Adobe和Northwestern University提出了一种生成音频的模型Sketch2Sound,能够根据一系列易于理解的、随时间变化的控制信号(如音量、亮度、音高)以及文本提示,生成高质量的声音。Sketch2Sound可以从模仿的声音(比如人声模仿或参考声音形状)中合成任意的声音。它可以基于任何文本到音频的潜在扩散变换器(DiT)进行实现,并且只需要40k步的微调和每个控制信号一个简单的线性层,这使得它比现有的像ControlNet这样的模型更轻量。
为了从类似草图的声音模仿中合成声音,Sketch2Sound在训练过程中对控制信号应用随机中值滤波,这使得Sketch2Sound可以使用灵活时间精度的控制信号进行提示。Sketch2Sound使得声音艺术家可以利用文本提示的语义灵活性,并结合声音手势或人声模仿的表现力和精确性来创作声音。
01 技术原理
—
Sketch2Sound 是一个把声音模仿转换为生成新声音的技术。它会从用户输入的模仿声音中提取三个关键控制信号:响度(音量大小)、频谱质心(简单来说就是声音的“亮度”)和音高概率(声音的高低变化)。这些信号会被编码后,加入到用来生成声音的核心模型中,一个基于 DiT(扩散模型)的文本到声音生成系统。这样,系统就能根据模仿的声音特点,生成出具有相似风格的新声音。
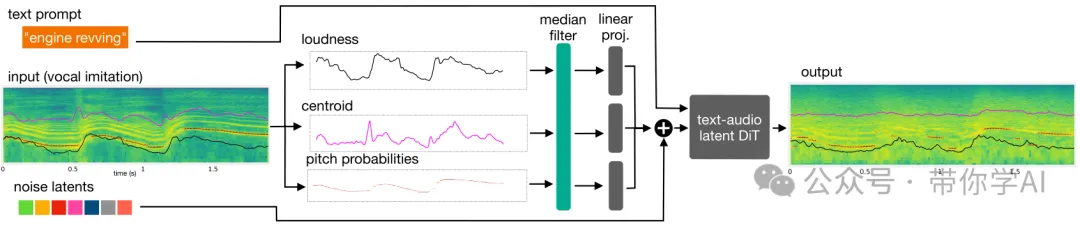
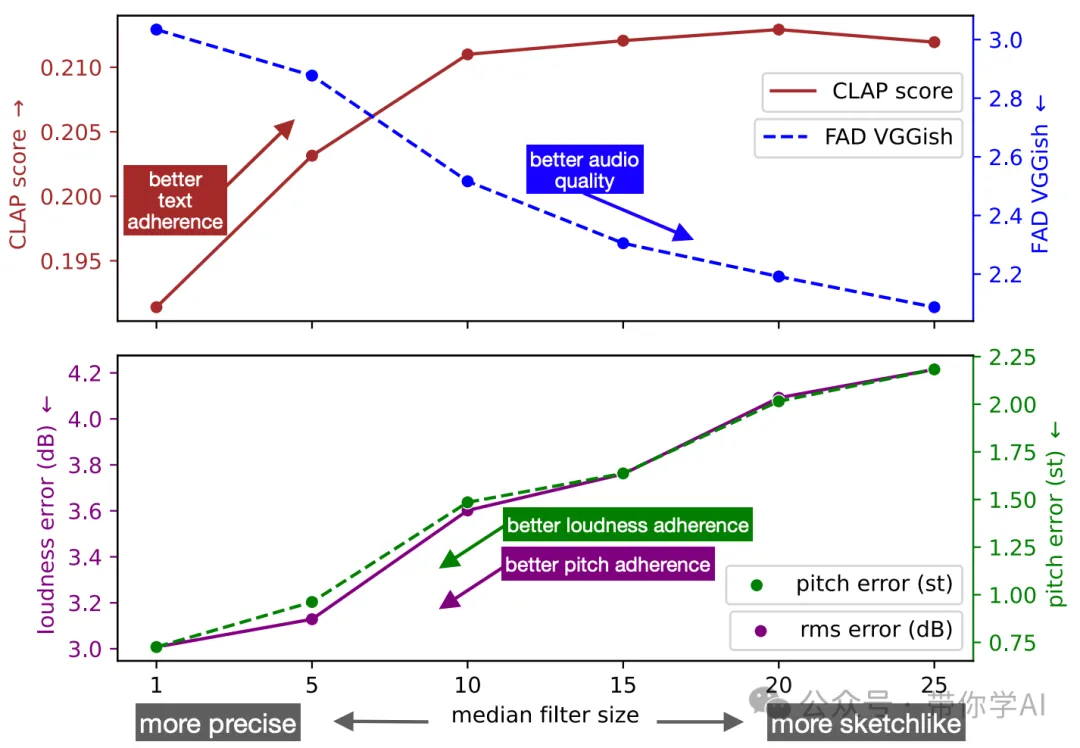
在生成声音时,使用较大的中值滤波器会让效果更像“草图”,声音质量也可能更高;而较小的滤波器会让生成的声音更精确,但如果模仿声音本身不够准确,可能会导致音质下降。这给声音艺术家提供了一个选择,可以在“草图感”和“精确度”之间找到适合自己的平衡点。
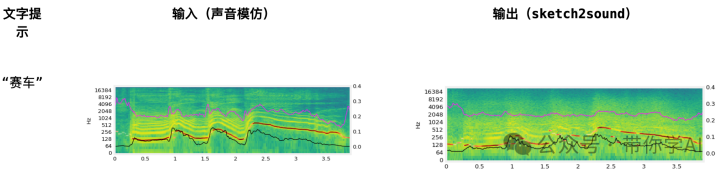
下边第一个声音是原始输入“人嘴模拟的声音”,然后输入提示词“赛车”,下边第二个是Sketch2Sound输出的模拟结果。
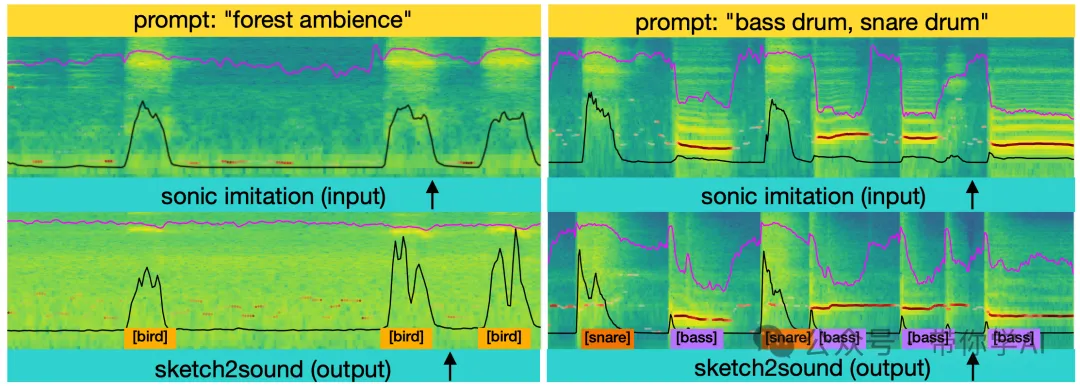
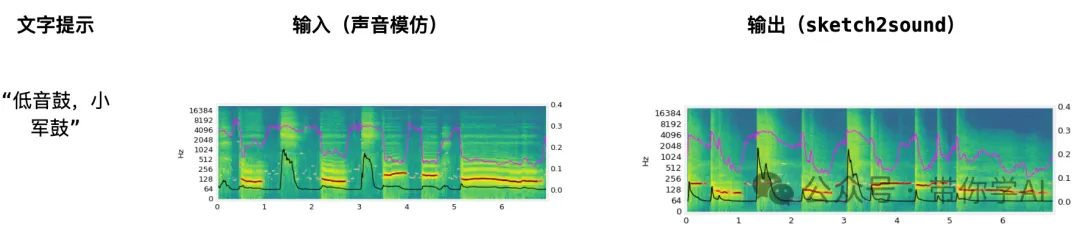
(下左图)当输入提示词“森林氛围”时,控制信号中的响度突增部分自然生成了鸟鸣声,即使没有特别指示模型这样做。(下右图)当提示词是“低音鼓和小军鼓”时,模型会自动将小军鼓放在没有音高的区域,而低音鼓放在有音高的区域。这展示了模型在生成声音时的智能化行为。
02 演示效果
—
值得一提的是Hugo是一名西北大学的博士生,从事应用机器学习、音乐和人机交互交叉领域的研究。同时是一名即兴演奏家、程序员和科学家。Hugo的创作实践涵盖吉他即兴创作和作曲、声音物体和电子设备、声音装置、定制数字乐器和互动艺术。

下边第一个声音是人类模拟,提示词为“低音鼓、小军鼓”下边第二个声音是模拟输出结果。














暂无评论内容