Sora-like 视频生成模型在多模态扩散变换器(MM-DiT)架构的支持下取得了显著进展。然而,目前的视频生成模型大多集中于单一提示,难以生成多个连续提示所组成的连贯场景,而这些提示更能反映现实世界中的动态场景。虽然一些开创性的研究尝试了多提示视频生成,但它们面临着很多挑战,如对训练数据的严格要求、提示跟踪不准确、以及过渡不自然等问题。
为了解决这些问题,香港中文大学联合腾讯等提出了DiTCtrl,这是一种无需额外训练的多提示视频生成方法,首次应用于MM-DiT架构中。DiTCtrl方法的核心思想是将多提示视频生成任务看作是带有平滑过渡的时序视频编辑。DiTCtrl生成的视频能够在多个连续提示下实现平滑过渡和一致的物体运动,且无需额外的训练。
01 技术原理
—
MM-DiT的注意力机制与UNet-like扩散模型中的交叉/自注意力块非常相似。具体来说,如图1所示MM-DiT中的注意力矩阵可以分解为四个不同的区域:文本到文本、视频到视频、文本到视频和视频到文本的注意力区域。以“a cat watch a black mouse”(一只猫看着一只黑色的老鼠)为例,每个文本的词语在分析文本到视频和视频到文本区域的平均注意力值时,都会表现出明显的激活模式。
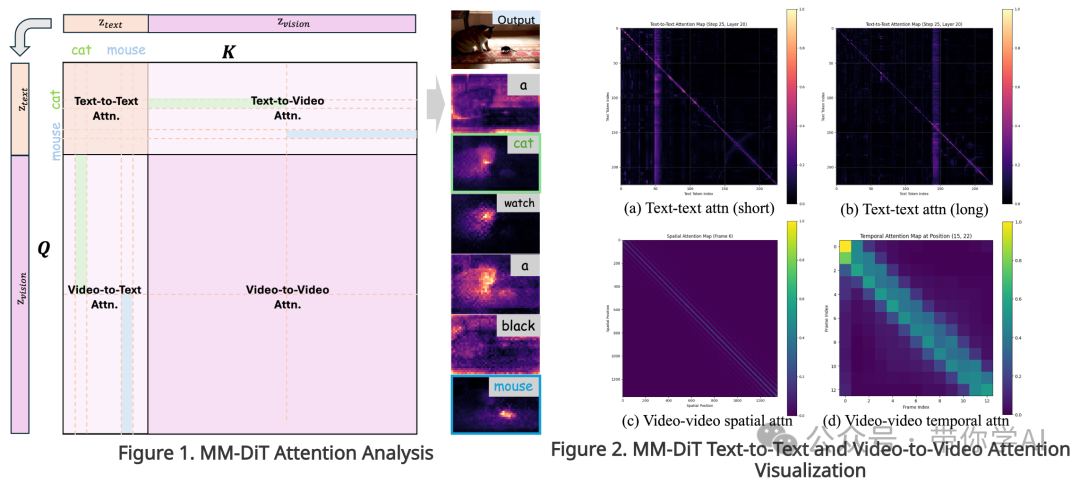
此外,如图2所示,对文本到视频和视频到文本注意力模式的可视化展示表明,MM-DiT不仅具备类似UNet自注意力的功能,还在时间建模方面表现出了更强的能力。这表明,MM-DiT的注意力机制可以轻松扩展到多提示视频生成任务,使得在不同提示之间通过共享kv(键值对)进行精确的语义控制,从而生成更自然的多提示视频。
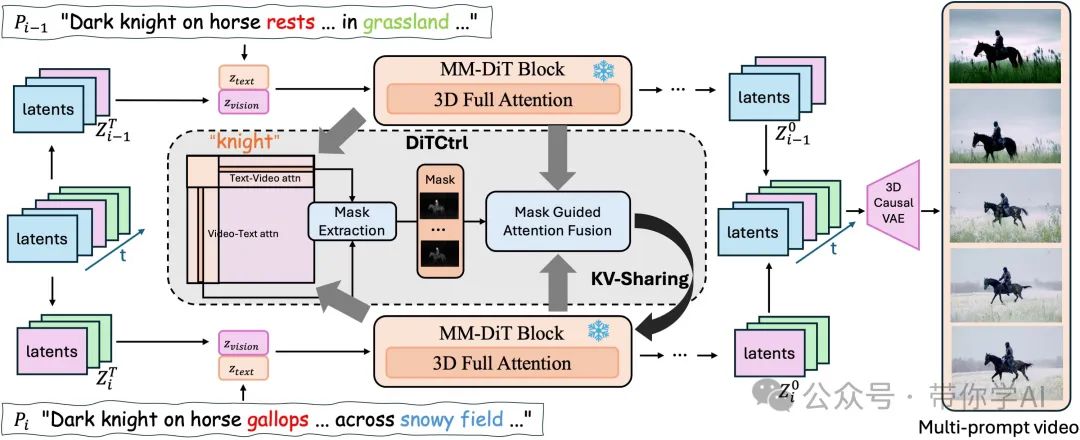
第一个视频是通过源文本提示 合成的。在视频合成的去噪过程中,将全注意力转换为基于掩码引导的 KV 共享策略,以从源视频 中查询视频内容,从而在修改后的目标提示 下合成内容一致的视频。需要注意的是,初始潜变量被假设为 5 帧。前三帧用于生成 的内容,后三帧用于生成 的内容。粉色的潜变量表示重叠帧,而蓝色和绿色的潜变量用于区分不同的提示段落。














暂无评论内容