近年来,定制文本生成图像模型(T2I)取得了巨大进展,尤其是在个性化、风格化和条件生成等方面。然而,将这些进展扩展到视频生成领域还处于起步阶段,主要是因为缺乏定制化的视频数据。为了解决这个问题,谷歌提出了 Still-Moving,一种无需任何定制视频数据,就能定制文本生成视频模型(T2V)的全新通用框架。
该框架通过轻量级空间适配器和运动适配器,利用“冻结视频”训练,无缝整合定制 T2I 模型与 T2V 模型,解决直接套用权重导致的画面问题。Still-Moving方法在多个任务上表现出色,包括个性化、风格化和条件生成。在所有测试场景中,Still-Moving方法都能完美结合定制 T2I 模型的空间特性和 T2V 模型的运动特性,实现无缝的生成效果。
01 技术原理—Still-Moving主要提供以下方法:
- 个性化视频生成:根据用户需求生成专属视频。
- 风格化视频生成:生成具有特定艺术风格的视频。
- 带条件的视频生成:结合 ControlNet 控制条件生成特定内容的视频。

Still-Moving设计了两步方法,将定制 T2I 的权重注入并适配到 T2V 模型中:
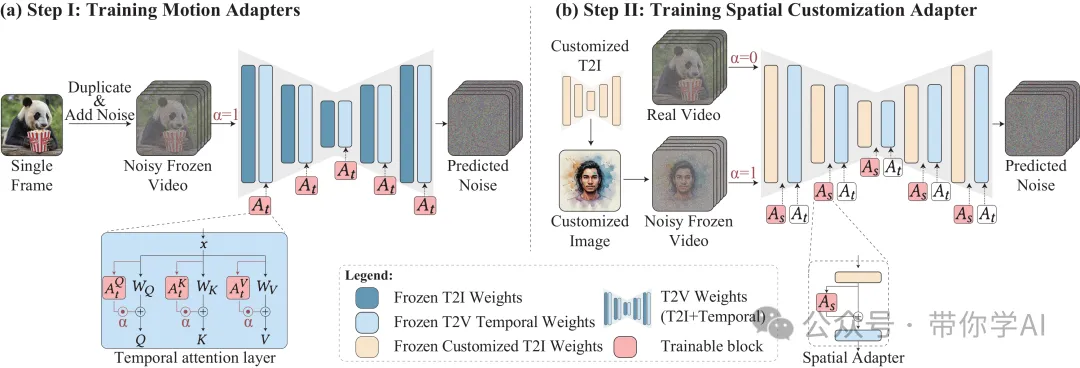
- 引入运动适配器(Motion Adapters):通过在时间注意力模块上加入 LoRA 层,这些适配器能够控制生成视频的动态效果。使用“冻结视频”(由同一定制帧重复组成的视频)进行训练,动态控制参数 α 设置为 1(详见第 3 节)。
- 注入定制 T2I 权重并训练空间适配器(Spatial Adapters):在使用 α 为 1 的定制图像和 α 为 0 的自然视频的组合数据上训练,这些适配器可以调整模型在图像和视频生成之间的适配效果。
基于文本生成图像模型(T2I)构建的文本生成视频模型(T2V)中,Still-Moving 可以调整任何定制的 T2I 模型权重,使它们适配 T2V 模型。这是通过在静态图像上训练轻量级的适配器实现的。
© 版权声明
THE END














暂无评论内容