扩散模型以其生成高质量艺术效果图像的能力广受认可,而“布局到图像”(Layout-to-Image, L2I)生成技术就是基于这种能力开发的。L2I 可以利用特定区域的位置和描述,生成更加精确、可控的图像。然而,目前的研究主要集中在基于 UNet 的模型(例如 SD1.5 和 SDXL)上,对多模态扩散 Transformer(MM-DiT)的研究却较少。MM-DiT 在生成图像方面展现了强大的潜力,但将其应用到 L2I 中并不简单,因为需要解决布局与多模态之间如何引入、整合和平衡的复杂问题。
为了解决这一难题,复旦大学联合字节探索了多种网络结构,并最终提出了 SiamLayout。为了继承 MM-DiT 的优势,专门使用了一套独立的网络权重来处理布局,将其与图像和文本模态视为同等重要。最后,推出了 Layout Designer,利用大语言模型的潜力进行布局规划,赋予它们“设计师”般的能力,让它们可以生成并优化布局设计。

01 技术原理
—
首先,布局编码器会根据空间位置和区域描述生成“布局标记”(Layout Tokens)。在 SiamLayout 中,为布局专门设计了一套独立的 Transformer 参数,将布局与图像和文本模态视为同等重要。这个模型采用“孪生分支”结构,布局和文本分别独立引导图像生成,彼此互不干扰,最后在生成过程的后期将这些信息融合在一起。
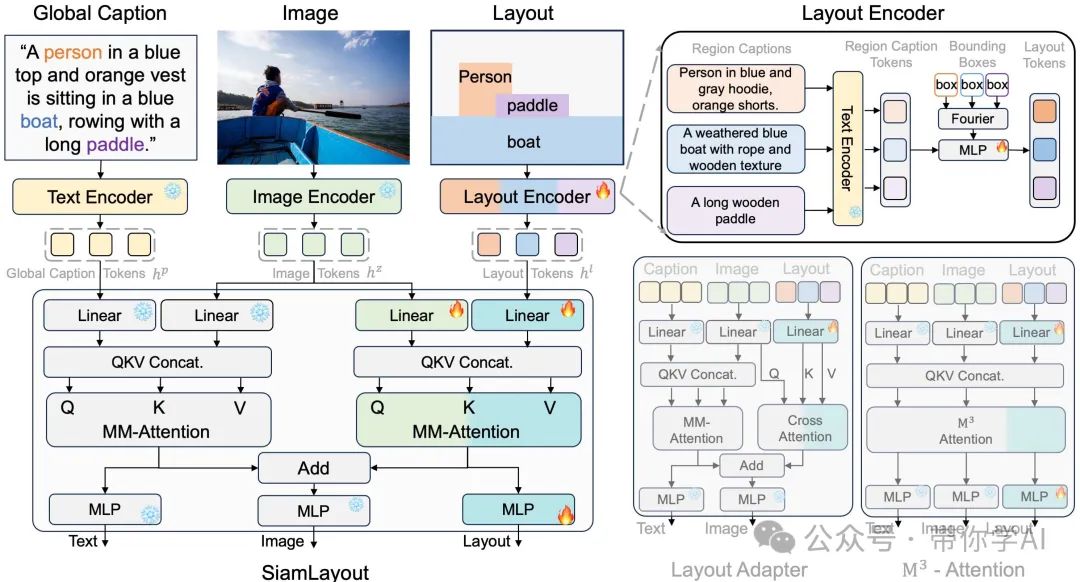
此外,还尝试了两种其他网络结构:一种通过交叉注意力(Cross-Attention)引入布局,另一种采用 M3-Attention。然而,实验结果表明,SiamLayout 的表现是最优的!
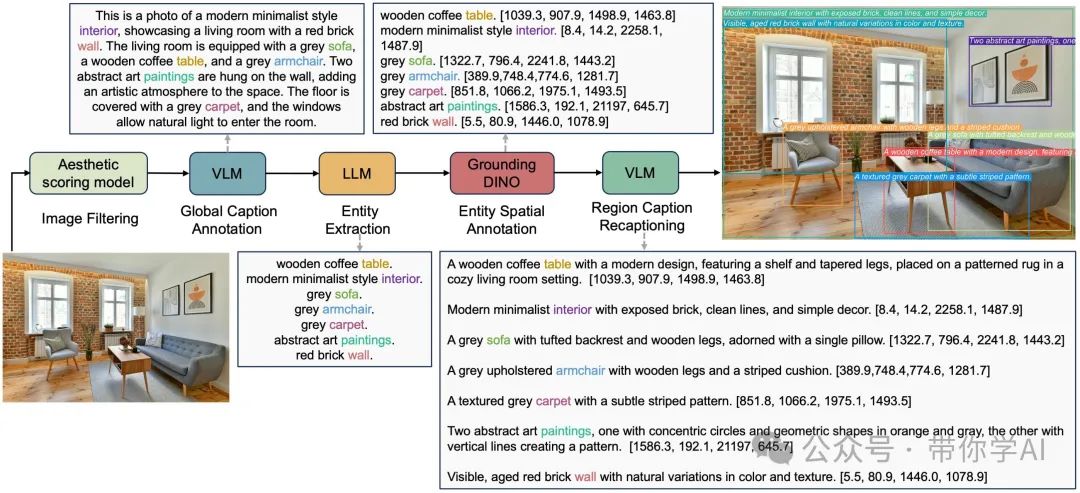
基于 SAM 创建了一个大规模布局数据集,命名为 LayoutSAM,其中包含 270 万组图像-文本对 和 1070 万个实体。每个实体都配有边界框(Bounding Box)和详细描述,标注非常精细。
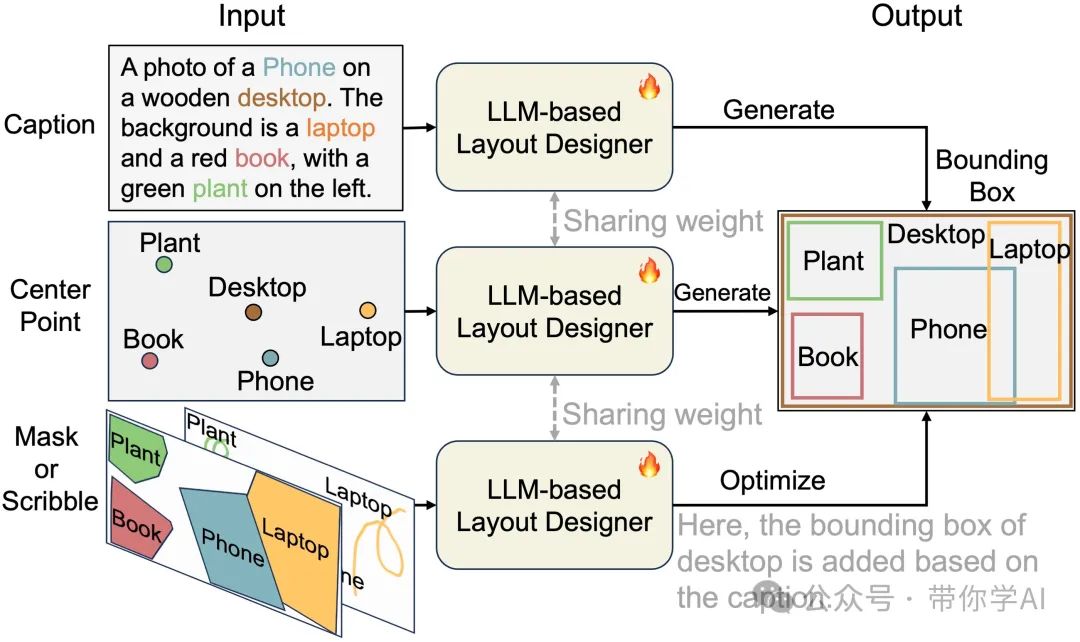
为了支持更多样化的用户输入,而不仅仅是实体的边界框,将一个大型语言模型打造成了一个布局规划师,命名为 LayoutDesigner。这个模型可以将用户的各种输入,比如中心点、掩码、涂鸦,甚至是一个模糊的想法,转换并优化成一个和谐且美观的布局设计。简单来说,不管你给出的想法多随意,LayoutDesigner 都能帮你变成一幅完美的作品!
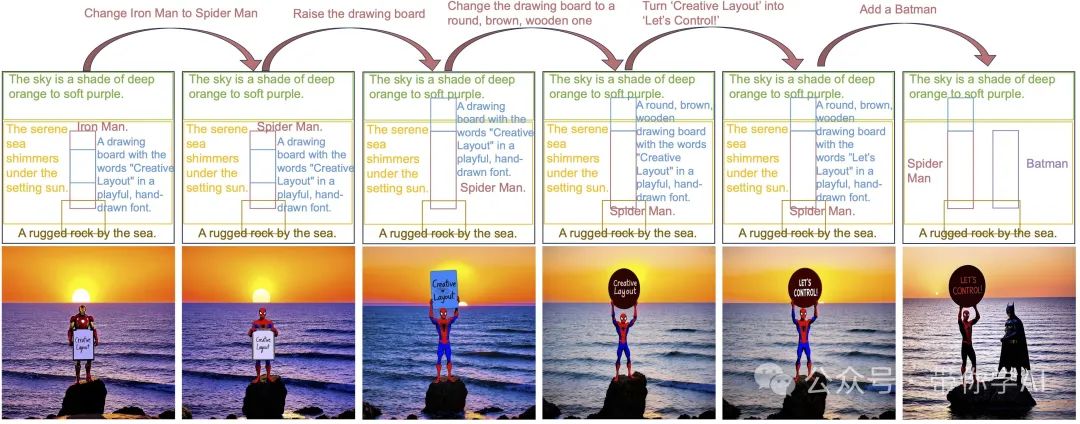














暂无评论内容