如何从单一的任意图像高效地创建高质量、宽范围的3D场景?现有的方法面临多个限制,比如需要多视角数据、每个场景的优化耗时长、背景的视觉质量低以及未见区域的重建失真。为了解决这个问题,多伦多大学提出了一种新的流程来克服这些局限性,引入了一个大规模重建模型Wonderland,该模型利用视频扩散模型的潜在变量(latents)以前馈方式预测3D高斯散射(Gaussian Splattings)。
这个视频扩散模型被设计成能够精确地按照指定的摄像机轨迹创建视频,从而生成包含多视角信息的压缩视频潜在变量,同时保持3D的一致性。Wonderland模型在单视图3D场景生成方面明显优于现有方法,特别是在处理域外图像时。这也是首次证明了可以基于扩散模型的潜在空间有效地构建3D重建模型,以实现高效的3D场景生成。
01 技术原理
—
Wonderland采用渐进式训练策略对3D重建模型进行训练,使其能够在视频潜在空间上运行,从而实现高质量、宽范围和通用3D场景的高效生成。
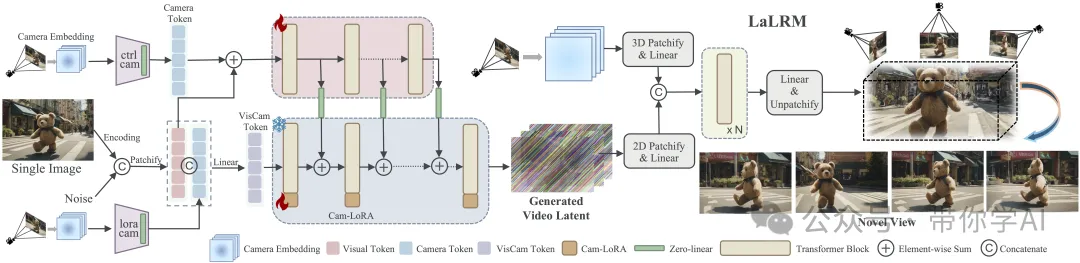
给定一张单一图像,摄像机引导的视频扩散模型遵循摄像机轨迹并生成具有3D意识的视频潜在变量(latent),该潜在变量被潜在变量为基础的大规模重建模型(LaLRM)利用,以前馈方式构建3D场景。视频扩散模型包含双分支摄像机条件化,以实现精确的姿态控制。LaLRM在潜在空间中操作,并高效地重建出宽范围和高保真的3D场景。
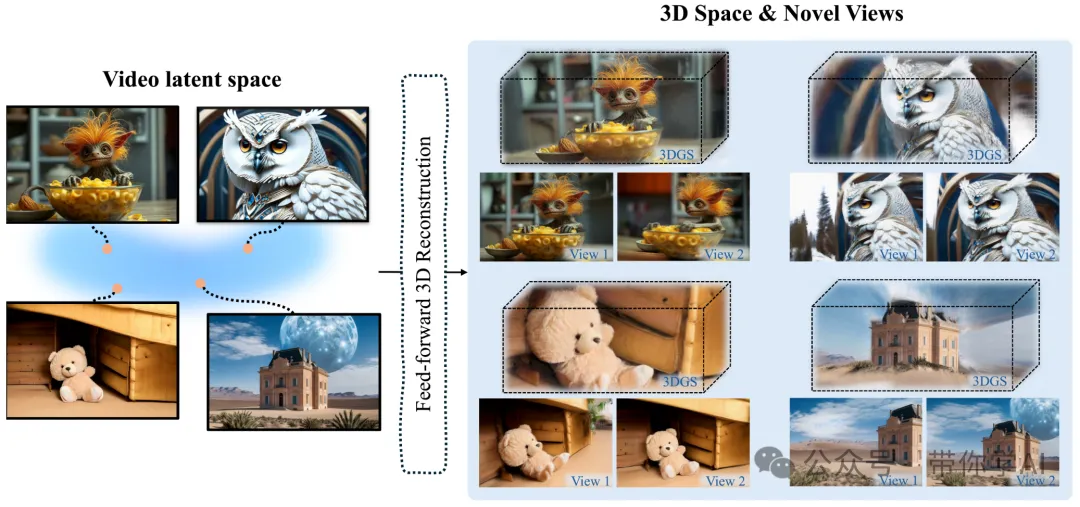
单次生成高保真、宽范围的3D场景 (One-shot 3D Scenes Generation):Wonderland能够基于单一输入图像快速生成(即一次完成,one-shot)高质量且范围广阔的3D场景。用户只需提供一张图片,系统就能几乎即时地构建出一个具有详细环境和广阔视野的三维空间。
通过自回归生成实现对3D场景的广泛导航 (Extensive Navigation by Autoregressive Generation):自回归生成意味着模型根据先前生成的内容逐步预测并添加新的内容,从而可以创建连续且一致的体验。这种方式允许用户在由一张初始图像生成的3D环境中自由移动,并且随着用户的互动,系统能够持续扩展或细化该环境。
02 演示效果
—
摄像机引导的视频生成:从单张图像出发,所提出的摄像机引导的视频扩散模型能够根据指定的摄像机轨迹精确地生成视频。演示视频是使用相同摄像机轨迹但不同图像提示生成的。
使用多个摄像机轨迹对场景进行广泛探索:从单张图像出发,所提出的摄像机引导的视频扩散模型能够根据指定的多个摄像机轨迹对场景进行广泛的探索。演示视频是在单张图像条件下,并基于多个摄像机轨迹生成的。














暂无评论内容