“无监督强化学习(RL)”的目标是预训练出一种能够在复杂环境中解决各种后续任务的智能体。虽然这一领域最近取得了不少进展,但现有方法仍存在一些问题:要想在某些任务上表现出色,可能仍需要对每个任务运行一次强化学习;需要用到覆盖面良好的数据集或精心挑选的任务样本;或者使用的无监督损失与后续任务的关联性较差。
基于此,Meta提出了一种新算法,通过利用无标签的行为数据集中的轨迹进行模仿,来改进无监督强化学习。这种方法的技术创新点被称为“前向-后向表示与条件策略正则化”。为验证这种方法的效果,训练了一个名为META MOTIVO的模型,这是第一个能够解决多种全身任务的“人形行为基础模型”。这些任务包括动作跟踪、目标到达和奖励优化等。这个模型不仅能够表现出逼真的人类行为,还在任务表现上达到了专用方法的竞争水平,同时超越了最先进的无监督强化学习和基于模型的方法。
01 技术原理
—
Forward-Backward Representations with Conditional Policy Regularization (FB-CPR) 是一种新算法,它结合了无监督的前后向表示学习和一种特殊的模仿学习机制,帮助策略学习覆盖未标注轨迹数据中的状态。
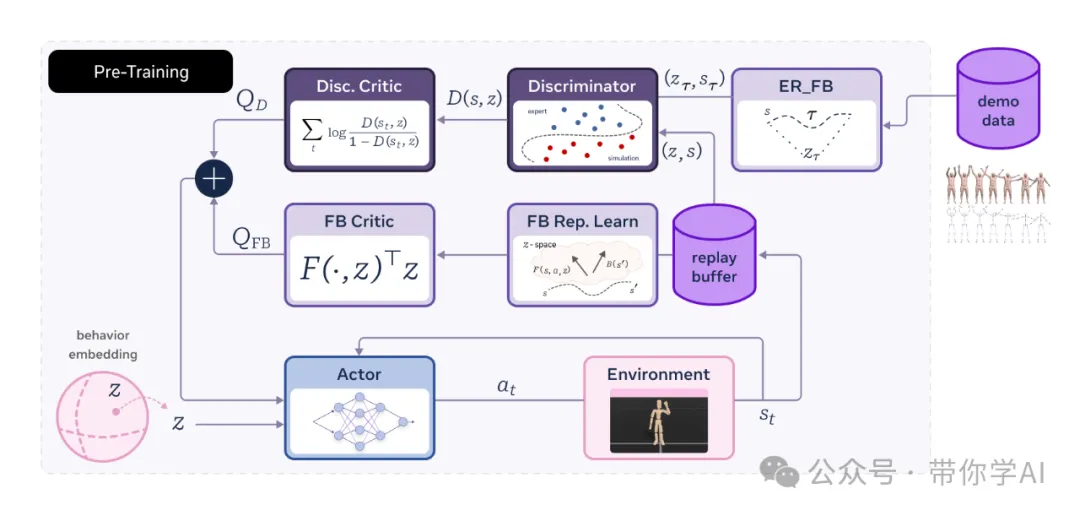
FB-CPR 是在直接与环境交互的过程中进行在线训练的,关键在于它学会了一种“统一的表示方式”,把状态、动作和奖励映射到同一个潜在空间中。这样,算法可以更好地理解行为和奖励的关系。结果就是,可以训练出更“聪明”的模型,不仅能实现目标导向的强化学习、模仿学习,还能优化奖励和完成目标跟踪,而且可以直接在新任务中“无缝上手”,不需要重新调整。
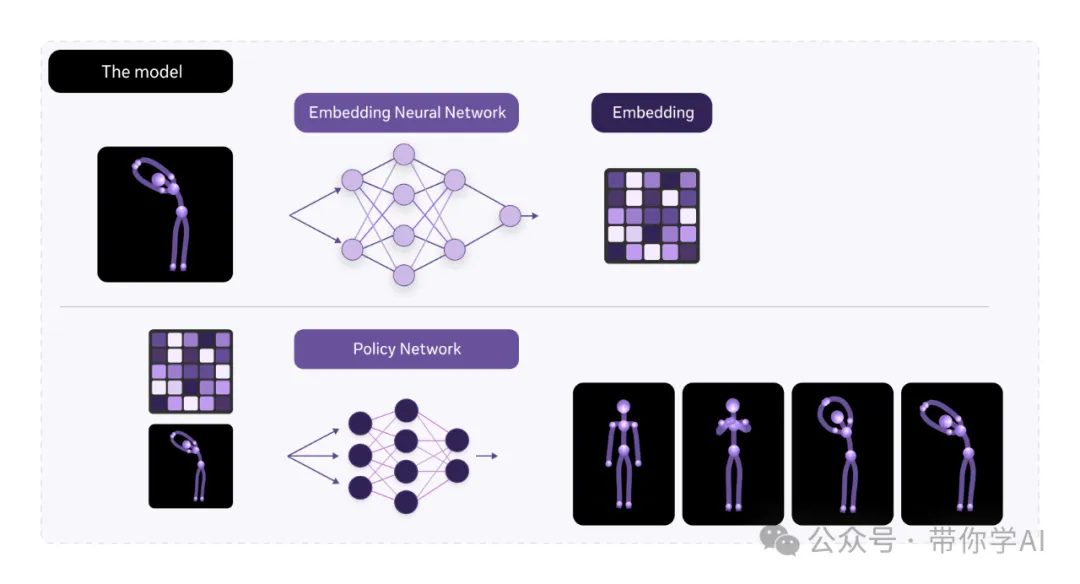
- 嵌入网络:这个网络的作用是接收智能体的状态(比如它现在的位置、环境信息等),然后把这些信息转化为一种更简单、更易处理的“内部表示”(也就是嵌入)。
- 策略网络:这个网络用的是和嵌入网络一样的“内部表示”,它会根据输入的状态信息,决定智能体下一步该采取的行动。
© 版权声明
THE END














暂无评论内容