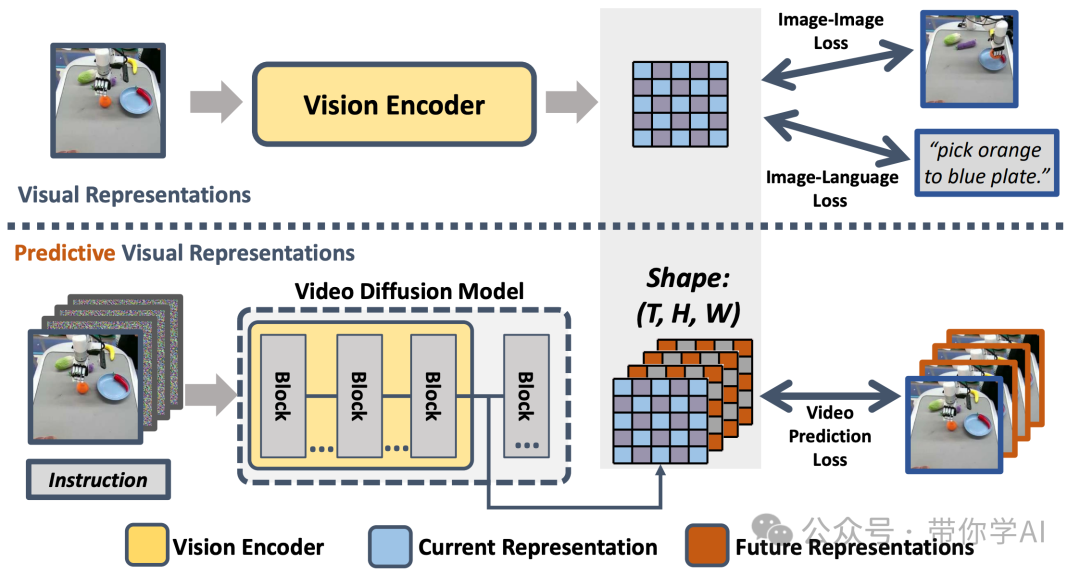
最近,机器人技术的进步主要集中在开发能够执行多种任务的通用策略上。通常,这些策略使用预先训练好的视觉编码器来从当前观察中捕捉重要信息。但是,以前的视觉编码器—那些通过对比两张图片或重建单张图片训练出来的—并不能完美地捕捉到对于实体任务至关重要的顺序信息。但视频扩散模型展示了其准确预测未来图像序列的能力,表现出对物理动态的良好理解。
受到VDMs强大视觉预测能力的启发,清华大学假设这些模型内部具有反映物理世界演变的视觉表示,将这种表示称为“预测性视觉表示”,提出了视频预测策略(VPP)。VPP在两个模拟环境和两个真实世界的基准测试中,表现始终优于现有方法。特别是在Calvin ABC-D基准测试中,相比之前的最先进方法,VPP取得了28.1%的相对提升,并且在复杂的真实世界灵巧操作任务中,成功率提升了28.8%。
01 技术原理
—
视频预测策略VPP分为两阶段学习过程。首先,在多个操作数据集上训练文本引导的视频预测(TVP)模型,从互联网上获取物理知识;然后,设计了网络,负责将TVP模型中的预测视觉表示整合起来,并输出最终的机器人动作。
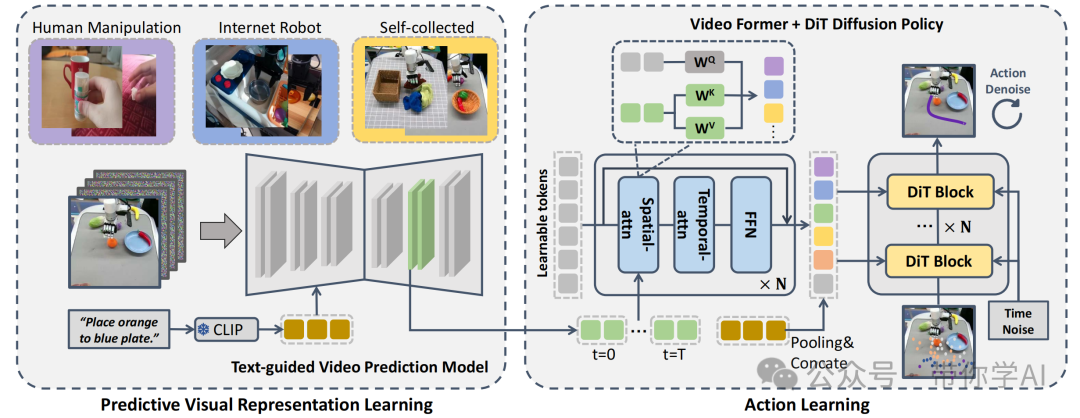
之前的视觉编码器并没有明确的未来帧表示,VPP使用视频扩散模型作为视觉编码器,获取能够明确表达当前帧和未来连续帧的预测性表示。这也是第一个用于多任务灵巧机器手操作的通用策略。
在模拟环境和真实世界的机器人任务中进行了大量实验,以评估视频预测策略(VPP)的表现。在模拟环境中,使用了CALVIN基准和MetaWorld基准来进行测试;而在真实世界任务方面,则包括了Panda机械臂的操作任务以及XHand灵巧手的操作任务。

02 演示效果
—
在灵巧手平台上,收集了超过3000条轨迹,这些轨迹涵盖了13个类别中100多项不同的任务,比如放置物体、将杯子扶正、移动物体、堆叠、传递物品、按压、拔出、打开以及使用复杂工具等。这里展示的是具有挑战性的使用工具的任务。














暂无评论内容