人类是社会性动物,但如何让3D自主角色拥有类似的社交智能—能够感知、理解并与人类互动仍然是一个关键且尚未完全解决的问题。为了解决这个问题,商汤科技推出了首个端到端的“社交视觉-语言-行动”(VLA)建模框架SOLAMI,专为与3D自主角色进行沉浸式互动而设计,让用户能够在沉浸式 VR 环境中通过语音和肢体语言与 3D 自主角色进行交互。
SOLAMI通过三个核心方面构建3D自主角色:提出统一的社交VLA框架,根据用户多模态输入生成语音和动作响应,驱动角色进行社交互动;创建名为SynMSI的合成多模态社交数据集,通过自动化流程解决数据稀缺问题;开发沉浸式VR界面,让用户能够与不同架构驱动的角色进行更加真实的互动。
01 技术原理
—
SOLAMI 通过使用端到端的社交视觉-语言-动作模型,让用户能够在沉浸式 VR 环境中通过语音和肢体语言与 3D 自主角色进行交互,该模型在合成的多模态数据集 SynMSI 上进行训练。
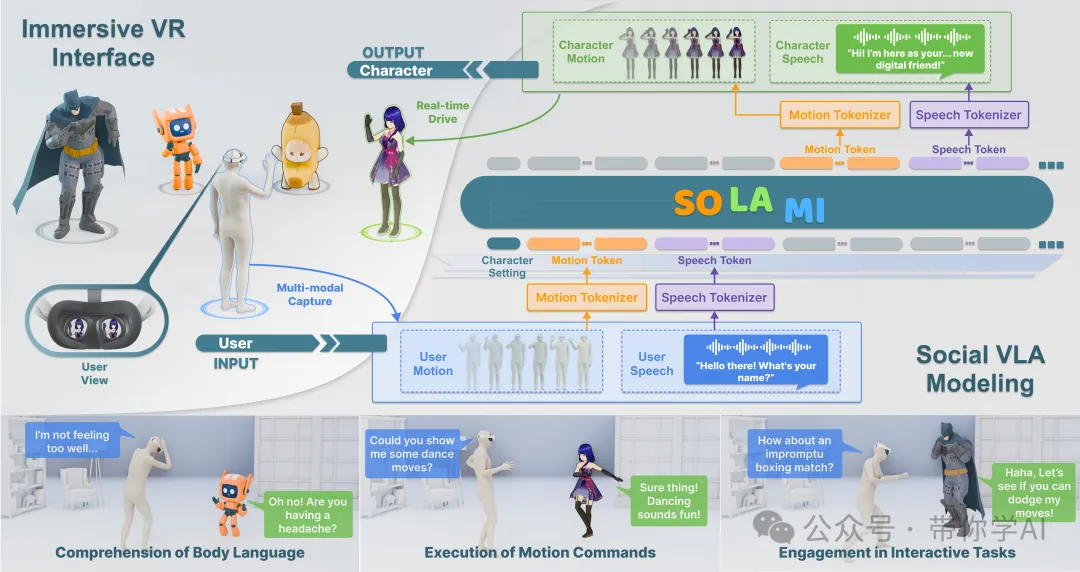
在预训练阶段,使用动作文本和语音文本相关任务来训练模型,以使语音和动作模式与语言保持一致。在指令调整阶段,使用社交多模态多轮交互数据来训练模型,使其能够生成与角色设置和主题上下文一致的多模态响应。

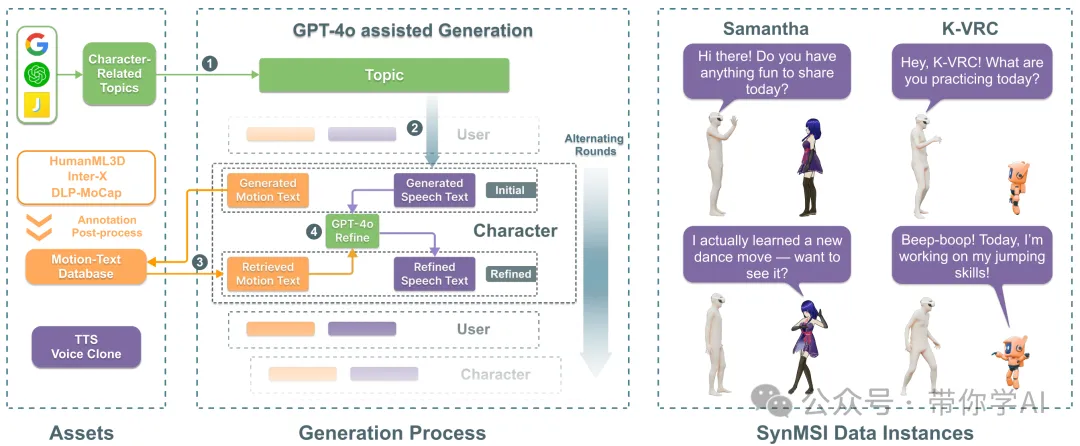
合成流程步骤:基于大量与角色相关的主题和最先进的 LLM,为多模态对话生成文本脚本。使用大规模动作数据库,检索最合适的动作并相应地细化语音脚本。最后,使用 TTS 语音克隆来生成特定角色的语音。这种方法能够仅使用现有的动作数据集来创建各种角色的多模态交互数据。
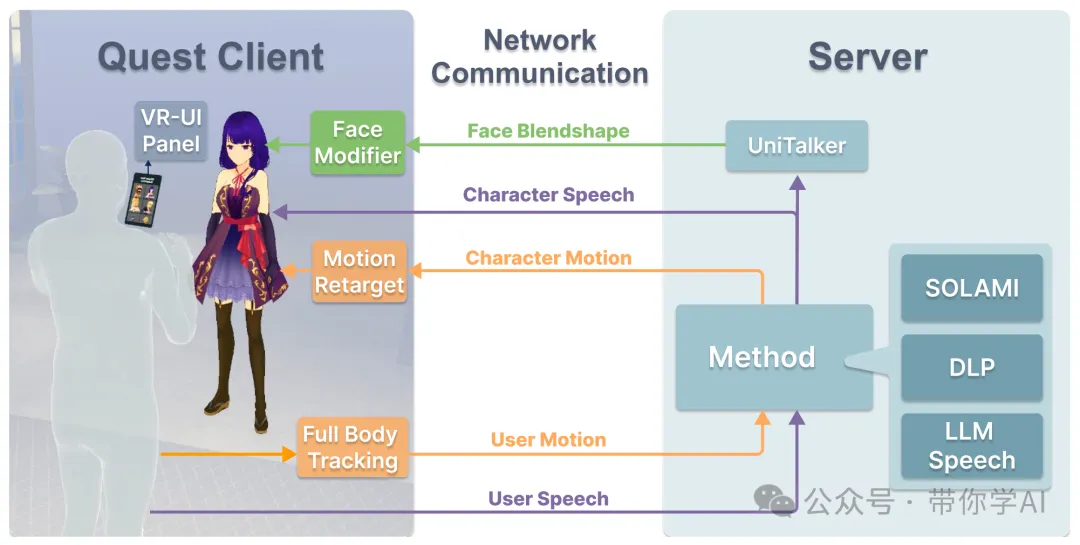
VR 项目由 Quest 3 客户端和服务器组成。Quest 客户端捕获用户的身体动作和语音并将其传输到服务器。然后,服务器根据所选方法生成角色的语音、身体动作和面部混合形状参数,最后将响应发送回 Quest 客户端以驱动角色。
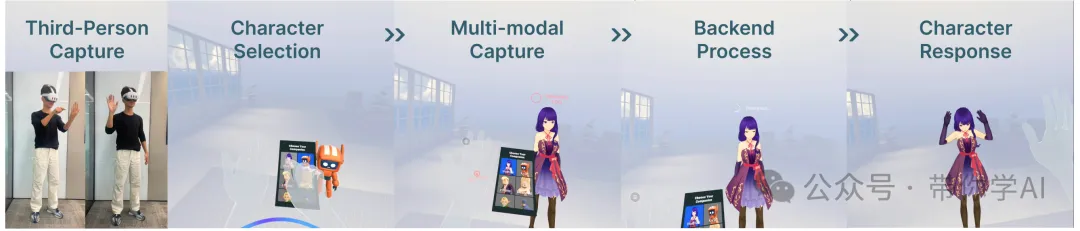
SOLAMI 就像一个特别聪明的虚拟助手,能听懂你说的话、观察你的动作,并作出符合情境的反应,让互动更加真实流畅!
但SOLAMI 也面临输入模态扩展、数据收集、跨角色动作适配、长短期交互设计以及高效学习方法等挑战,需要通过改进数据获取、记忆机制和少样本学习等方式提升模型的交互能力和泛化性。














暂无评论内容