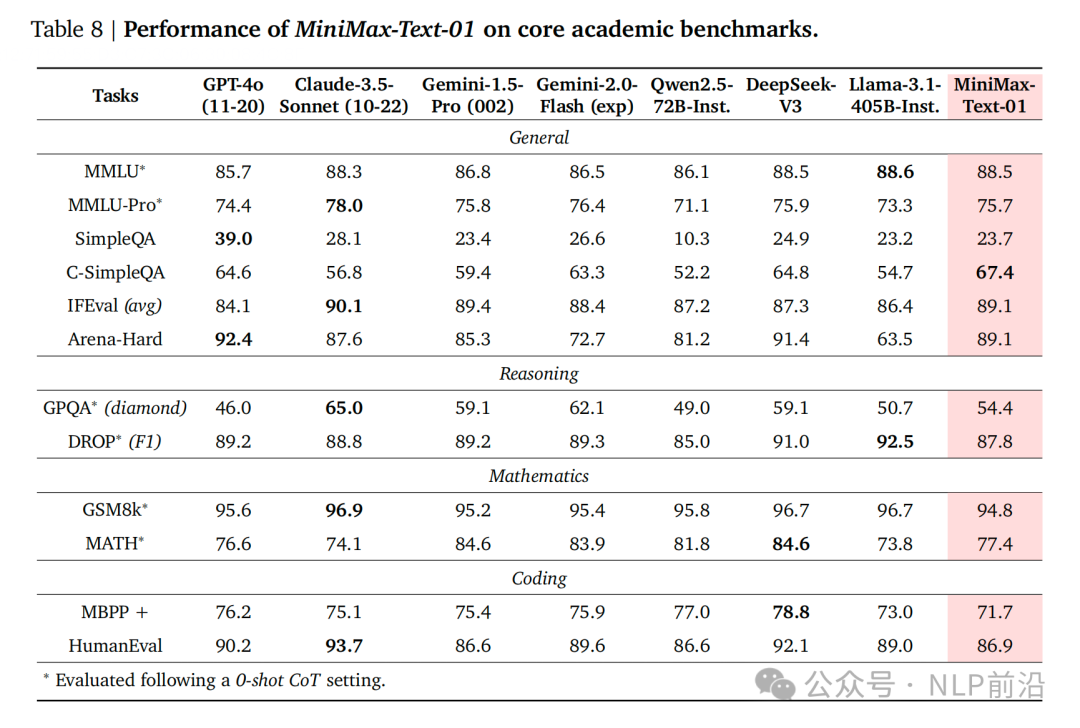
效果对齐第一梯队。
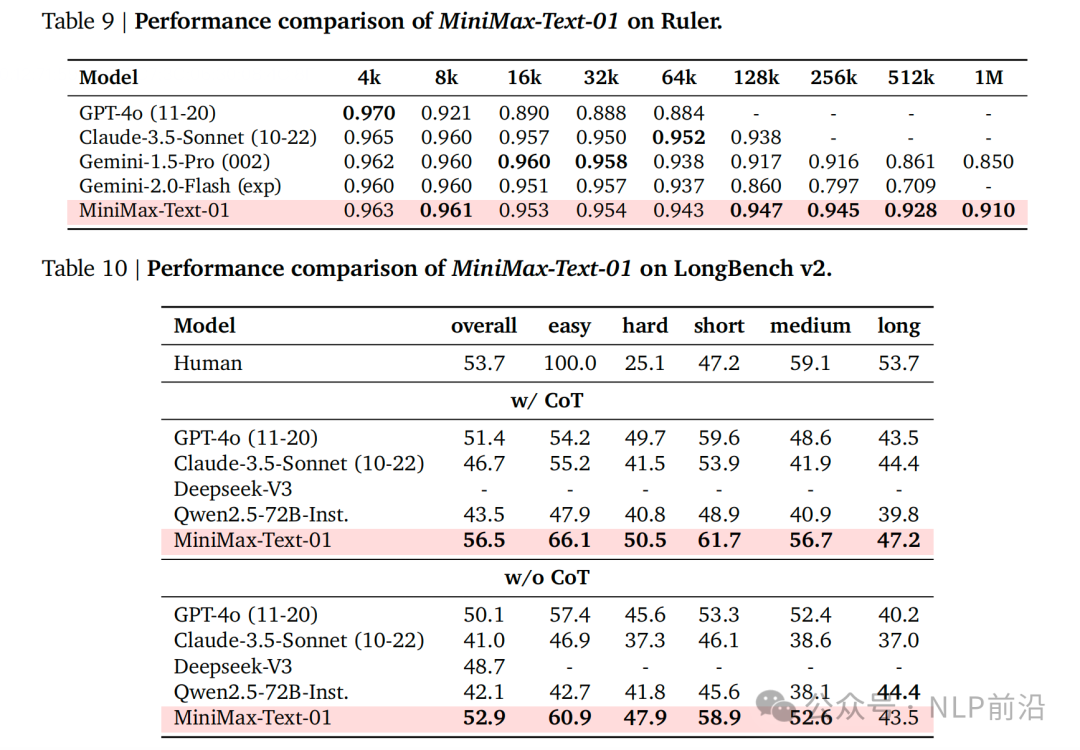
长文有领先优势。
© 版权声明
THE END
MiniMax-Text-01和MiniMax-VL-01开源。
用到了线性注意力,所以在处理长输入的时候有非常高的效率,接近线性复杂度。支持4M上下文的大海捞针。
并且得益于新架构,所以推理更快,在其他模型处理256K tokens的时间,Minimax的模型可以处理高达1000k tokens的信息。
456B的模型,每次激活参数为45.9B,结构图如下:
效果对齐第一梯队。
长文有领先优势。














暂无评论内容