
OpenAI 的 o3 模型(在 ARC-AGI-1 公共训练集上进行训练)在我们公布的公共排行榜 10,000 美元计算限制下的半私人评估集上取得了突破性的75.7% 的成绩。高计算(172x)o3 配置得分为87.5%。
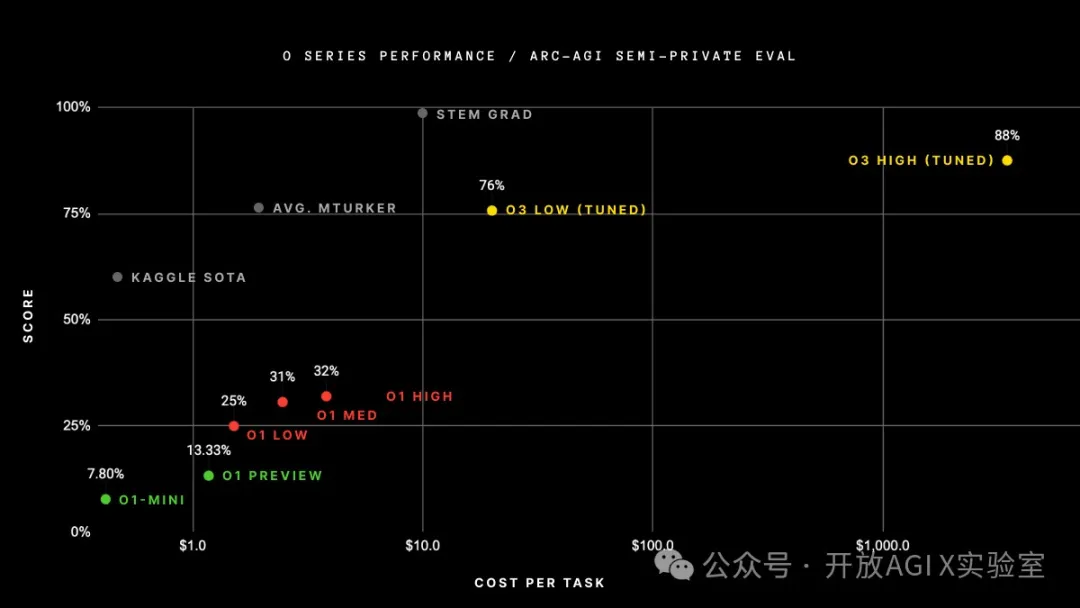
这是 AI 能力的惊人而重要的阶跃式增长,展现了 GPT 系列模型中前所未有的新任务适应能力。作为背景,ARC-AGI-1 用了 4 年时间从 2020 年 GPT-3 的 0% 上升到 2024 年 GPT-4o 的 5%。所有关于 AI 能力的直觉都需要针对 o3 进行更新。ARC Prize 的使命超越了我们的第一个基准:成为 AGI 的北极星。我们很高兴明年能与 OpenAI 团队和其他团队合作,继续设计下一代持久的 AGI 基准。ARC-AGI-2(相同格式 – 对人类来说很容易验证,对人工智能来说更难验证)将与 ARC Prize 2025 一起推出。我们致力于举办大奖赛,直到创造出得分达到 85% 的高效开源解决方案。OpenAI o3 ARC-AGI 结果我们针对两个 ARC-AGI 数据集测试了 o3:半私密评估:用于评估过度拟合的 100 个私密任务公开评估:400个公开任务在 OpenAI 的指导下,我们在两个计算级别上进行了测试,样本大小可变:6(高效)和 1024(低效,172 倍计算)。结果如下。
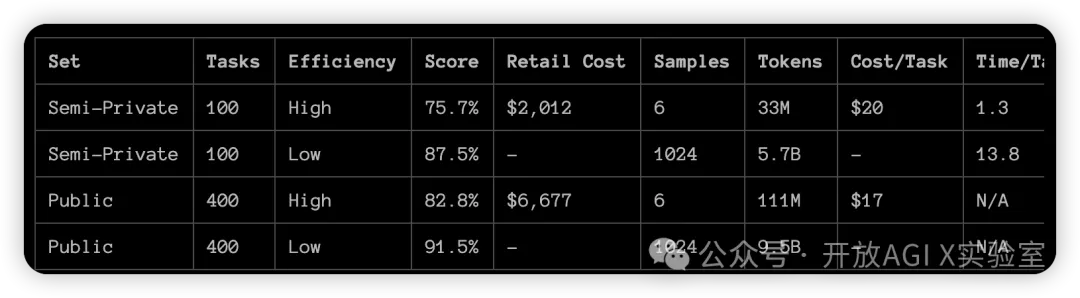
继续阅读完整的测试报告。https://github.com/arcprizeorg/model_baseline/tree/main/resultscodeforces 编码表现
OpenAI o3 在 Codeforces 上的排名为 2727,相当于全球排名第 175 位的最佳人类竞技程序员。对于人工智能和整个技术而言,这绝对是一个超人的成果。

还要注意的是,codeforces 的最顶尖,比如前 100 名或前 50 名都有终身 CP 实践者,也就是:那些获得了 IOI 金牌并且仍然坚持竞争多年的人。

注意:o3 高计算成本不可用,因为定价和功能可用性仍有待确定。计算量大约是低计算配置的 172 倍。
由于可变推理预算,效率(例如计算成本)现在是报告绩效时的一个必需指标。我们已记录总成本和每项任务成本作为效率的初始代理。作为一个行业,我们需要找出什么指标最能跟踪效率,但从方向上看,成本是一个可靠的起点。
75.7% 的高效率得分符合 ARC-AGI-Pub 的预算规则(成本 < 10,000 美元),因此有资格在公共排行榜上名列第一!
87.5% 的低效率分数相当昂贵,但仍然表明,随着计算量的增加,新任务的性能确实会提高(至少达到这个水平)。
尽管每个任务的成本很高,但这些数字不仅仅是将强力计算应用于基准的结果。OpenAI 的新 o3 模型代表了 AI 适应新任务的能力的重大飞跃。这不仅仅是渐进式的改进,而是一个真正的突破,标志着 AI 能力与 LLM 先前的局限性相比发生了质的转变。o3 是一个能够适应从未遇到过的任务的系统,可以说在 ARC-AGI 领域接近人类水平的表现。
当然,这种通用性的成本很高,而且目前还不是很经济:你可以支付大约每项任务 5 美元的费用让人类解决 ARC-AGI 任务(我们知道,我们这样做了),同时仅消耗几美分的能源。与此同时,o3 在低计算模式下每项任务需要 17-20 美元。但在未来几个月和几年内,性价比可能会大幅提高,因此你应该计划让这些功能在相当短的时间内与人类工作相媲美。
o3 相对于 GPT 系列的改进证明了架构就是一切。你无法在 GPT-4 上投入更多计算并获得这些结果。简单地将我们在 2019 年到 2023 年所做的事情扩大到现有规模(采用相同的架构,在更多数据上训练更大的版本)是不够的。进一步的进步需要新的想法。
那么它是 AGI 吗?
ARC-AGI 是检测AGI突破的关键基准,它以饱和或要求较低的基准无法做到的方式突出了泛化能力。然而,值得注意的是,ARC-AGI 并不是 AGI 的试金石——正如我们今年重复了几十次的那样。它是一种研究工具,旨在关注人工智能中最具挑战性的未解决问题,过去五年来,它很好地履行了这一职责。
通过 ARC-AGI 并不等同于实现 AGI,事实上,我认为o3 还不是 AGI。o3 在一些非常简单的任务上仍然失败,这表明与人类智能存在根本差异。
此外,早期数据点表明,即将推出的 ARC-AGI-2 基准测试仍将对 o3 构成重大挑战,即使在高计算量的情况下,也可能将其得分降低到 30% 以下(而聪明的人即使没有经过训练也能得分超过 95%)。这表明,在不依赖专家领域知识的情况下,仍有可能创建具有挑战性的、不饱和的基准测试。当创建对普通人来说很容易但对人工智能来说很难的任务变得根本不可能时,你就会知道 AGI 已经到来了。
与老款o1相比有何不同?
为什么 o3 的得分比 o1 高这么多?为什么 o1 的得分一开始就比 GPT-4o 高这么多?我认为这一系列结果为 AGI 的持续追求提供了宝贵的数据点。
我对 LLM 的心理模型是,它们充当矢量程序的存储库。当出现提示时,它们将获取提示所映射到的程序,并在手头的输入上“执行”它。LLM 是一种通过被动接触人工生成的内容来存储和操作数百万个有用的小程序的方法。
这种“记忆、获取、应用”范式可以在给定适当的训练数据的情况下在任意任务中实现任意水平的技能,但它无法适应新事物或即时掌握新技能(也就是说,这里没有流体智力在起作用)。LLM 在 ARC-AGI 上的低表现就是一个例证,ARC-AGI 是唯一专门用于衡量适应新事物能力的基准——GPT-3 得分为 0,GPT-4 得分接近 0,GPT-4o 得分为 5%。将这些模型扩展到可能的极限并没有使 ARC-AGI 数字接近几年前基本蛮力枚举所能达到的水平(高达 50%)。
要适应新事物,你需要两样东西。首先,你需要知识——一组可重复使用的函数或程序。LLM 有足够多的知识。其次,你需要有能力在面对新任务时将这些函数重新组合成一个全新的程序——一个模拟手头任务的程序。程序综合。LLM 长期以来一直缺乏这一功能。o 系列模型解决了这个问题。
目前,我们只能推测 o3 的确切工作原理。但 o3 的核心机制似乎是在标记空间内搜索和执行自然语言程序——在测试时,该模型会在描述解决任务所需步骤的可能的思路链 (CoT) 空间中进行搜索,其方式可能与 AlphaZero 风格的蒙特卡洛树搜索不太相似。在 o3 的情况下,搜索大概是由某种评估器模型引导的。值得注意的是,Demis Hassabis 在2023 年 6 月的一次采访中暗示DeepMind 一直在研究这个想法——这项工作已经酝酿了很长时间。
因此,虽然单代 LLM 难以实现新颖性,但 o3 通过生成和执行自己的程序克服了这一问题,其中程序本身(CoT)成为知识重组的产物。虽然这不是测试时知识重组的唯一可行方法(您也可以进行测试时训练或在潜在空间中搜索),但它代表了这些新的 ARC-AGI 数字所代表的当前最先进水平。
实际上,o3 代表了一种深度学习引导的程序搜索形式。该模型在“程序”空间(在本例中为自然语言程序 – 描述解决手头任务步骤的 CoT 空间)上进行测试时搜索,由深度学习先验(基础 LLM)引导。解决单个 ARC-AGI 任务最终会占用数千万个 token 并花费数千美元,原因是这个搜索过程必须探索程序空间中的大量路径 – 包括回溯。
然而,这里发生的事情与我之前描述的“深度学习引导程序搜索”是实现 AGI 的最佳途径之间存在两个显著差异。至关重要的是,o3 生成的程序是自然语言指令(由 LLM“执行”),而不是可执行符号程序。这意味着两件事。首先,它们无法通过执行和对任务的直接评估与现实联系——相反,它们必须通过另一个模型来评估其适用性,而缺乏这种基础的评估在超出分布的情况下可能会出错。其次,系统无法自主获得生成和评估这些程序的能力(就像 AlphaZero 这样的系统可以自己学习玩棋盘游戏一样)。相反,它依赖于专家标记的、人工生成的 CoT 数据。
目前尚不清楚新系统的具体局限性以及其可扩展性。我们需要进一步测试才能找到答案。无论如何,目前的表现代表着一项了不起的成就,并明确证实了直觉引导的程序空间测试时间搜索是构建可适应任意任务的 AI 系统的强大范例。
接下来是什么?
首先,2025 年 ARC 奖竞赛推动的 o3 开源复制对于推动研究界的发展至关重要。有必要对 o3 的优势和局限性进行彻底分析,以了解其扩展行为、潜在瓶颈的性质,并预测进一步的发展可能释放哪些能力。
此外,ARC-AGI-1 现在已经饱和 – 除了 o3 的新分数之外,事实是大量低计算的 Kaggle 解决方案现在可以在私人评估中获得 81% 的分数。
我们将通过新版本 ARC-AGI-2 提高标准,该版本自 2022 年以来一直在筹备中。它承诺将对最先进的技术进行重大重置。我们希望它能够通过突出当前 AI 局限性的严格、高信号评估来突破 AGI 研究的界限。
我们早期的 ARC-AGI-2 测试表明,它非常有用且极具挑战性,即使对于 o3 来说也是如此。当然,ARC Prize 的目标是开发出一种高效且开源的解决方案,以赢得大奖。我们目前打算与 ARC Prize 2025 一起推出 ARC-AGI-2(预计发布时间:第一季度末)。
展望未来,ARC 奖基金会将继续创建新的基准,以将研究人员的注意力集中在 AGI 道路上最难解决的未解决问题上。我们已经开始研究第三代基准,该基准完全不同于 2019 年的 ARC-AGI 格式,并融入了一些令人兴奋的新想法。
参与:开源分析
今天,我们还发布了高计算量、o3 标记的任务,希望您能帮助分析它们。特别是,我们非常好奇约 9% 的公共评估任务 o3 无法解决,即使需要大量计算,但对人类来说却很简单。
我们邀请社区帮助我们评估已解决和未解决的任务的特征。
为了激发您的想法,这里有 3 个高计算 o3 未解决的任务示例。

ARC-AGI 任务 ID:c6e1b8da
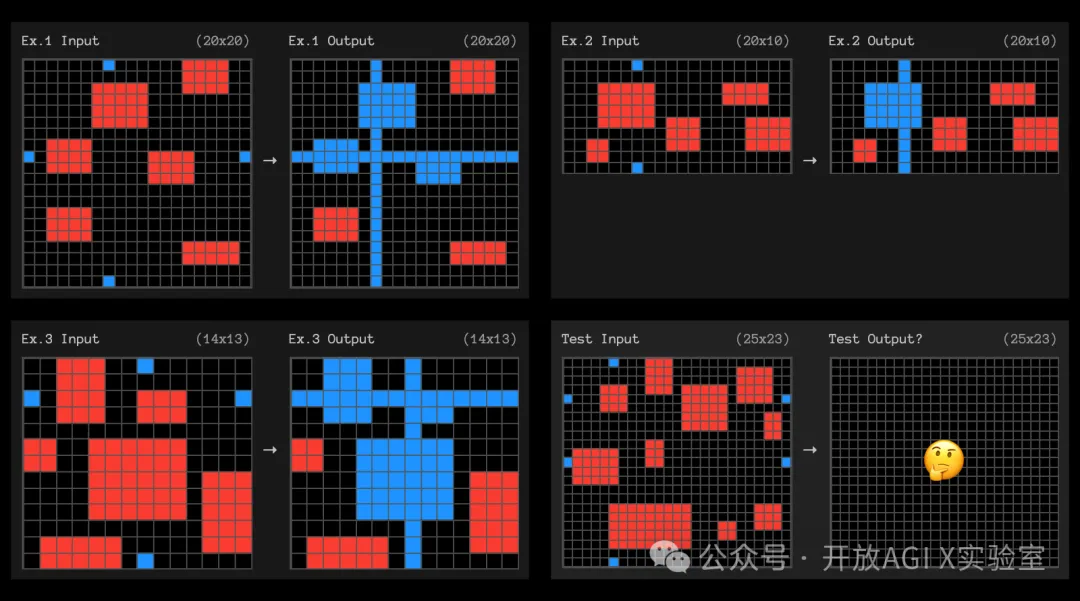
ARC-AGI 任务 ID:0d87d2a6

ARC-AGI 任务 ID:b457fec5
结论
总结一下,o3 代表了一次重大飞跃。它在 ARC-AGI 上的表现凸显了适应性和泛化方面的真正突破,这是其他任何基准都无法如此明确地体现出来的。
o3 解决了 LLM 范式的根本限制——无法在测试时重新组合知识——它通过 LLM 引导的自然语言程序搜索来实现这一点。这不仅仅是渐进式的进步;这是一个新领域,需要认真的科学关注。
寄语:
2024年即将收官,AGI元年,人工智能在系统2推理方面得到了长足的进步,我们参考人类的思维模式,如果从系统1,系统2的角度理解,AGI的雏形已经形成。当然AGI是新物种,会有新物种的特性,正如和生命的进化,都是随机的,谁也无法预测最终AGI的形态。

生命起源














暂无评论内容