现有的多视图图像生成方法往往需要对预训练的文本到图像(T2I)模型进行大幅度的改动,还需要全面微调,这带来了两个主要问题:计算成本高,特别是在处理大型基础模型和高分辨率图像时,这种方法非常耗资源;图像质量下降,由于优化过程困难以及高质量3D数据稀缺,生成的图像质量常常无法达到预期。
基于以上问题,北航提出了第一个基于适配器的多视图图像生成解决方案,名为MV-Adapter。它是一种多功能的即插即用适配器,能够在不改变原有网络结构或特征空间的情况下增强T2I模型及其衍生模型。MV-Adapter 在 Stable Diffusion XL (SDXL) 上实现了高达768分辨率 的多视图图像生成,并展示了出色的适应性和多功能性。它还能扩展到任意视角生成,为更广泛的应用打开了新大门。
01 技术原理
—
MV-Adapter 是一种即插即用的适配器,能够学习多视图的先验知识,并将这些知识迁移到 T2I 模型的不同变体中,无需特别调整。它让 T2I 模型在各种条件下生成多视图一致的图像。
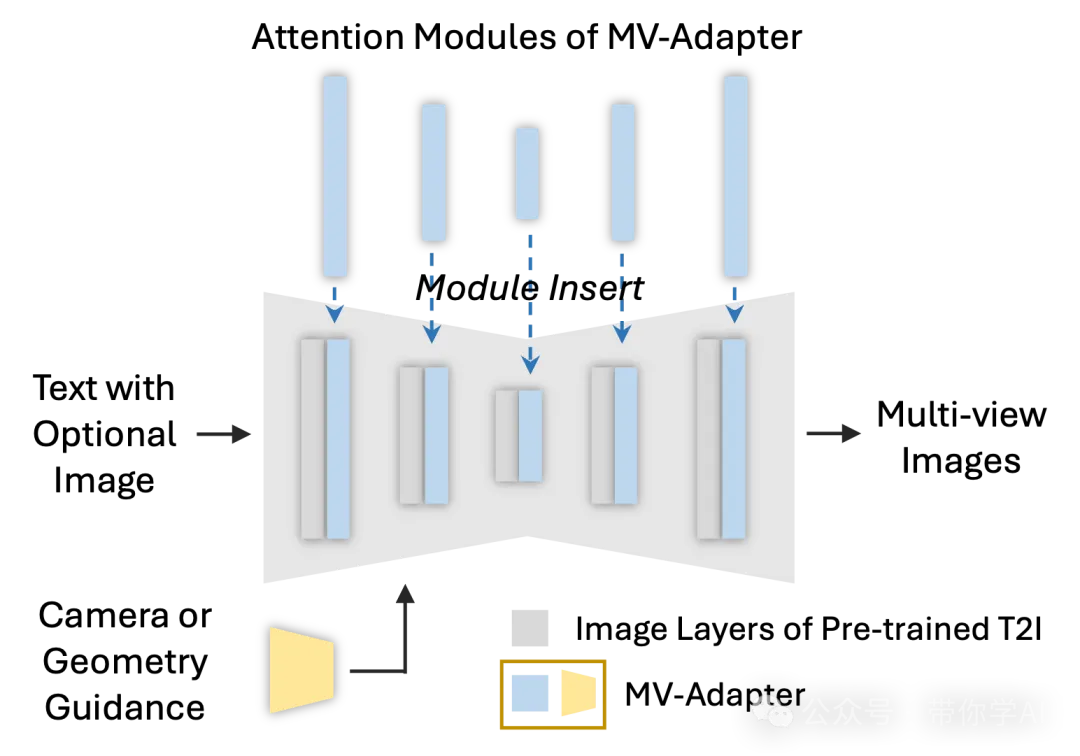
在推理阶段,MV-Adapter 包含一个条件引导器(黄色部分)和解耦注意力层(蓝色部分)。它可以直接插入到定制版或简化版的 T2I 模型中,变身为一个能够生成多视图图像的工具。
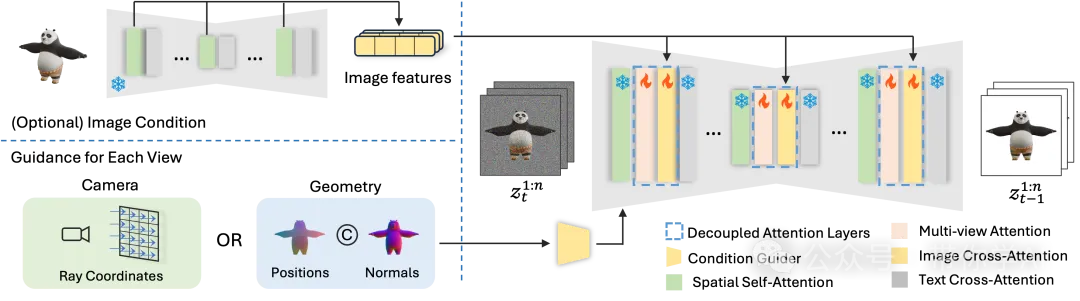
MV-Adapter 有两个主要组成部分:
- 条件引导器:用于编码相机条件或几何条件,让模型能更好地理解视角或空间信息。
- 解耦注意力层:包含多视图注意力层,用来学习多视图的一致性。同时还有可选的图像交叉注意力层,支持基于图像生成的功能。这里用预训练的 U-Net 对参考图像进行编码,提取细致的信息供生成使用。
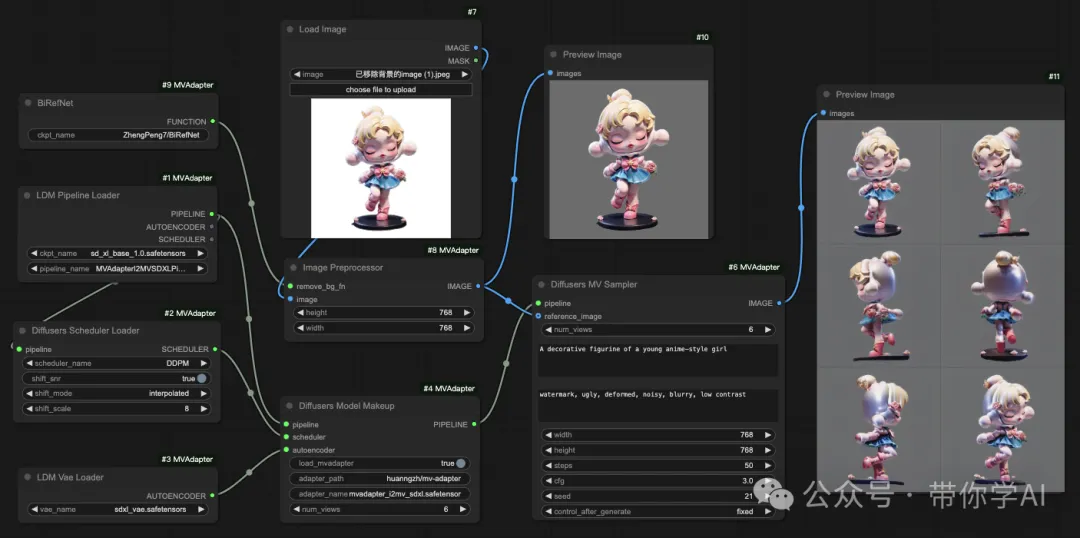
支持ComfyUI:
© 版权声明
THE END














暂无评论内容