“角色图像动画”技术可以从一张参考图像和一组目标动作序列生成高质量的视频。近年来,这项技术取得了显著进展。然而,大多数现有方法只适用于人类角色,往往很难泛化到像游戏和娱乐行业常用的拟人化角色上。经过深入分析,这种限制主要是因为这些方法对动作的建模不够完善,无法很好地理解驱动视频中的运动模式,而是将动作序列僵硬地套用在目标角色上。
为了解决这个问题,蚂蚁集团提出了一种通用动画框架—Animate-X,它基于LDM(潜在扩散模型),可以处理各种角色类型(统称为“X”),包括拟人化角色。为了加强对动作的理解,引入了一个“动作指示器”(Pose Indicator),它可以通过隐式和显式的方式捕捉驱动视频中的运动模式。
01 技术原理
—
Animate-X设计了两个关键模块:隐式姿态指示器(IPI)和显式姿态指示器(EPI)。它们分别生成动作特征和姿态特征。接着,把动作特征和噪声输入在通道维度上拼接起来,再把姿态特征在时间维度上拼接进去,形成一个综合输入送入扩散模型中进行逐步去噪。
首先,从一张参考图像中提取特征,包括通过 CLIP 提取的图像特征和通过 VAE 提取的潜在特征。此外,提出了两种特征生成方式:隐式姿态指示器(IPI)和显式姿态指示器(EPI),分别生成运动特征和姿态特征。
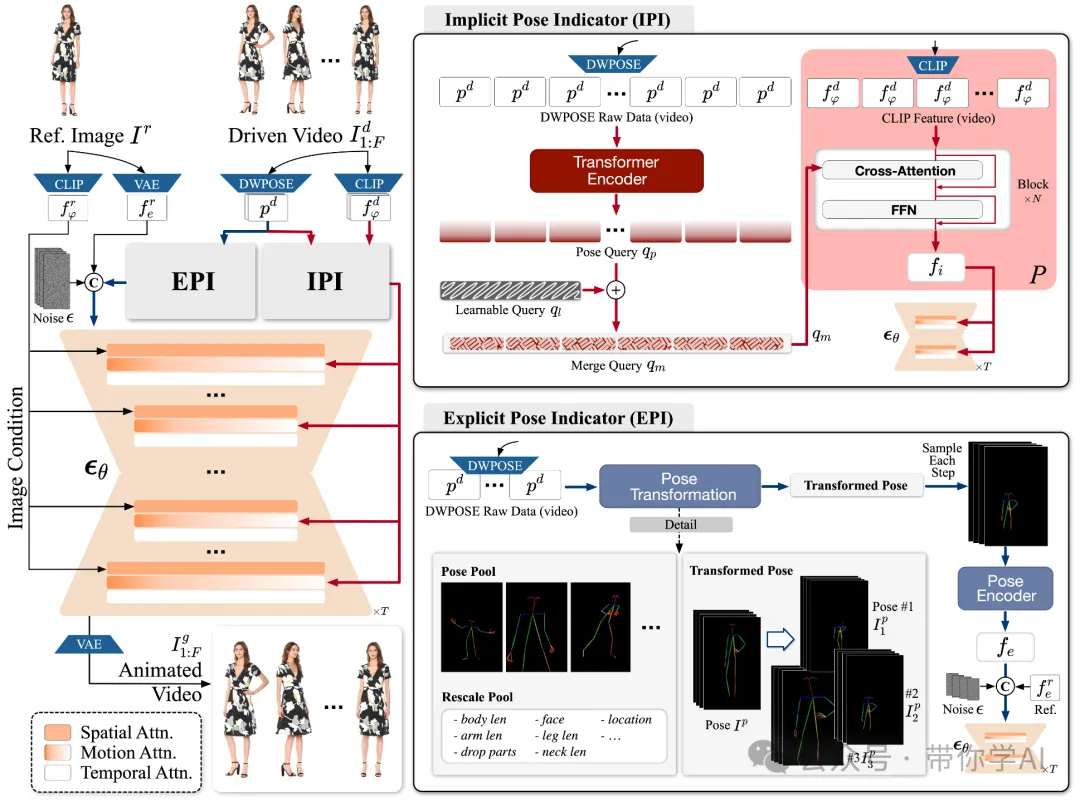
接着,把和带噪声的输入按通道维度拼接在一起,并在时间维度上继续与 拼接。这些拼接后的数据作为扩散模型的输入,逐步去除噪声。在这个过程中,和分别提供了参考图像的外观信息和运动信息。最后,通过 VAE 解码器将生成的潜在表示 转换为动画视频。
02 对比与演示效果
—
基于GAN的LIA泛化能力较差,图像的角色身份发生了变化,而且生成的动作与参考姿态不够准确。虽然ControlNeXt在一定程度上保持了角色身份和动作转移的一致性,但生成的结果仍显得不够自然。

相比之下,Animate-X 在保持角色身份和参考图像动作一致性的同时,还能够生成富有表现力且略带夸张的动作,而不是简单复制目标角色的“静态”动作。
由于蚂蚁集团审核机制原因,代码尚未开源,敬请期待!2024 11.25Github进度更新,未来会在Github antgroup 所属下发布。














暂无评论内容