AI虚拟试穿或许你已经看过很多了,那么如果获取模特身上的衣服模型?虚拟试脱(VTOFF)来了!它可以从穿着衣服的人的照片中生成标准的衣物图像。与传统的虚拟试穿(VTON)不同,VTON是通过数字技术为模特穿上衣服,而VTOFF的目标是从照片中提取出衣物的标准图像。这要求能够准确捕捉衣物的形状、纹理以及复杂的图案,带来了一些独特的挑战。
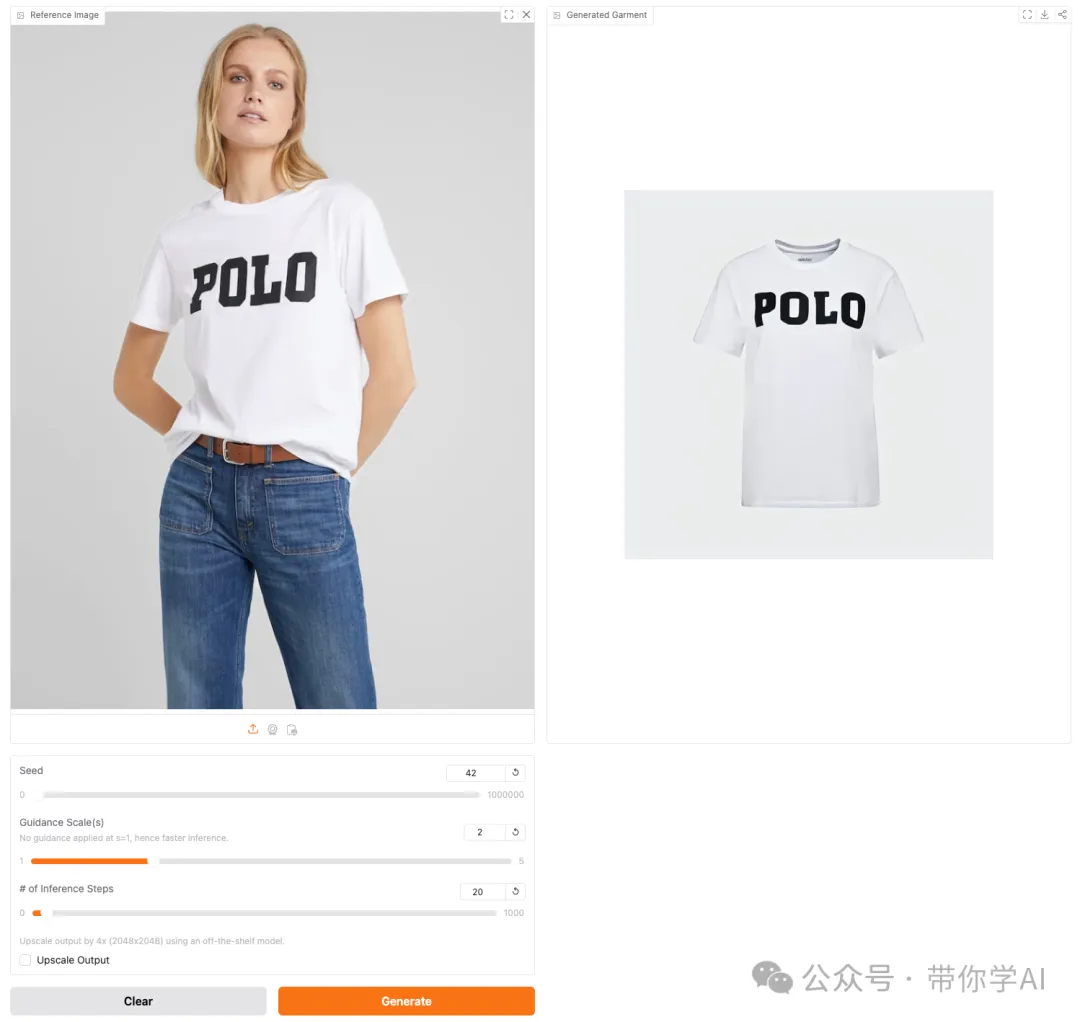
比勒费尔德大学提出了一种名为TryOffDiff的新模型,该模型改进了Stable Diffusion,并使用基于SigLIP的视觉条件来保证高保真度和细节保留。TryOffDiff方法比基于姿势转移和虚拟试穿的基础方法表现得更好,而且所需的预处理和后处理步骤更少。VTOFF不仅有望改善电子商务中的产品展示图片,还能推动生成模型评估的发展,并激发未来对于高精度重建的研究兴趣。
01技术原理
—
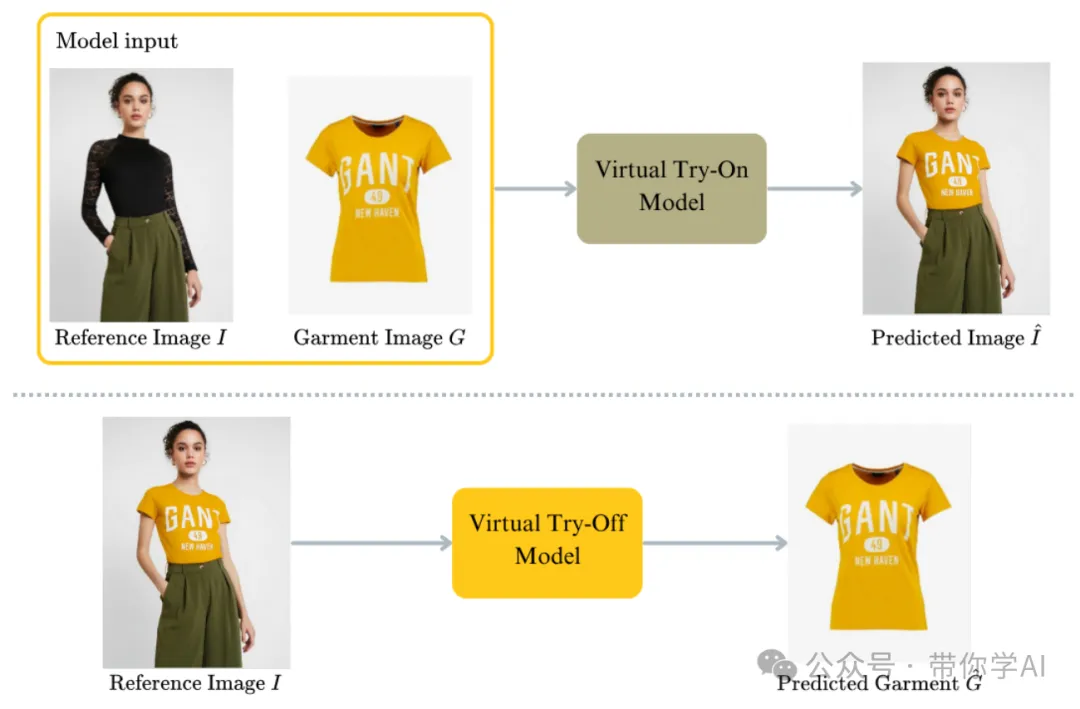
虚拟试穿(Virtual Try-On)和虚拟试脱(Virtual Try-Off)之间的区别。
顶部:虚拟试穿的基本流程是这样的,它接收一张穿着衣服的人的照片作为参考,再加上另一张衣物的照片,然后生成一张该人穿上指定衣物后的图像。
底部:而虚拟试脱的目标是从单张输入的参考图片中预测出衣物的标准形态。这意味着不是给模特穿上新衣服,而是从现有照片中提取出衣物的样子,并将其呈现为标准的姿态,背景干净,便于单独展示衣物本身。
首先,使用SigLIP图像编码器从参考图片中提取特征。
然后,这些提取出的图像特征会通过一些适配模块进行处理。
接下来,这些图像特征被嵌入到一个预训练的文字转图像模型—Stable Diffusion-v1.4中。这里的关键是用图像特征替换了模型中原有的文字特征,在交叉注意力层中发挥作用。
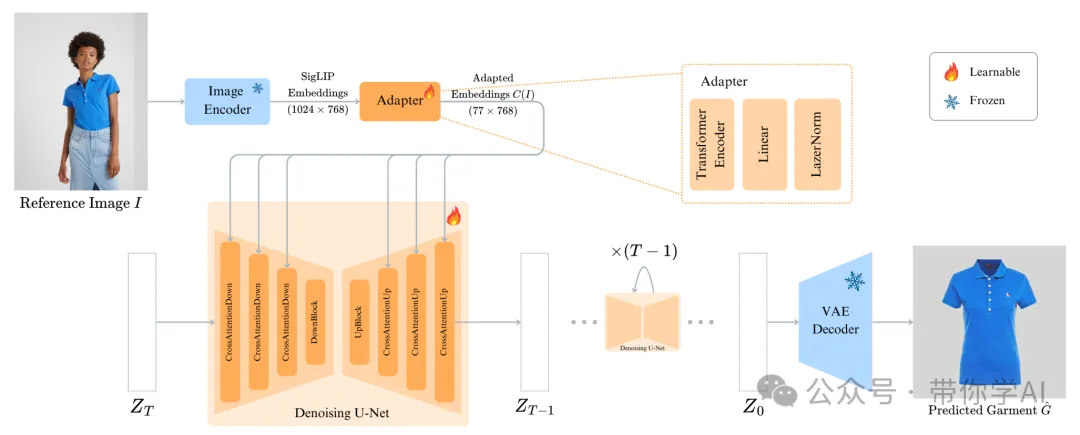
通过基于图像特征而不是文字特征来调整模型,TryOffDiff可以直接针对虚拟试脱(VTOFF)任务进行优化。通过对适配层和扩散模型的同时训练,TryOffDiff能够有效地实现衣物的转换。
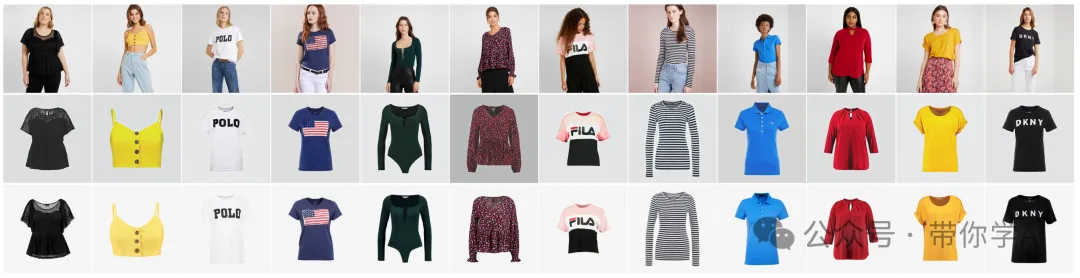
将现有的最先进方法应用于VTOFF(虚拟试衣服系统)。左上部分展示了一种叫做GAN-Pose的技术,它基于姿势转移的方法。从左到右:参考图像、基于目标图像修正的姿势热图、初始模型输出、SAM提示、以及最终处理后的输出。右上部分展示了一种叫做ViscoNet的技术,它基于视角合成的方法。从左到右:遮罩的条件图像、遮罩图像、姿势图像、带有SAM提示的初始模型输出、以及最终处理后的输出。

左下部分展示名为OOTDiffusion的技术,它是一种最近的虚拟试衣方法。从左到右:遮罩的衣物图像、模型图像、遮罩的模型图像、带有SAM提示的初始模型输出、以及最终处理后的输出。右下部分展示了CatVTON技术的应用,它也是一种新的虚拟试衣方法。从左到右:条件衣物图像、空白的模型图像、遮罩图像、带有SAM提示的初始模型输出、以及最终处理后的输出。














暂无评论内容