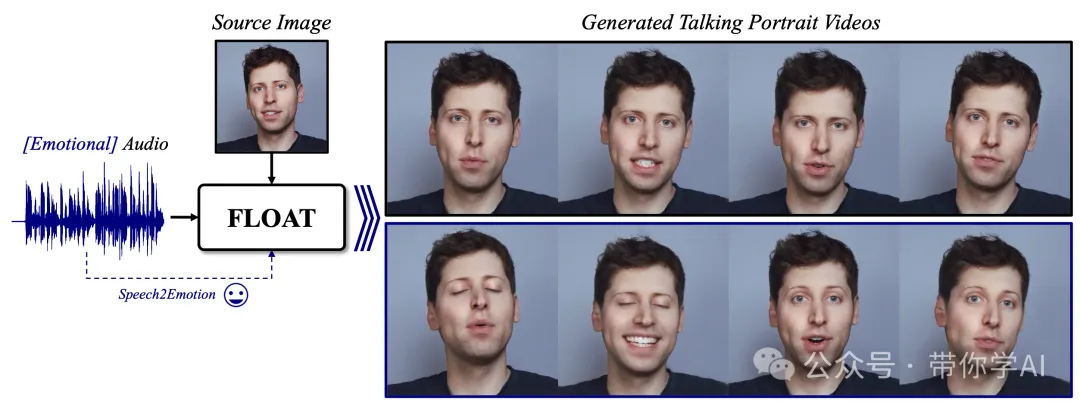
随着扩散模型技术的飞速发展,人像图像动画已经取得了惊人的效果。然而,它在生成视频时仍面临一些难题,比如视频的时间一致性(让画面流畅衔接)和快速生成(由于需要多次迭代导致速度慢)。DeepBrain AI提出了一种名为FLOAT 的新方法,专注于基于语音驱动的人像视频生成。FLOAT 采用了流匹配生成模型(flow matching generative model)。
FLOAT 在视觉效果、动作真实性以及生成效率方面,全面超越了当前最先进的语音驱动人像视频生成方法。总结来说,FLOAT 是一种让视频生成更快、更流畅、更生动的强大工具。使得视频更加自然,还支持通过语音驱动增强表情,让生成的人物动作更富有情感和表现力。
技术原理
—
语音驱动的人像视频生成,简单来说,就是用一张静态的人像图片和一段语音,生成一个“会说话”的人像视频。而FLOAT 是一种全新的方法,它基于“运动潜在空间自动编码器”(motion latent auto-encoder),能够把输入的人像图片转换成包含人物特征和运动信息的“潜在表示”。
FLOAT 创新点是将生成过程从传统的像素层面转移到一个专门设计的“运动潜在空间”。这一改变可以更高效地设计视频中的流畅运动。此外,FLOAT引入了一个基于 Transformer 的矢量场预测器,并结合了一种简单但效果显著的逐帧条件控制机制。这不仅让视频更加自然,还支持通过语音驱动增强表情,让生成的人物动作更富有情感和表现力。
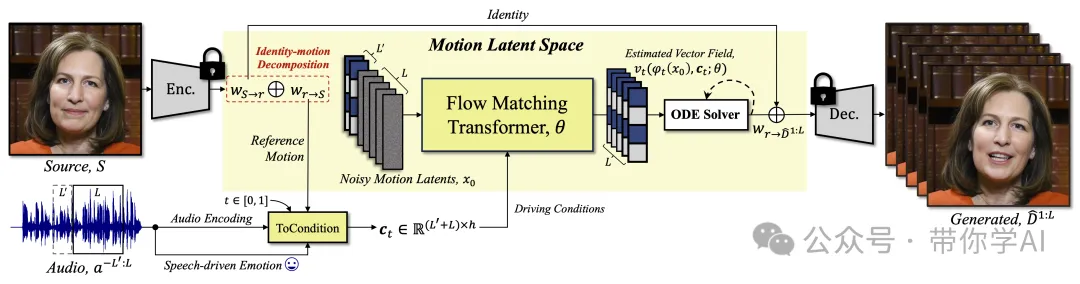
为了让生成的人像动作更自然、生动,FLOAT引入了语音驱动的情感标签(比如😀),让生成的人物不仅会说话,还能带上情绪!这使得生成的视频更像真实的人在表达情感,提升了整体的自然感和观赏体验。
因为 FLOAT 在训练时加入了语音驱动的情感标签,所以在生成视频时,可以灵活调整人像视频中的情感表现。具体来说,可以用一个简单的“单一情感标签”(比如快乐😀、生气😡)来替换系统预测的情感标签,甚至还能通过一种“无分类器的矢量场”进一步微调情感表现。这意味着,即使语音中的情感表达模糊或混杂,用户也可以手动调整生成的视频情感,让人物表现出更清晰、更精准的情绪。这种功能让用户对人像视频的情感表现拥有更多的控制权,使生成的结果更加符合需求!














暂无评论内容