人类沟通是多模态的,意味着我们不仅通过语言来交流,还通过面部表情、肢体动作等非语言的方式来传递信息。在理解人类互动和创建能够自然交流的虚拟角色(比如在游戏、电影和虚拟现实中)时,模拟这些行为非常重要。然而,现有的运动生成模型通常只关注某一特定输入方式—可能是语言、文本或动作数据,并不能全面利用所有可用的数据。
为了解决这个问题,斯坦福大学李飞飞团队提出了一个新的框架(LOM),能够将语言(包括口语和非语言)结合起来,使用多模态语言模型来理解和生成人体动作。这个模型非常灵活,能够接受文本、语音、动作数据,甚至是它们的组合作为输入。结合独特的预训练策略,LOM模型不仅在共同语音手势生成任务上达到了最先进的表现,而且训练所需的数据量大大减少。模型还可以完成一些新任务,比如可编辑的手势生成和通过动作预测情感。
01 技术原理
—
LOM使用针对不同输入方式(如音频、文本、动作等)的专用分词器来处理这些数据。具体来说,LOM训练了一个组合式的身体动作VQ-VAE模型,将面部、手部、上半身和下半身的动作转化为离散的“符号”,并将这些不同的符号集合(包括音频和文本)结合成一个统一的多模态词汇表。
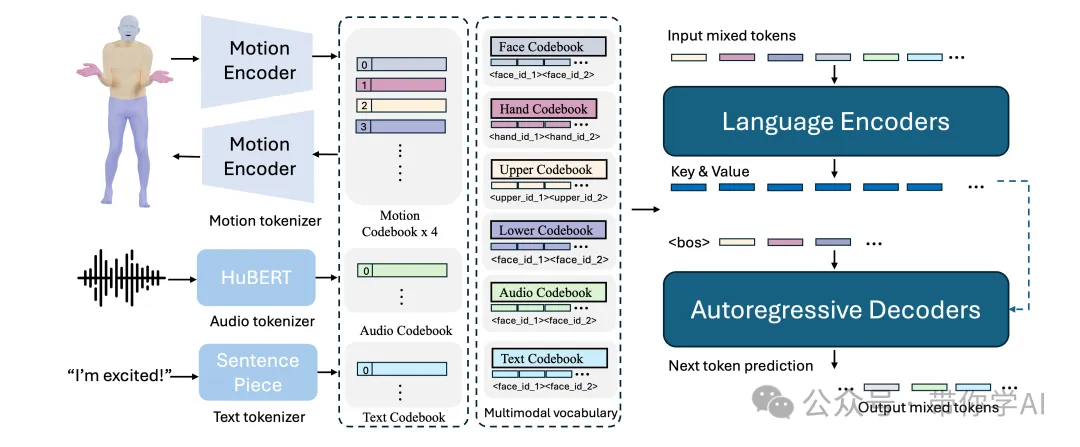
在训练过程中,将来自不同模态的混合符号作为输入,然后通过一个编码-解码语言模型生成输出。LOW这些混合符号输入到transformer编码器中,解码器则通过自回归方式逐步预测下一个符号的概率。
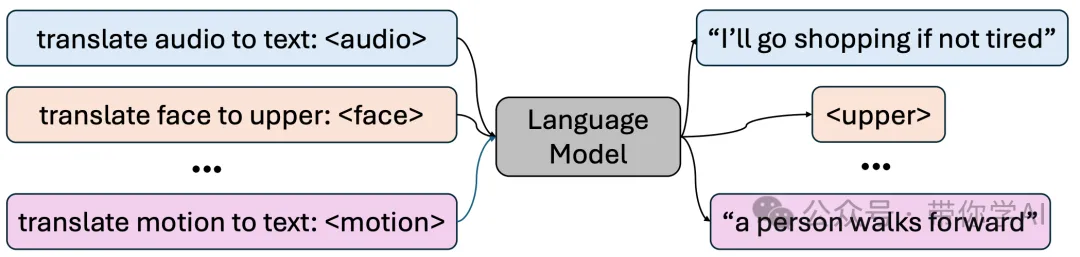
现有的动作生成模型通常依赖大量配对的数据来训练下游任务。然而,收集高质量的配对动作数据既昂贵又费时,而每种数据模态中都有大量未配对的数据是可以利用的。受到这一点的启发,提出了生成式预训练策略。具体来说,在预训练阶段,LOW实现了两种模态对齐方法:组合式动作对齐和音频-文本对齐。
© 版权声明
THE END














暂无评论内容