一、背景
前段时间的文章里我们刚刚介绍过两个对 LLM 分布式推理场景中 AllReduce 的优化工作,一个是 NVIDIA TensorRT-LLM 中的 MultiShot 无损优化,另一个是 Recogni 提出的基于量化压缩实现的 AllReduce 加速方案。本文中我们继续介绍美团新发表的 AllReduce 量化压缩优化方案。
二、摘要
随着 LLM 规模的不断增长,快速推理所需的分布式解决方案往往要利用多维并行性,将计算负载分散至 GPU 集群的多个设备上。然而,此方法往往会引入显著的通信开销,尤其在带宽受限的设备上(比如没有 NVLink 或者跨机的情况)。
本文中作者提出 Flash Communication,一种新颖的低比特压缩技术,旨在缓解推理过程中 Tensor Parallelism(TP)的通信瓶颈。作者在多种最新的 LLM 上进行的广泛实验,验证了该方法的有效性。该方法可以将节点内通信速度提升 3 倍,并将首 Token 时间缩短 2 倍,同时几乎不牺牲模型精度。
PS:上述的结论其实有点夸大,INT4 可以实现上述速度,但精度损失还是有点大的;而 INT8 可以保持精度,但加速比又没这么多。
三、引言
3.1 硬件拓扑
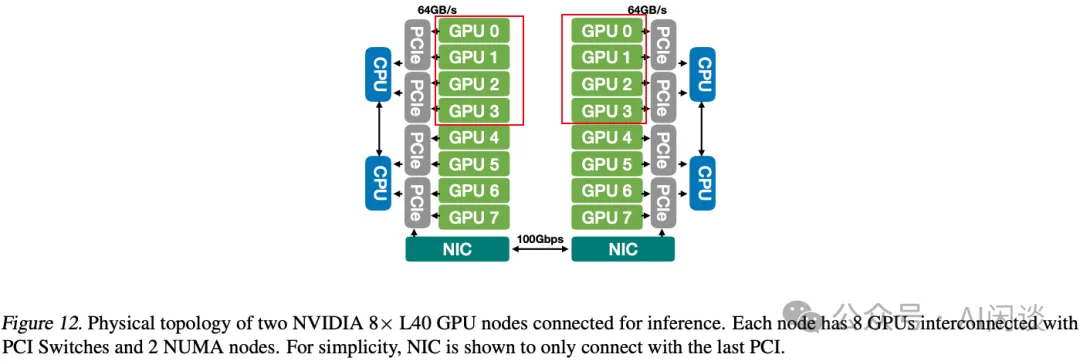
作者论文中评估主要采用了两种机型,一种是 8 x L40 GPU 节点,如下图 Figure 12 所示。每个节点上有 8 个 L40 GPU,每 2 个 GPU 在一个 PCIe Switch 下,没有 NVLink + NVSwitch,并且每个节点只有 1 个 100 Gbps 的 NIC。因此:
如果节点内的 TP 通信都需要走 PCIe 链路,如果是不同 CPU Socket 下的 GPU 通信,还需要通过 CPU 之间的 UPI,因此通信效率可能比较低。
如果节点间通信,则必须通过节点的 NIC,最糟糕的情况是左侧红框和右侧红框的 GPU 组成 TP 组进行通信。
PS:本文中作者并没有涉及节点间通信,甚至 L40 上的 TP=8 的 8 GPU 通信都没有。
而 A100 节点类似下图所示,节点内有 8 个 A100 GPU,这些 GPU 通过 NVLink + NVSwitch 实现全互联,任何两个 GPU 之间的通信带宽都可以达到 600 GB/s。不过作者介绍节点间通信带宽是 200 Gbps,那么可能节点上就没有红框中的 NIC,只有蓝框中的 200 Gbps NIC。(PS:论文中也不涉及节点间通信)
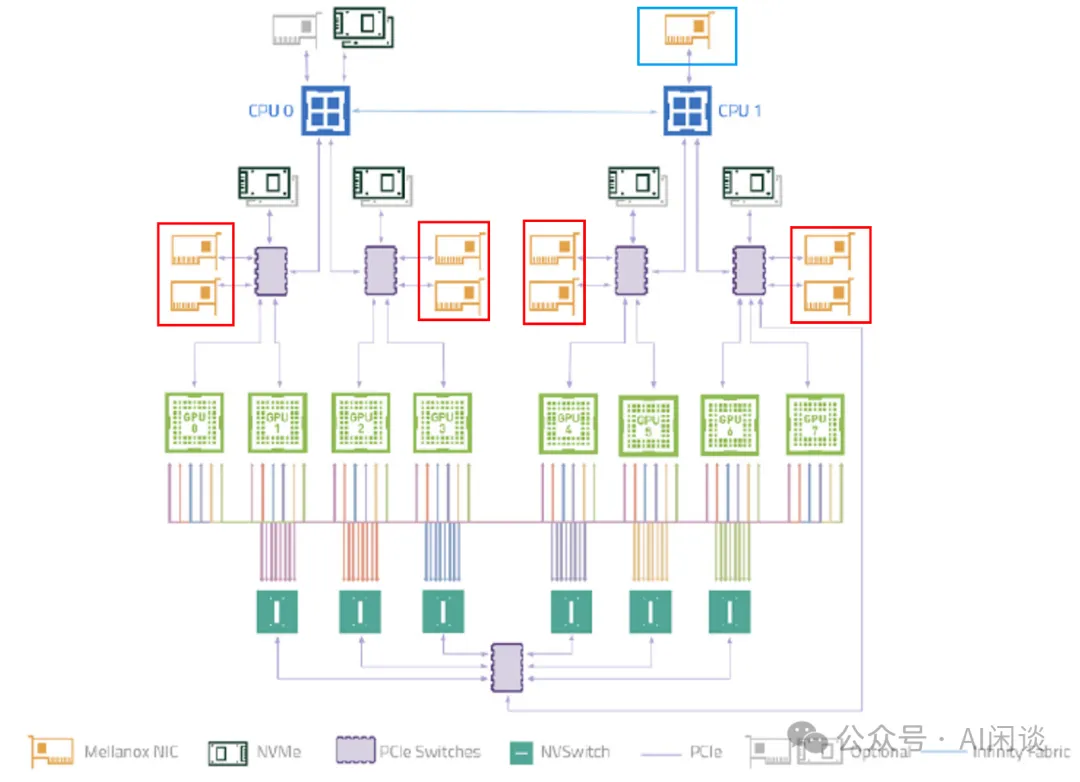
此外,A100 GPU 有 108 个 SM,而 L40 GPU 有 108 个 SM。
3.2 ReduceScatter + AllGather
我们在之前的文章中详细介绍过 AllReduce,这里再简单陈述一下。对于常见的基于 Ring 的 AllReduce 实现中,通常将一个 AllReduce 操作拆分为一个 ReduceScatter 和一个 AllGather 操作,如下图所示:
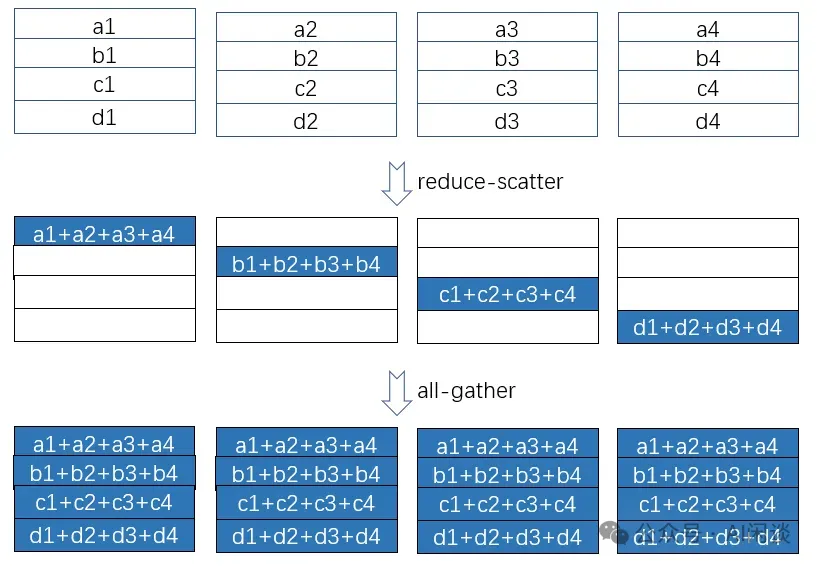
具体的 ReduceScatter 操作如下,每个设备(GPU)发送一部分数据给下一个设备,同时接收上一个设备的数据并累加。这个过程执行 K-1 步,ReduceScatter 后每个设备都包含一部分数据的 Sum:
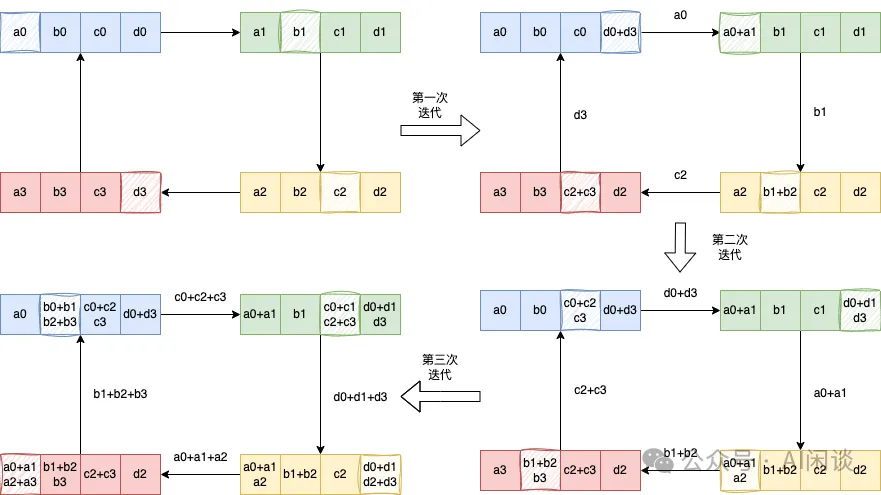
具体的 AllGather 操作如下,每个设备(GPU)将其持有的部分结果发送给下一个设备,同时接收上一个设备的部分结果,逐步汇集完整的结果,同样需要 K-1 步。AllGather 后,每个设备都包含全量的数据:
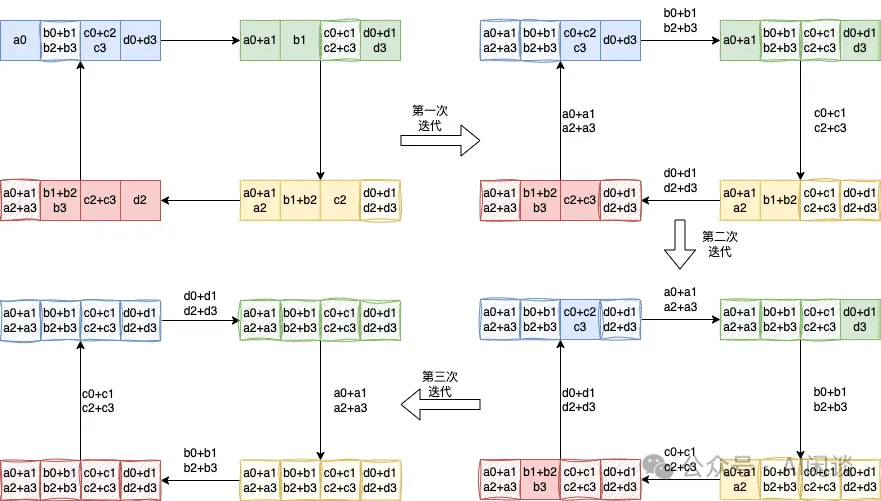
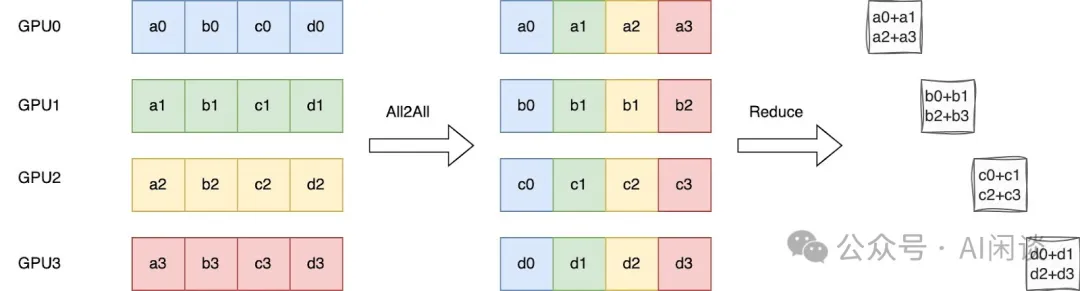
NVIDIA 在 3x Faster AllReduce with NVSwitch and TensorRT-LLM MultiShot | NVIDIA Technical Blog [2] 中并没有介绍 ReduceScatter 的优化,不过在我们推测其可能采用了下述的优化方式:具体来说,Ring ReduceScatter 可以等效为一个 All2All 操作实现数据的重排,然后在 Local 进行 Reduce 操作(或者 NVSwitch 上进行 Reduce 操作)。此过程只有一个 All2All 的整体通信操作,虽然实际上与 Ring 实现的方式的通信量和计算量没有变化,但可以避免 K-1 个 Ring Step 的同步,进而可以有效降低时延。
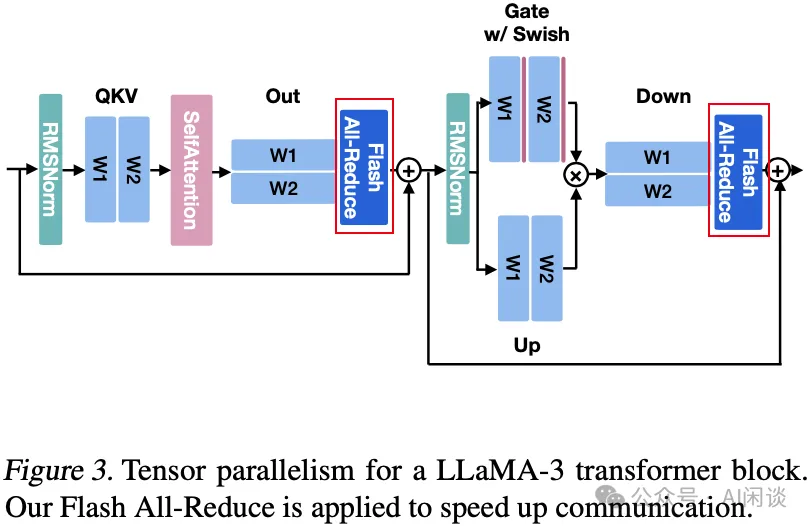
3.3 TP 推理
如下图 Figure 3 所示,对于 LLaMA 模型推理,其一个 Transformer Layer 需要 2 次 AllReduce 通信,不过需要 Attention 以及 FFN 都采用先列切再行切的方式。以 80 层的 LLaMA 3 70B 模型为例,一次 Forward 需要 180 次 AllReduce 通信。
3.4 延迟分析
如下图 Figure 2 所示,作者在 4*L40 GPU 上测量了 LLaMA-3-70B 模型在不同序列长度下各个部分的开销(Batch Size 为 8),可以看出,序列越长,AllReduce 的通信占比越大,在 4K 序列长度时 AllReduce 通信开销为 18% 左右,在序列长度达到 32K 时,通信开销占到 40% 左右。
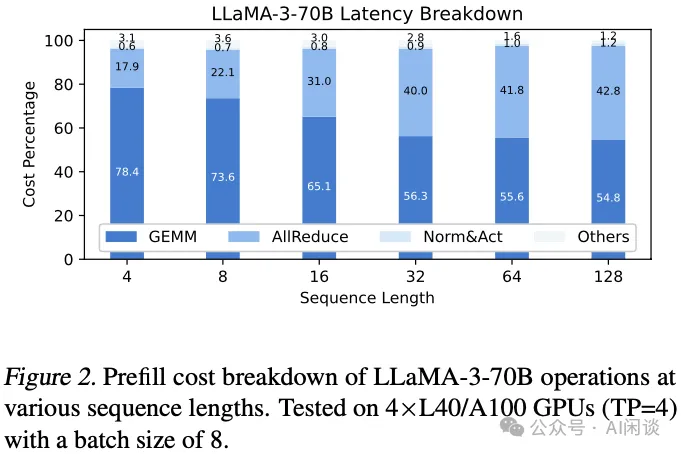
在 A100 GPU 上虽然有 NVLink+NVSwitch 互联,最大的通信开销依然可以达到 20%(PS:不过作者这里没有提供详细的数据)。
四、方案
4.1 量化挑战
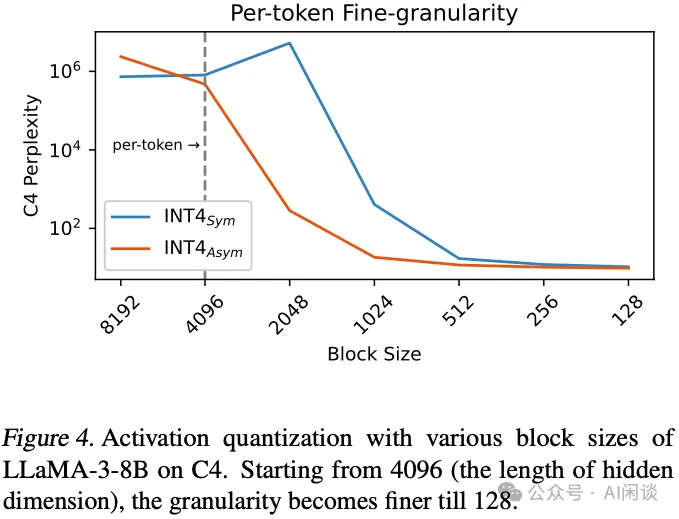
为了在准确性与时延之间达成最佳平衡,作者选择采用低比特量化技术。如下图 Figure 4 所示,可观察到,在大 Block 下进行逐 Token 量化会导致 C4 困惑度的性能急剧下降,非对称量化(Asym)相对较好,不过依然下降明显,因此细粒度量化是必要的。
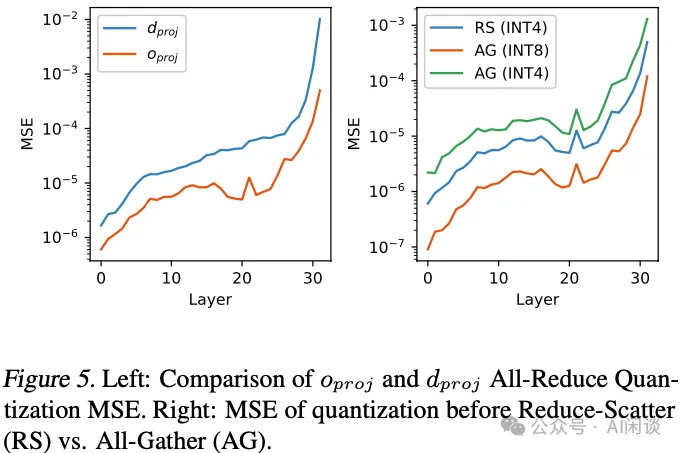
然而,作者发现在此情境下应用低比特激活量化并非易事。因此,作者计算了 LLaMA-3-8B 模型在激活量化前后的层级均方误差(MSE)来研究量化的敏感性。如下图 Figure 5 左图所示,下投影 dproj 的量化难度远高于输出投 影oproj。
此外,All-Reduce 中 Reduce-Scatter 和 All-Gather 操作对应的量化难度也各不相同,如下图 Figure 5 右图所示。这一现象符合预期,因为 Reduce-Scatter 前的量化仅引入舍入误差,而在 All-Gather 中,则同时包含舍入误差和累积误差。作为替代方案,可以在 All-Gather 操作前采用更高精度的量化以提升准确性。
4.2 通信算法
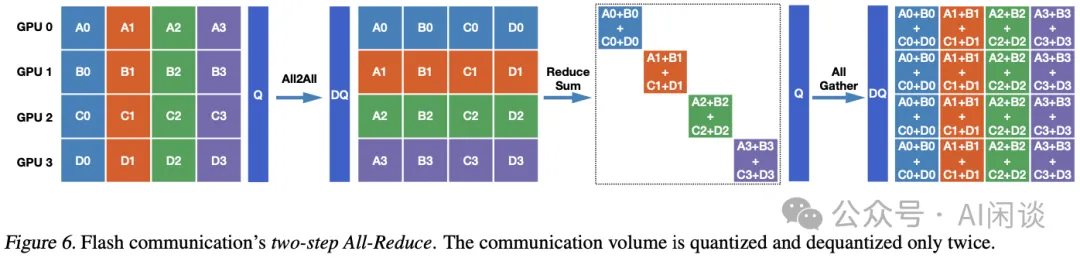
鉴于上述问题,作者设计了一种两步量化策略以替代传统的 Ring AllReduce 方法,称为 Flash AllReduce,如下图 Figure 6 所示。该策略与 TP 的结合如上图 Figure 3 所示。
如下图 Figure 6 展示了本文 Flash Communication 的通信原理:
首先,将每个 GPU 上的激活值按 Rank 的数量进行划分。
在激活值上进行细粒度量化后,执行 All2All 通信(与我们猜测的 TRT-LLM 的 MultiShot 实现类似),使得每个设备接收其规约所需的计算负载。当然,接收后也需要反量化操作。
在设备内完成 Reduce,不涉及通信操作。
对得到的结果再次进行量化以加速传输。然后进行 AllGather 以汇总所有结果,并在每个设备上进行反量化以恢复浮点数值。
具体的算法过程也可以参考如下图 Algorithm 1:

4.3 Kernel 设计
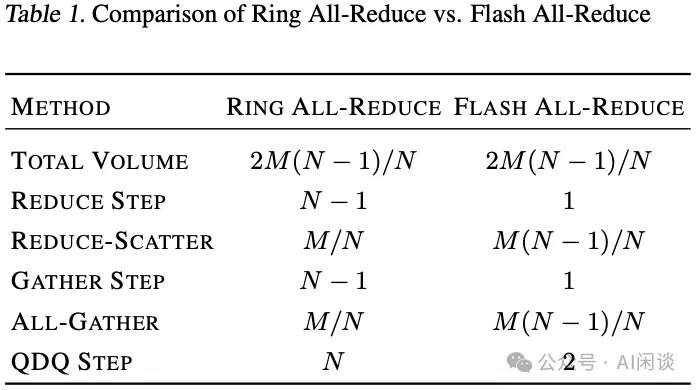
为了提升效率,作者开发了一个融合的 Flash AllReduce Kernel,以囊括上述所有集合通信操作及量化操作。如下图 Table 1 所示,相比 Ring AllReduce 操作,Flash AllReduce 将量化-反量化步骤从 N 次减少到 2 次,Reduce-Gather 步骤从 N-1 次缩减到 1 次。尽管总体数据个数保持不变,但每一份数据均被量化到较低位数,从而大幅减少了传输的数据大小。
快速细粒度量化:每个节点的总通信量(个数) M 被划分为 T 个 Chunk 进行传输。给定 Chunk 大小 C,如下图 Figure 7 展示了 GPU 线程如何并行组织以处理 Chunk 信息。一个 Chunk 被分割成 N 个 Block,每个 Block 对应 32 个 Warp,其中每个 Warp 由 32 个 Thread 组成,每个 Thread 可处理 8 个 FP16 元素。以采用 128 组大小的非对称量化为例,使用 16 个线程对每组 128 个元素进行量化。具体而言,利用 CUDA API 函数 __shfl_xor_sync 通过迭代交换这些 Warp Thread 间的信息,高效实现 Max/Min 归约。
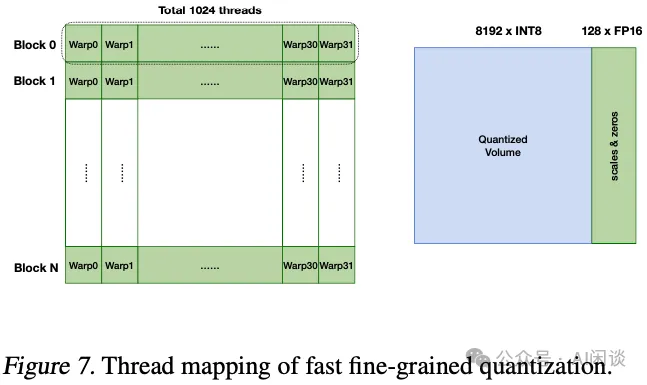
快速通信。不再使用 All2All 原语,而是利用 CUDA Runtime API 中的 GPU Peer Direct Memory 访问来传输量化后的数据量,在此过程中,能够直接从不同 Rank 获取数据,显著提升通信速度。
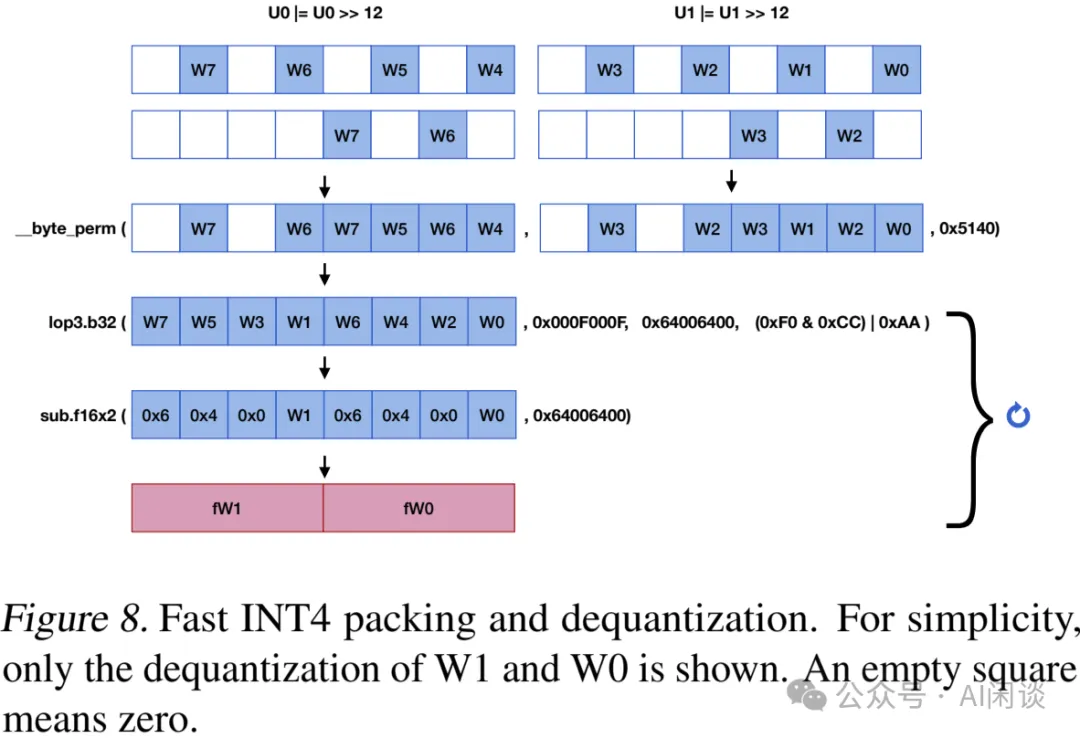
快速反量化。一旦接收到量化后的数据,需要将其反量化为 FP16 以进行 Reduce Sum。由于单纯的 INT4 到 FP16 转换会产生开销,作者采用了 [2211.10017] Who Says Elephants Can’t Run: Bringing Large Scale MoE Models into Cloud Scale Production [3] 中的反量化布局。为了在线协调其顺序,作者还采用了来自 LMDeploy 的快速 INT4 打包,如下图 Figure 8 所示:
给定两个 32 位无符号整数 U0 和 U1,它们分别持有 4 个 INT4 量化的激活值(每个存储在 8 位中的低 4 位)用于传输。
首先执行右移 12 位操作,然后对其自身进行按位或运算。
随后,使用 CUDA Math API __byte_perm 从这两个整数中选择目标位。通过这种方式,可以方便的按顺序打包 8 个 4 位整数进行反量化。
接下来,应用 lop3.b32 对打包变量执行逻辑操作(0xF0 & 0xCC)| 0xAA,应用掩码 0x000F000F 和 0x64006400,然后减去 0x64006400,这有效地表示了 FP16 中的 W1 和 W0。
通过改变剩余 INT4 整数的掩码,可以迭代进行反量化。
INT6 量化:鉴于在 All-Gather 之前进行低比特量化会导致更大的损失,这里作者选择采用 INT8 位宽,同时保持 ReduceSum 的 INT4 位宽,从而有效构建了一个 INT6 解决方案。INT6 配置在性能与通信效率之间达到了很好的平衡。
五、实验 & 结果
5.1 实验配置
实验在前述的 L40 和 A100 GPU 进行,对应的输入 Token 为 1024,输出为 64,基线为 FP16 通信。
5.2 精度对比
5.2.1 FP16 Weight 实验
如下图所示,作者针对 LLaMA-2 和 LLaMA-3 系列模型使用 FP16 Weight 进行了评估,可以看出,大部分情况下 Asym INT8 的损失都很小,基本无损(红框);Asym INT6(INT8 + IINT4)在 LLaMA-2 损失较小,在 LLaMA-3 损失稍微有点大;而 LLaMA-3 的 INT4 方案损失比较大,这也与 [2411.04330] Scaling Laws for Precision [4] 的结论相符,LLaMA-3 用了更多训练数据,相应也更难量化):
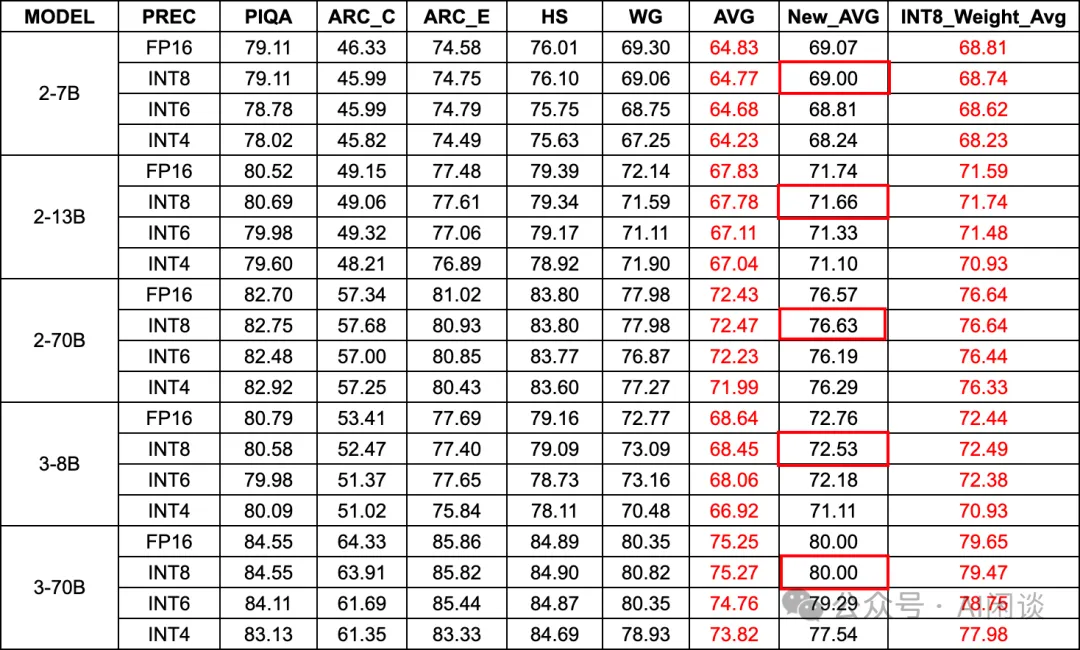
PS:需要说明的是,上述中我们没有使用论文表格是因为论文中出现了严重错误,上述表格中:
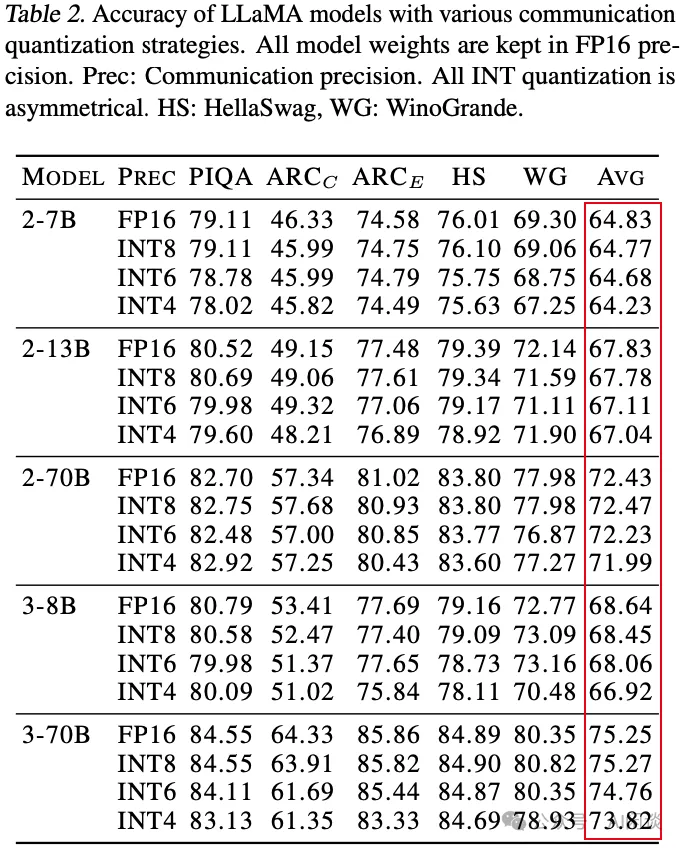
AVG 列:作者论文中计算的均值,如下图 Table 2 所示,此结果计算有误。
New_AVG 列:我们自己根据表格中相关数据计算的均值。
INT8_Weight_AVG:来自下述 Table 3 中对应 INT8 Weight 推理的均值。可以看出 INT8 Weight 的均值也和我们计算的 FP16 Weight 的结果均值接近,符合预期。
5.2.2 INT8 Weight 实验
如下图 Table 3 所示,作者同样针对 LLaMA-2 和 LLaMA-3 系列模型使用 INT8 Weight 进行了评估,和上述 FP16 Weight 结论基本类似:
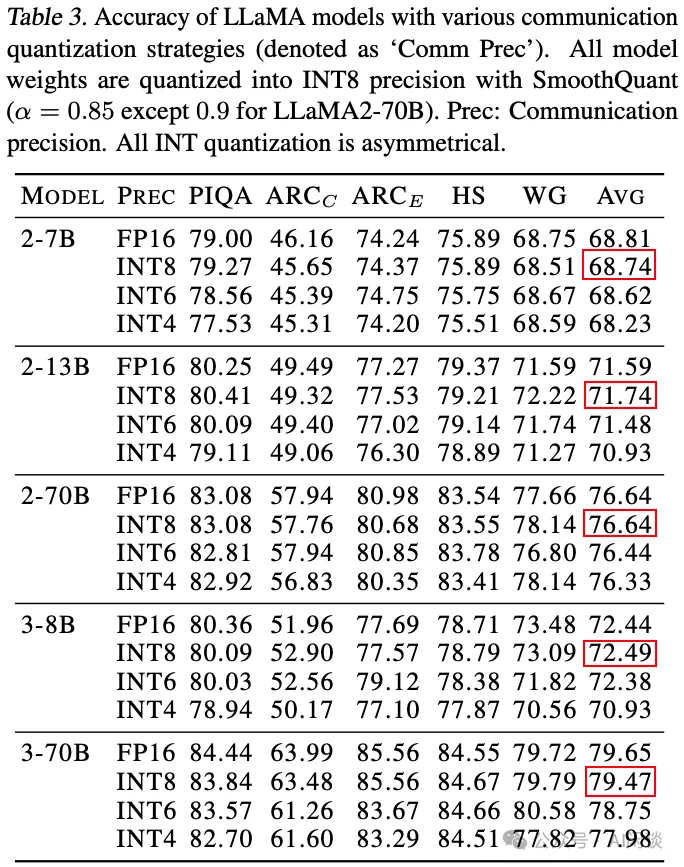
5.3 Flash AllReduce vs Ring AllReduce
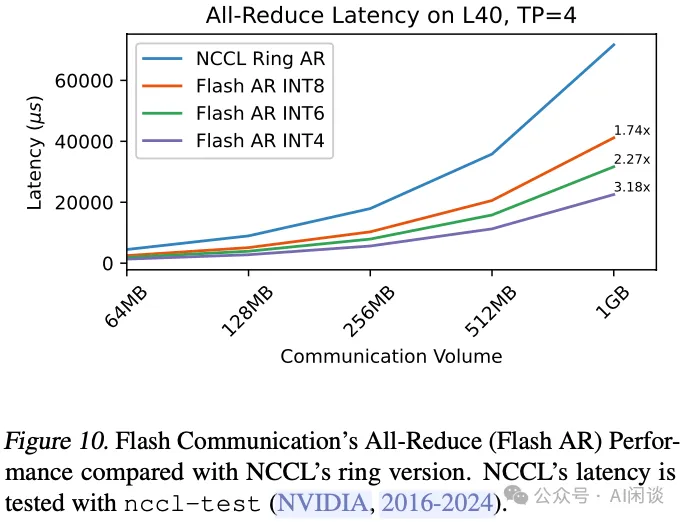
在集成了一系列优化技术后,Flash AllReduce 的速度显著由于 Ring AllReduce。如下图 Figure 10 所示,作者展示了通信量在 64MB – 1GB 时的通信时延。可以看出,其 INT4 版本最高可以实现 3.18x 的 Kernel 加速,而 INT6 在速度和精度之间取得了不错的平衡(PS:需要注意的是,实际推理过程中通信量可能没有这么大)。
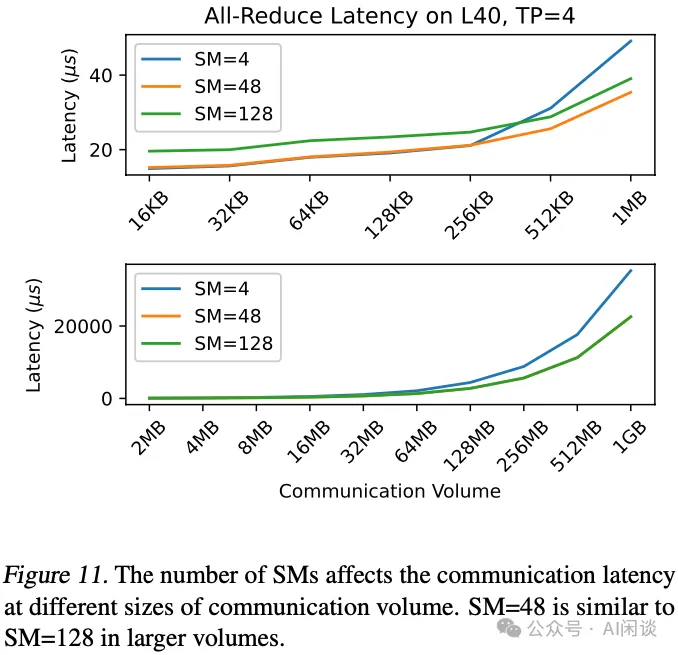
如下图 Figure 11 所示,作者也展示了不同 SM 数量对通信效率的影响。在通信量较小时,较少的 SM 数量更为有利,因为这可以减少 Kernel 启动和 Block 间同步的开销。然而,随着通信量增大,计算需求增加,也很有必要使用更多 SM。配置 48 个 SM 可以在通信与计算之间达到了更佳的平衡。
5.4 时延和吞吐
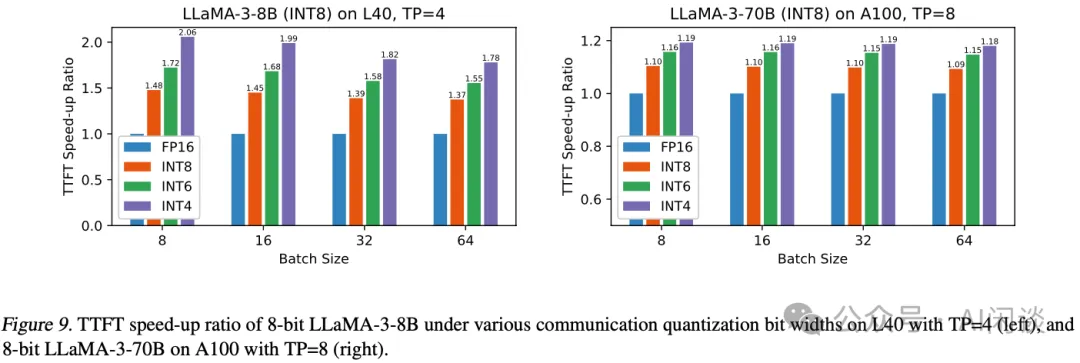
如下图 Figure 9 所示,作者也基于 LLaMA-3-8B 和 LLaMA-3-70B 模型在 L40 和 A100 上测量了 TTFT 的时延,可以看出,在 L40 上 TP=4 最多可以获得 2.06x 的加速(对应的 INT4,INT8 只有 1.42x);而在 A100 上 TP=8 最多可以获得 1.19x 加速(对应的 INT4,INT8 只有 1.1x)
如下图 Figure 13 所示,在 L40 上 TP=2 的加速会更小一些:
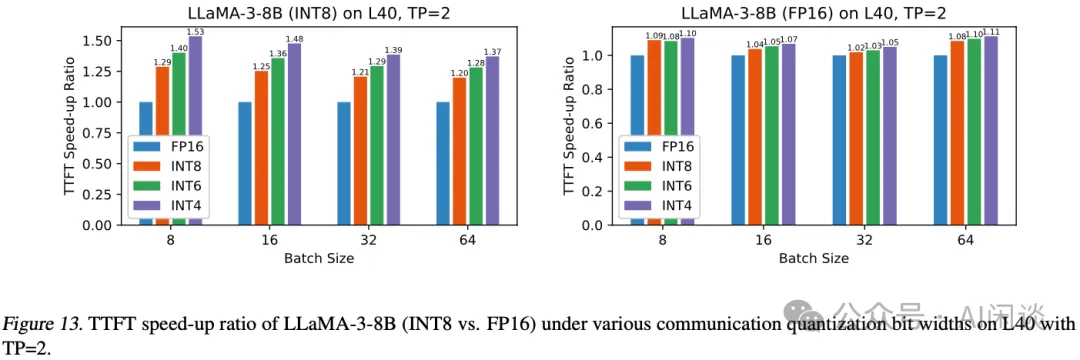
PS:此外,LLM Inference 在 Prefill 阶段的 AllReduce 通信量比较大,而在 Decoding 阶段的 AllReduce 通信量比较小,作者并没有进行相关对比实验。
















暂无评论内容