随着多模态大语言模型(MLLMs)的出现,它们在许多现实应用中都带来了巨大影响,特别是在自动驾驶领域。因为它们能够处理复杂的视觉数据并对驾驶场景进行深入的推理,这为端到端自动驾驶系统开创了新局面。不过,目前开发端到端自动驾驶模型的进展较为缓慢,原因是现有的微调方法需要大量资源,包括强大的计算能力、大规模数据集以及可观的资金投入。
受近期推理计算技术进步的启发,德克萨斯农工大学提出了OpenEMMA,一个基于 MLLMs 的开源端到端框架。通过引入“思维链”(Chain-of-Thought)推理过程,OpenEMMA 相较于基线模型表现出显著提升。OpenEMMA是《Waymo 的端到端自动驾驶多模态模型 (EMMA)》的开源实现 ,为自动驾驶汽车的运动规划提供了端到端框架。同时,它在各种复杂的驾驶场景中表现出了高效性、适应性和稳定性,为自动驾驶提供了一种更高效、更可靠的解决方案。

01 技术原理
—
EMMA 由 Google 开发的多模态大语言模型 Gemini 提供支持,它采用统一的端到端训练模型,直接从传感器数据生成自动驾驶车辆的未来轨迹。为了适应自动驾驶的需求,EMMA 专门进行了训练和微调,并充分利用 Gemini 广博的世界知识,更好地理解道路上的复杂场景。
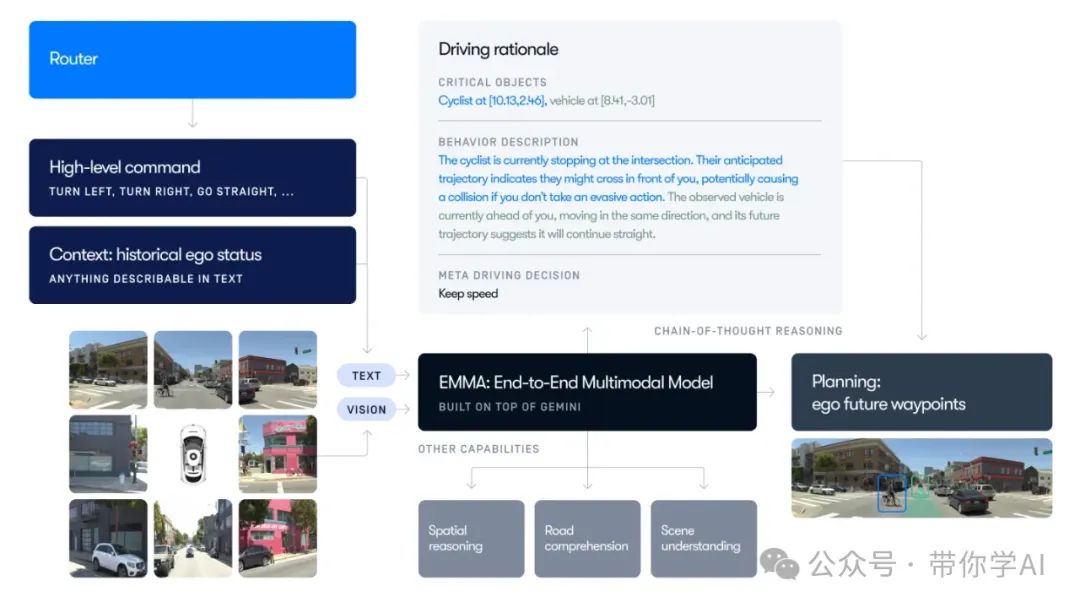
为了解决像 EMMA 这样的闭源模型的局限性,旨在使用公开可用的工具和模型复制 EMMA 的核心功能。OpenEMMA 的目标是将这些技术进步民主化,为更广泛的研究和开发提供平台。与 EMMA 类似,OpenEMMA 以前置摄像头图像和车辆历史状态的文本输入为基础,将驾驶任务设计为视觉问答(Visual Question Answering, VQA)问题,同时采用思维链推理指导模型生成关于关键目标、行为洞察和驾驶决策的详细描述。这些决策由模型直接推断,为路径点生成提供必要的上下文信息。
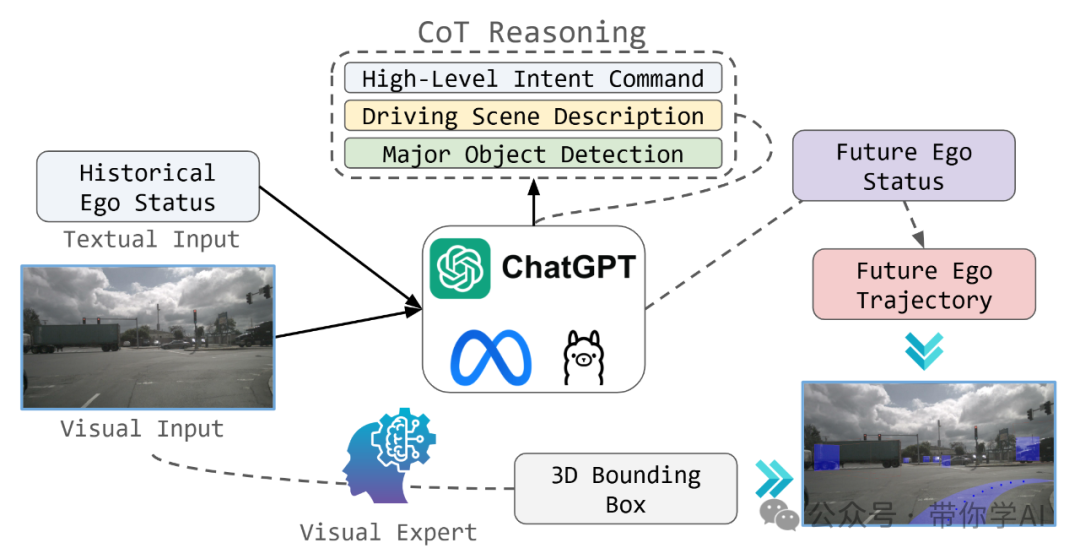
为应对多模态大模型(MLLMs)在目标检测任务中的已知局限性,OpenEMMA 集成了一版专为自动驾驶场景优化的 YOLO 模型,用于 3D 边界框预测,从而显著提高检测精度。此外,借助多模态大模型的现有世界知识,OpenEMMA 能够为场景理解等感知任务生成可解释的、易于人类阅读的输出,进一步提升透明度和可用性。

02 演示效果
—
OpenEMMA在低光夜间条件下的性能。虽然OpenEMMA在这种具有挑战性的环境中偶尔可能会错过某些物体的检测,但它成功识别并检测到了对安全导航至关重要的关键物体。此外,它准确理解自车正在向左车道转换,并生成了精准的轨迹规划以有效适应这一操作。















暂无评论内容