AI自动生成主播风格的产品推广视频,为在线电商、广告和消费者互动提供了巨大的商机。然而,尽管人体姿态引导视频生成技术已有很大进展,这个任务依然充满挑战。如何将人类与物体的互动(HOI)融入姿态引导的视频生成中,成为了关键难题。为了解决这个问题,中国科学院计算技术研究所与美团提出了AnchorCrafter,一个基于扩散技术的创新系统,它可以生成包含目标人物和定制物体的2D视频,且能够高保真地呈现图像效果和可控的互动场景。
具体来说,AnchorCrafter提出了两个关键创新:一是“HOI外观感知”,它能够从不同角度识别物体外观,同时将物体和人物的外观分开处理;二是“HOI动作注入”,它通过克服物体轨迹控制和遮挡管理的挑战,使得复杂的人物与物体互动成为可能。此外,还提出了“HOI区域重加权损失”这一训练目标,来进一步提高物体细节的学习效果。
01 技术原理
—
AnchorCrafter的训练流程(下图):基于视频扩散模型,AnchorCrafter通过HOI-外观感知将人物和多个视角的物体信息注入到视频中。动作通过HOI-动作注入来控制,训练目标在HOI区域进行了重新加权。
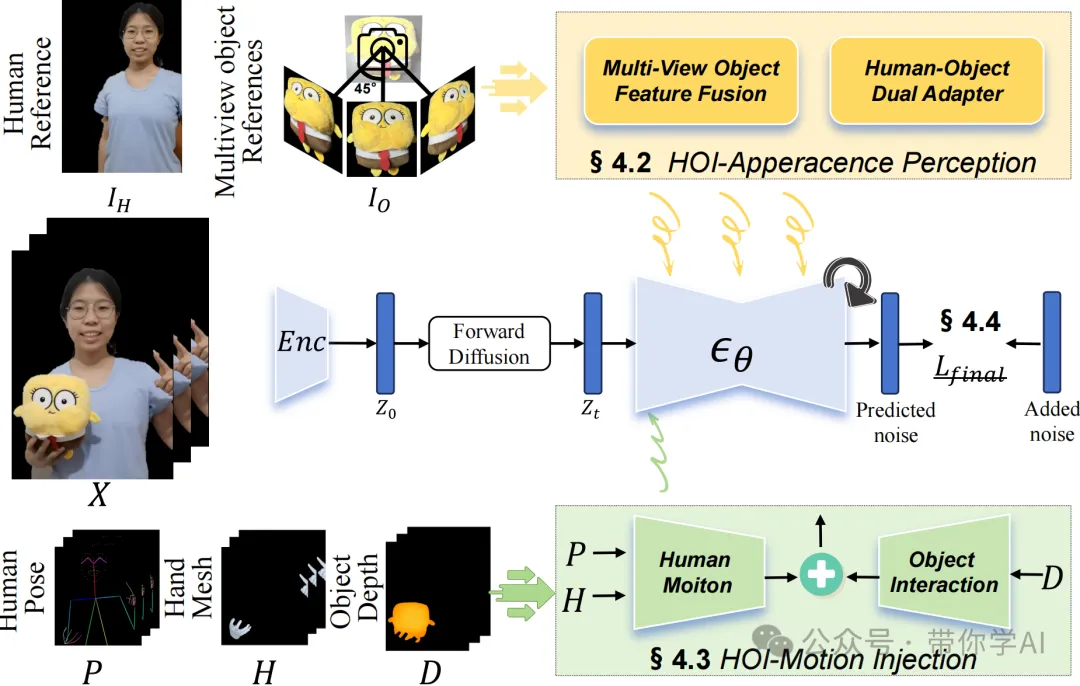
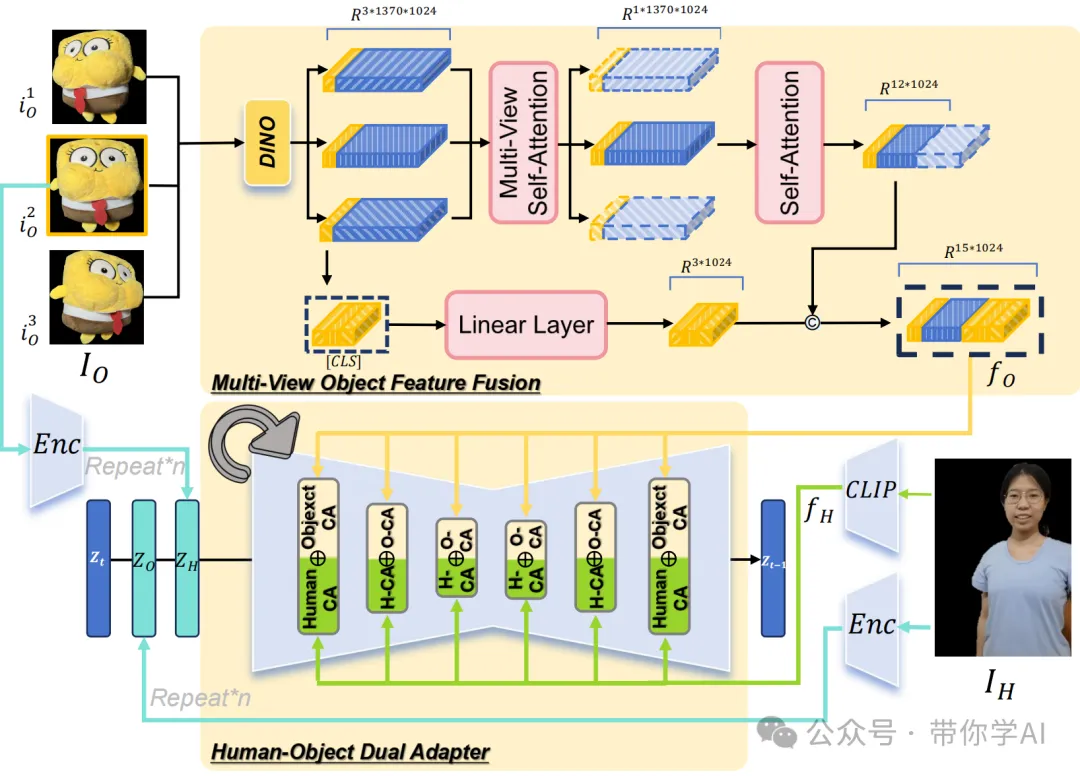
HOI-外观感知(下图):通过多视角物体特征融合提取目标物体的特征fO,并将其与人物参考特征fH结合,使用人-物双适配器来实现更好的特征分离效果。
当用参考图像动画化一个人手持物体时,现有的方法虽然能准确跟踪人体姿势,但往往无法生成手与物体的互动(比如AnimateAnyone),或者把物体误当作人体的一部分,导致没有任何动作(比如MimicMotion)。而AnchorCrafter方法能够准确生成人物与物体的互动,同时保持物体的外观不变。
© 版权声明
THE END














暂无评论内容