妆容迁移就是将各种不同风格的妆容,精准自然地应用到一张人脸照片上。目前,因为没有成对的训练数据(比如同一张脸有妆和无妆的版本),现有方法通常会生成一些“伪造的”参考数据来训练模型,但这些数据质量不高,导致妆容效果往往不够真实。此外,不同妆容对人脸的影响差异很大,而现有方法很难处理这种多样性。
为了解决这些问题,达摩院提出了一种新方法,叫基于潜在扩散模型的自监督分层妆容迁移(简称 SHMT)。它有三个关键点:自监督学习:SHMT 按照“分解-重建”的思路运行,不依赖质量欠佳的伪造参考数据,避免了错误指导模型的问题;分层处理妆容细节:不同妆容细节通过一种叫拉普拉斯金字塔的方法分层分解,再选择性地融入到人脸的内容表示中,这样能更灵活地适应各种妆容风格。动态校正对齐误差:通过迭代双重对齐模块(IDA),动态调整扩散模型中的妆容注入过程,逐步修正人脸内容和妆容风格之间的“对不上”的问题。

01 技术原理
—
妆容迁移任务中两个主要难点:
(a) 由于缺乏成对数据,现有方法通常采用直方图匹配或几何变形来生成次优的伪成对数据,但这些数据难免会对模型训练造成误导;
(b) 在简单妆容风格中,部分原始内容细节需要被保留,而在复杂妆容风格中,这些细节则需要被去除。

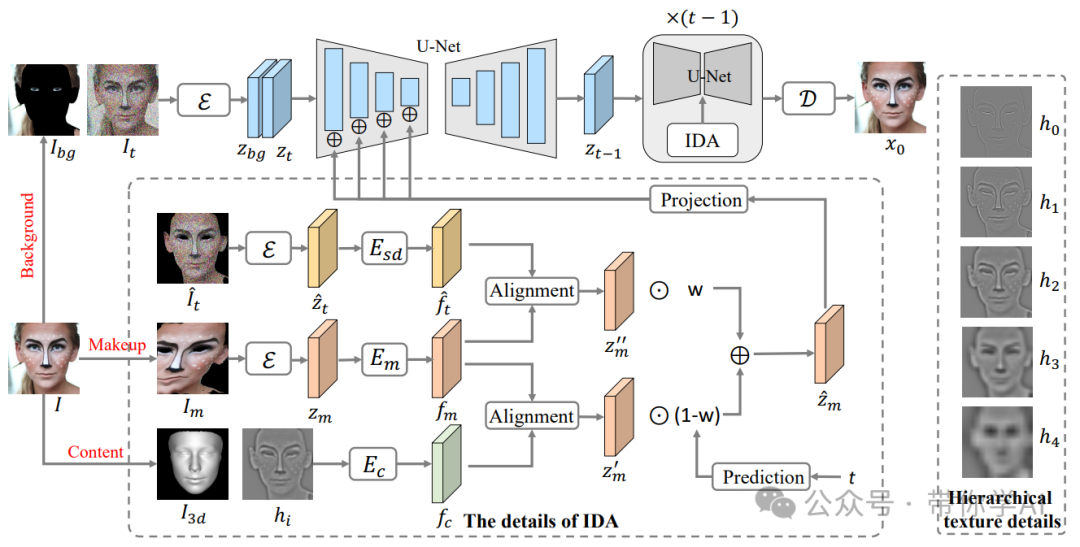
SHMT框架的说明:
一张人脸图像 被分解为背景区域 、妆容表示 和内容表示 。妆容迁移过程通过从这些组件重建原始图像来模拟。分层的纹理细节 被构建以适应不同的妆容风格。在每个去噪步骤 中,IDA 利用噪声中间结果 ,动态调整注入条件,从而修正对齐误差。
02 效果对比
—
选择了七种最先进的妆容迁移方法作为基线,包括 PSAGN、SCGAN、EleGANt、SSAT、LADN 、CPM 和Stable-Makeup。其中,只有 Stable-Makeup 是基于扩散模型的方法,其余方法均基于 GAN。

虽然PSGAN、SCGAN、EleGANt 和 SSAT 可以很好地保留源图像内容,但参考妆容的保真度较低,特别是在复杂妆容风格中。此外,这些方法往往会改变背景颜色。LADN 的结果伴随着大量的伪影和内容扭曲。CPM 在复杂妆容方面的表现相对令人满意,但仍无法再现一些高频妆容细节。由于 UV 空间不包含额头区域,CPM 的结果有明显的拼贴感,并且在面部轮廓处存在一些伪影。

Stable-Makeup 的结果相比参考妆容风格存在明显的颜色偏移。此外,这些结果往往会改变源图像的内容信息,包括身份和表情。对于复杂妆容风格,Stable-Makeup 的结果仍然显著丢失高频妆容细节。相比之下, SHMT 方法通过不同的纹理细节,能够自然且精确地在源人脸上再现各种妆容风格。














暂无评论内容