当前的视频扩散模型生成效果非常出色,但在交互式应用中却存在一个大问题:它们依赖双向注意力机制。这意味着生成单帧视频时,模型需要处理整个序列,包括未来的帧,导致效率非常低下。为了解决这个问题,MIT-Adobe对预训练的双向扩散变换器进行了改造,让它变成一个因果变换器,可以“即用即生成”视频帧。
为了进一步降低延迟,把“分布匹配蒸馏”(DMD)技术扩展到了视频领域,将原来需要50步的扩散模型压缩成仅需4步的生成器。模型可以以 9.4 FPS 的速度在单张 GPU 上流畅地生成高质量视频。此外,CausVid方法还支持流媒体视频到视频的转换、图像到视频的生成,以及动态提示的零样本生成。
01 技术原理
—
传统的双向扩散模型(下图(上))虽然输出质量很高,但生成速度太慢,生成一个128帧的视频需要整整219秒。而且,用户必须等到整个视频生成完成后,才能看到结果。相比之下,CausVid方法(下图(下))通过将双向扩散模型“压缩”成一个只需几步的因果生成器,大幅减少了计算开销。CausVid初始延迟仅为1.3秒,随后以大约9.4帧/秒的速度连续生成视频帧,像流媒体一样实时输出。这让视频内容的创作更加高效和互动!
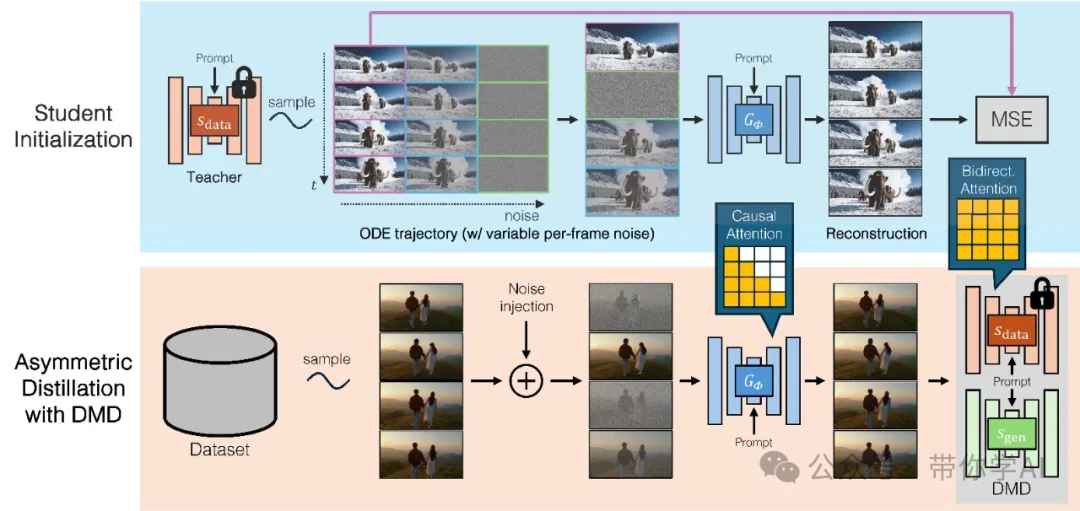
为了进一步降低延迟,将分布匹配蒸馏(DMD)扩展到视频上,将50步的扩散模型蒸馏成一个4步的生成器。为了确保蒸馏的稳定性和高质量,引入了一种基于教师模型ODE轨迹的学生初始化方案,并采用了非对称蒸馏策略,即使用双向教师来监督一个因果学生模型。这种方法有效地减轻了自回归生成中的误差累积问题,使得即使只在短视频片段上进行训练,也能够合成时长较长的视频。
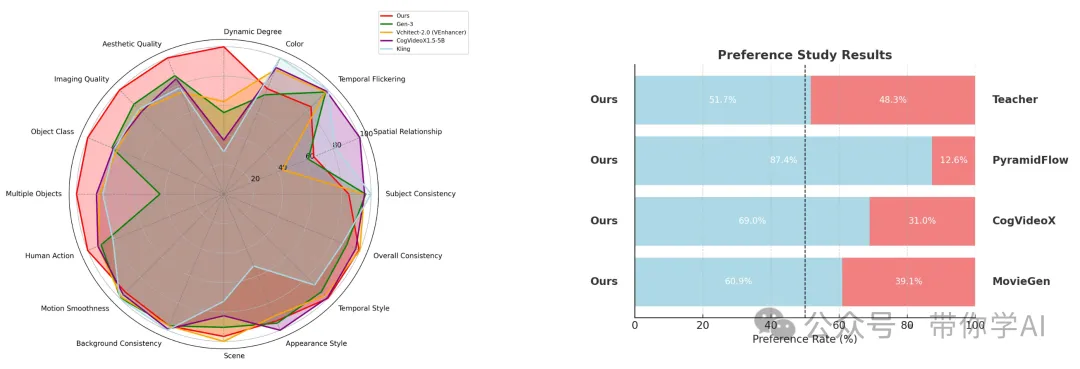
CausVid模型在 VBench-Long 数据集上取得了总分 82.85,超越了所有已发布的方法,同时还能在单张 GPU 上以 9.4 帧/秒的速度实现快速流式推理,这在业界独一无二。雷达图清晰展示了CausVid方法在多个关键指标上的全面优势,包括动态表现、画面美感、图像质量、物体类别、多物体场景以及人类动作等方面。
02 演示结果
—
文字转10秒短视频生成:CausVid模型从文本生成高质量视频,初始延迟仅为 1.3 秒,之后在单个 GPU 上以大约 9.4 FPS 的流式传输方式连续生成帧。
文字转60秒长视频生成:虽然生成器是在 10 秒视频上进行训练的,但其自回归性质使其能够使用滑动窗口推理生成无限长度的视频。
零样本图像到视频生成:由于模型的自回归性质,本质上支持零样本(文本条件)图像到视频的生成。














暂无评论内容