生成可控人物图像的目标是根据参考图像生成一个人物图像,并能精确控制人物的外貌或姿势。然而,尽管之前的方法能够生成高质量的整体图像,但常常会扭曲参考图像中的细节纹理。这种扭曲的原因,认为是因为模型在关注参考图像时,没有充分关注到对应的区域。
为了改善这一点,Meta提出了一种名为“Leffa”(注意力流场学习)的方法,专门帮助模型在训练时引导目标查询准确关注到参考图像中的正确区域。Leffa在控制人物外观(虚拟试穿)和姿势(姿势转移)方面,表现出了当前最好的效果,显著减少了细节失真,并且保持了图像的高质量。此外,Leffa方法是通用的,可以应用于其他扩散模型,提升它们的表现。
01 技术原理
—
Leffa生成的图像质量很高,细节保留得非常好,纹理失真很少。(实际效果可以运行后放大查看,以获得更清晰的效果。)

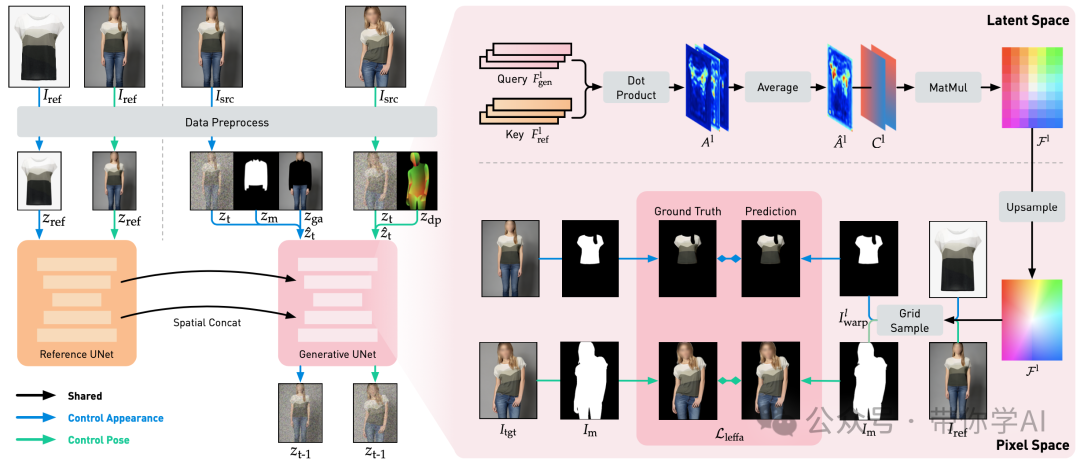
Leffa训练流程概述:左侧是基于扩散的基础模型,右侧是加入Leffa损失后的模型。需要注意的是,在训练过程中,Isrc和Itgt其实是同一张图像。
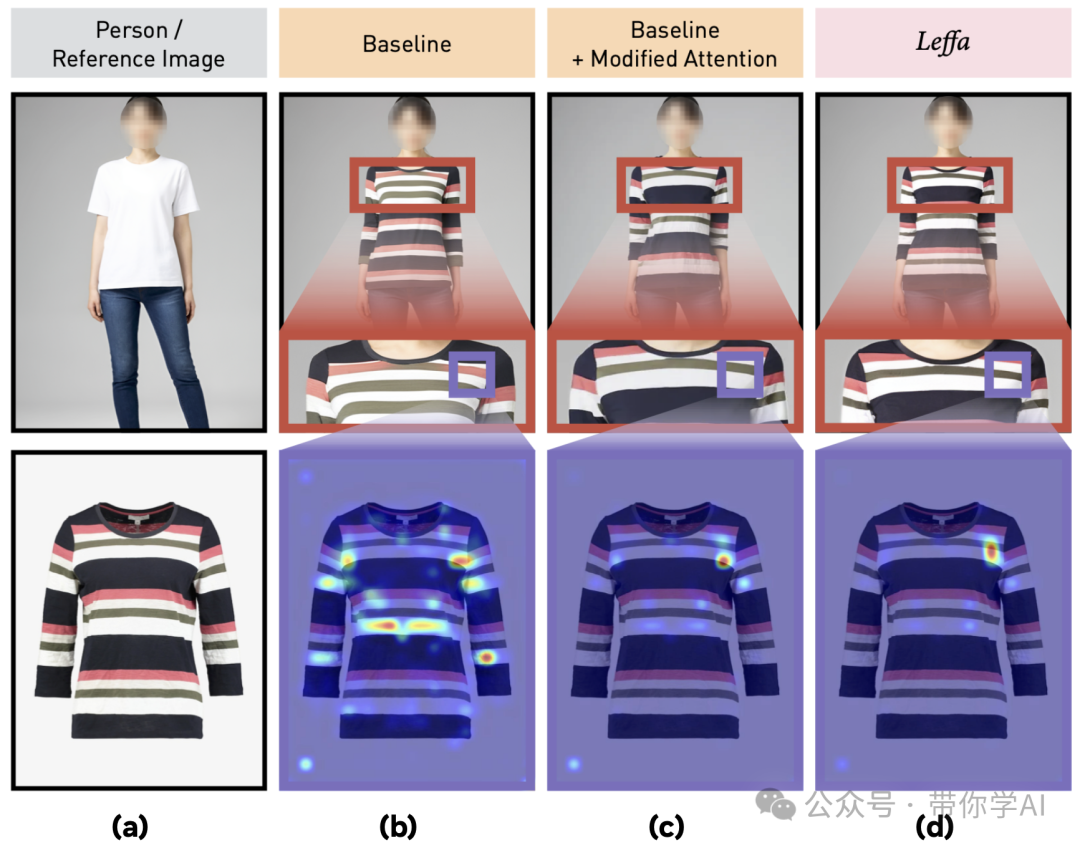
以人物图像的外观控制(虚拟试穿)为例:Leffa能够生成高质量的图像,没有细节失真(请看彩条纹理部分)。
(a) 输入人物和参考(服装)图像;(b) 使用基于扩散的方法生成的图像及其注意力图(例如,IDM-VTON);(c) 手动修改扩散方法中的注意力图,使其聚焦于正确的区域后生成的图像;(d) 使用Leffa生成的图像及其注意力图。
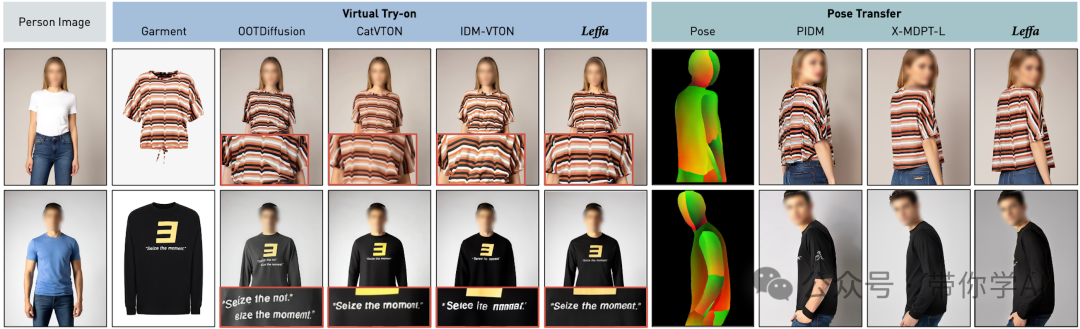
与其他方法的定性视觉效果比较:用于姿势转移的输入人物图像是通过Leffa方法在虚拟试穿中生成的。可视化结果表明,Leffa方法不仅生成了高质量的图像,还大大减少了细节失真。
02 实际效果
—
安装和运行Gradio非常简单:(也可以在线体验)
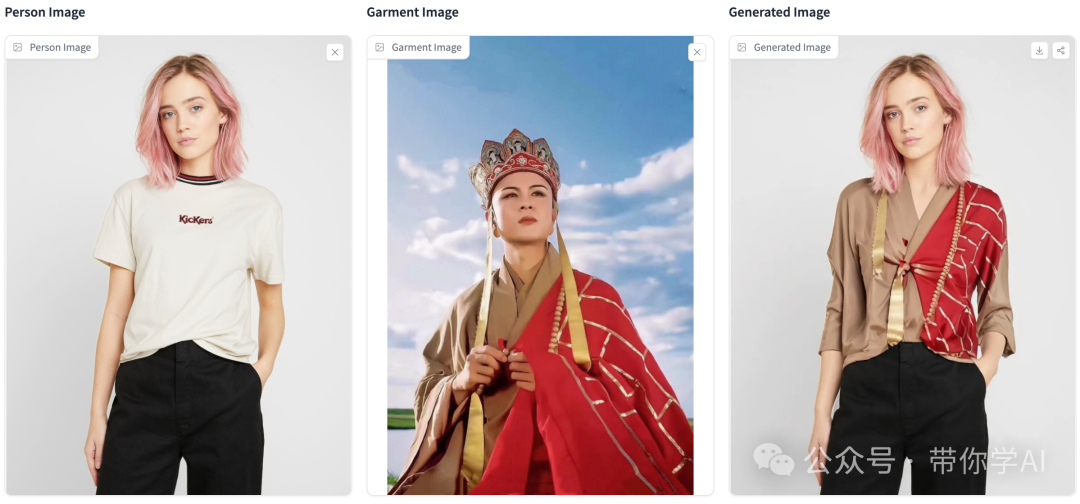
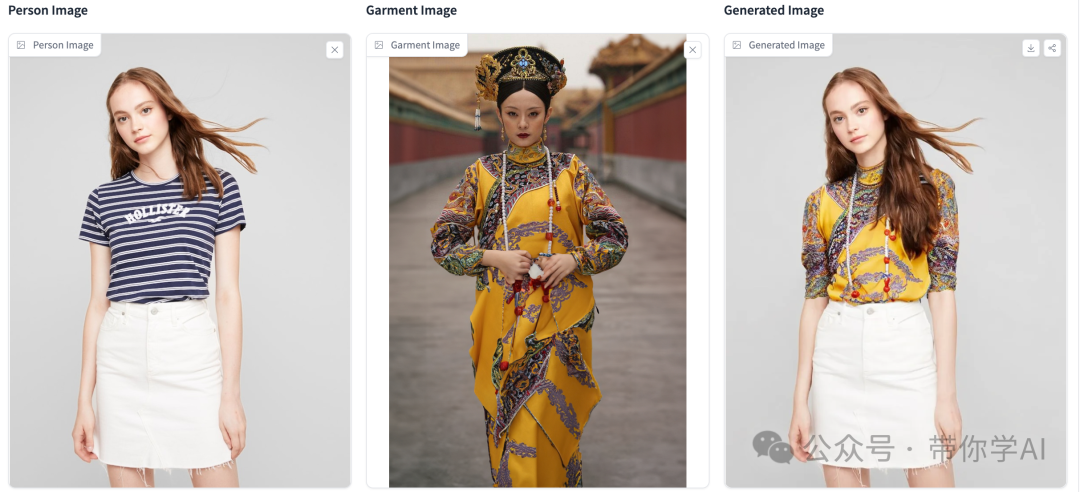
在线演示效果(左侧原始图像、中间参考图像、右侧生成结果):
 衣服、身体等局部细节放大(可以看到细节很好):
衣服、身体等局部细节放大(可以看到细节很好): 














暂无评论内容