随着图像生成和开放式文本生成的显著进展,交织图像-文本内容的创作成为一个越来越引人注目的领域。多模态故事生成,指的是以交替方式生成叙事文本和生动图像,已成为一项具有广泛应用价值和实际意义的任务。然而,这项任务面临着重大挑战,因为它需要理解文本和图像之间复杂的相互作用,并具备生成长序列连贯且具有上下文相关性的文本和视觉内容的能力。现有的方法仍然难以在角色身份保持与文本语义对齐之间保持平衡,这主要是因为缺乏对故事场景的详细语义建模。同时,保持语义一致性、生成高质量的精细交互以及确保计算可行性仍然是挑战,尤其是在长篇故事可视化(即最多100帧)中。本篇文章介绍三个开源生成儿童故事连环画的方法,也是一个赛道。
01 StoryWeaver
—
厦门大学提出了一种新型知识图谱—角色图(Character Graph,CG),它全面表示了与故事相关的各种知识,包括角色、与角色相关的属性以及角色之间的关系。接着,提出了StoryWeaver方法,它通过角色图(Character Graph)实现定制化(Customization via Character Graph,CCG)的图像生成器,能够实现与丰富文本语义一致的故事可视化。StoryWeaver不仅能够创建生动的视觉故事情节,而且能够准确地传达角色身份。

StoryWeaver的整体框架:(a)提出了角色图(Character-Graph),用于表示故事世界中的语义丰富知识。(b)通过提出的空间引导(spatial guidance)增强了StoryWeaver,以进一步提升多角色生成的性能。

02 Story-Adapter
—
Story-Adapter,用于增强长篇故事的生成能力。具体而言,加州大学圣克鲁斯分校提出了一种迭代范式,通过结合文本提示和来自前一轮生成的所有图像来优化每个生成图像。
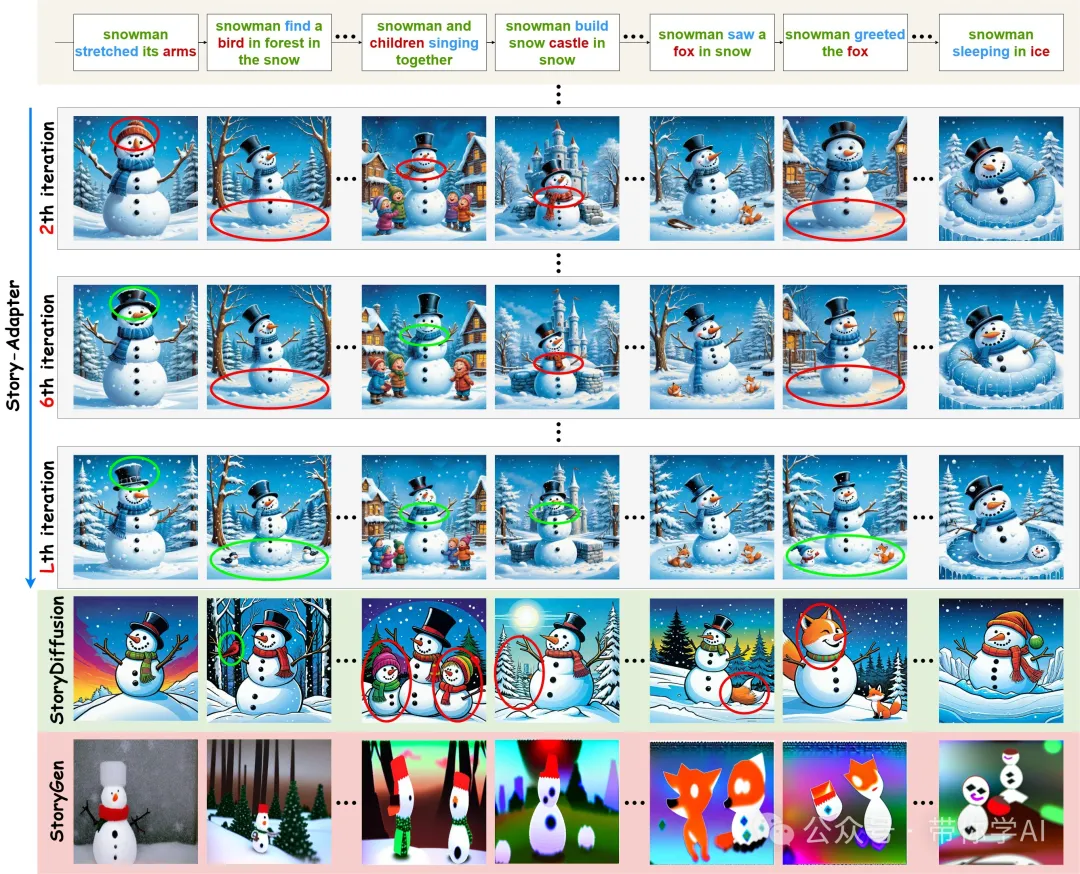
Story-Adapter框架。所提议的迭代范式示意图,包含初始化、Story-Adapter中的迭代过程以及全局参考交叉注意(GRCA)的实现。Story-Adapter首先仅根据故事的文本提示可视化每个图像,并将所有结果作为未来回合的参考图像。

在迭代范式中,Story-Adapter将GRCA插入到SD中。在每次图像可视化的第i次迭代中,GRCA将在去噪过程中通过交叉注意聚合所有参考图像的信息流。此迭代中的所有结果将作为参考图像,指导下次迭代中故事可视化的动态更新。
03 SEED-Story
—
Tencent提出了SEED-Story,这是一种新颖的方法,利用多模态大型语言模型(MLLM)生成扩展的多模态故事。基于MLLM强大的理解能力,预测文本标记和视觉标记,然后通过适应的视觉去标记器处理这些标记,生成具有一致角色和风格的图像。

在第一阶段,基于SD-XL预训练一个去标记器(de-tokenizer),通过将预训练的ViT特征作为输入来重建图像;在第二阶段,采样一个随机长度的交织图像-文本序列,并通过执行下一个词预测和图像特征回归,训练多模态大型语言模型(MLLM),在可学习查询的输出隐藏状态与目标图像的ViT特征之间进行回归;在第三阶段,从MLLM回归得到的图像特征被输入到去标记器中,用于调优SD-XL,从而增强生成图像中角色和风格的一致性。















暂无评论内容