图形用户界面(GUI)长期以来一直是人机交互的核心,一种直观且以视觉驱动的方式来访问和与数字系统交互。本文提出了一份全面的LLM驱动的GUI Agents(智能体)的综述,探讨了它们的历史演变、核心组件和先进技术。
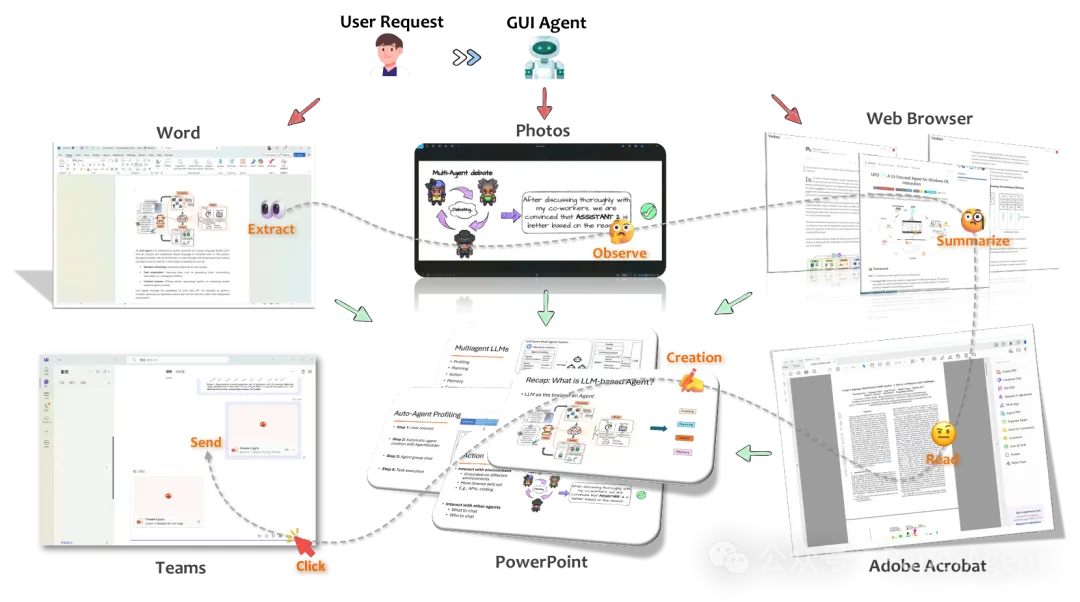
LLM驱动的GUI智能体的高级概念图示。智能体接收用户的自然语言请求,并在多个应用程序中无缝地协调动作。它从Word文档中提取信息,在Photos中观察内容,在浏览器中总结网页,在Adobe Acrobat中读取PDF,并在PowerPoint中创建幻灯片,然后通过Teams发送它们。
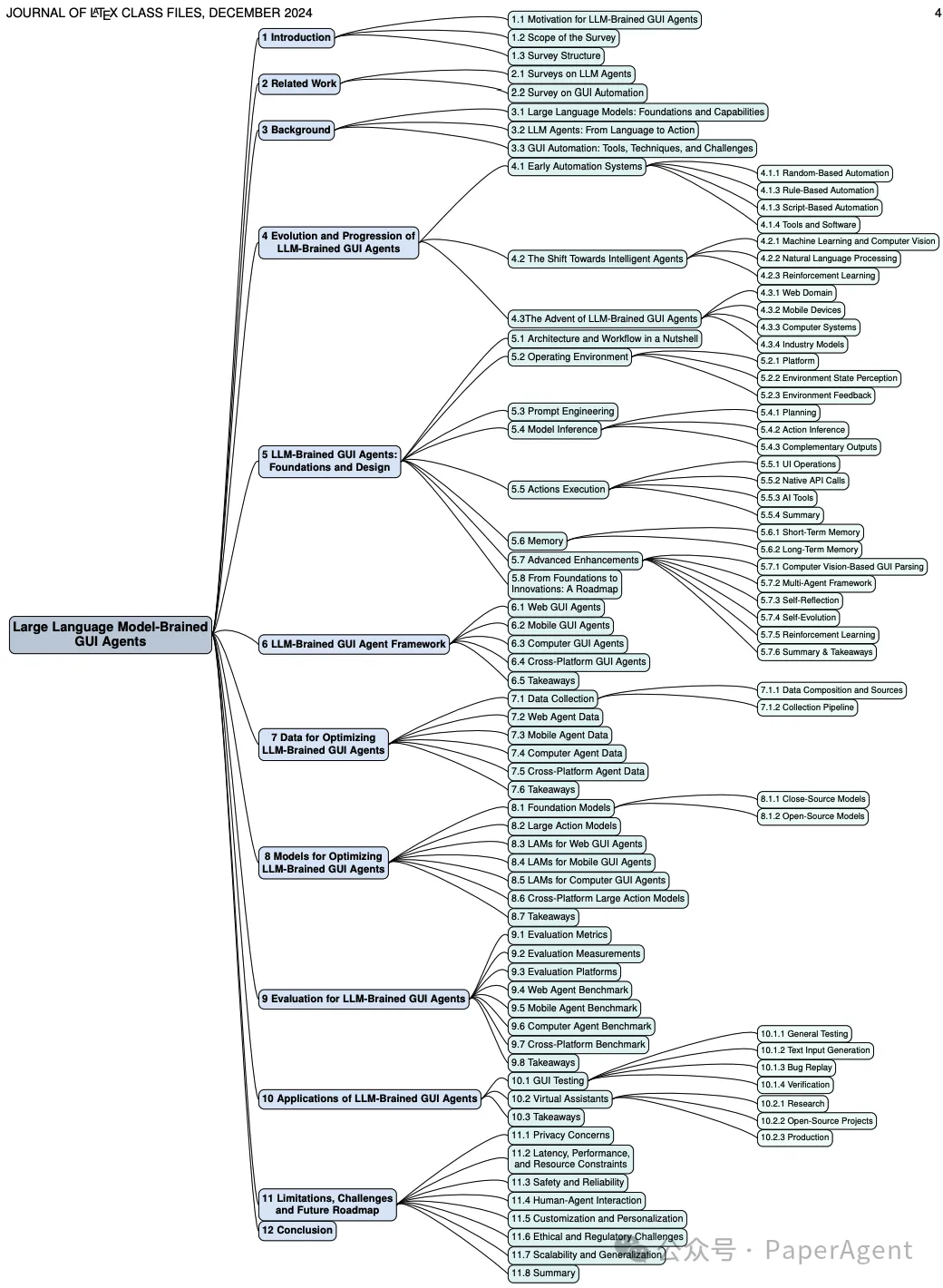
关于LLM驱动的GUI智能体的研究综述结构
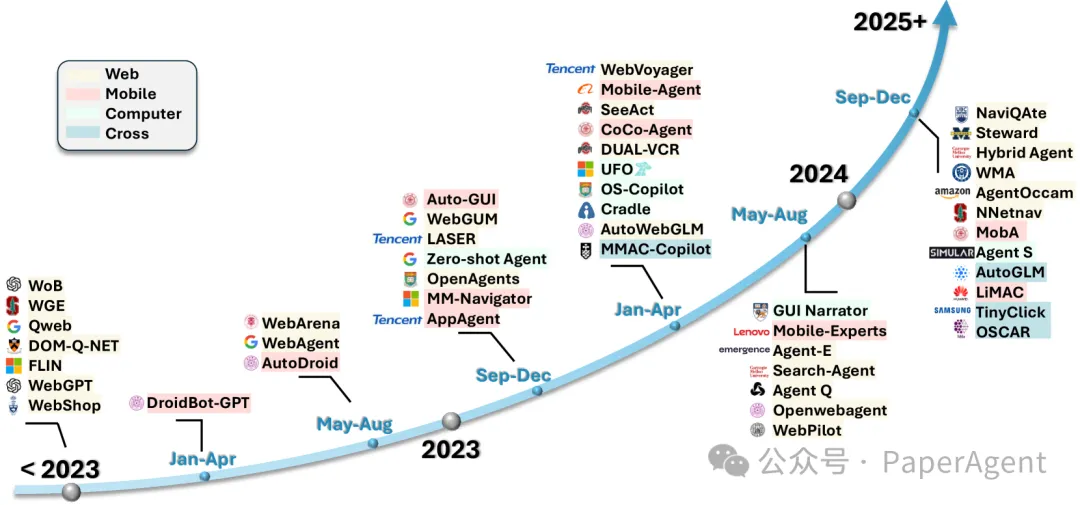
GUI Agents发展与演化
详细讨论了大型语言模型(LLM)驱动的图形用户界面(GUI)智能体的发展和进步。
早期自动化系统:
随机基础自动化:使用随机动作序列进行GUI测试,这种方法在发现潜在问题时有效,但效率低下。
规则基础自动化:依赖预定义规则和逻辑来自动化任务,适用于预定义工作流程,但缺乏处理动态环境的灵活性。
脚本基础自动化:使用脚本语言(如Python、Java)控制GUI元素,这些方法对于静态界面有效,但在动态内容面前显得力不从心。
向智能体的转变:
集成了机器学习技术,使得GUI智能体能够更加适应和智能。
机器学习和计算机视觉:使用深度学习技术来识别屏幕和UI组件,使测试更加高效和直观。
自然语言处理:允许用户通过自然语言命令控制GUI,但这些方法通常限于简单命令,难以处理长期任务。
强化学习:在Web和移动平台上训练基于LLM的智能体,尽管这些方法比早期的规则基础系统更具适应性,但它们仍然难以泛化到多样化的未知任务。
LLM-Brained GUI智能体的出现:
LLM的出现,尤其是多模态模型,通过自然语言交互重新定义了GUI自动化的可能性。
Web领域:LLM在Web领域的初步应用,建立了基准数据集和环境。
移动设备:LLM与移动设备集成,开始于AutoDroid等项目,这些项目结合了LLM与领域特定知识,用于智能手机自动化。
计算机系统:例如UFO等系统,利用GPT-4等模型的视觉能力,在Windows环境中执行用户命令。
行业模型:行业模型如Claude 3.5 Sonnet的“计算机使用”功能,标志着LLM-Brained GUI智能体在行业中的认可和投资。
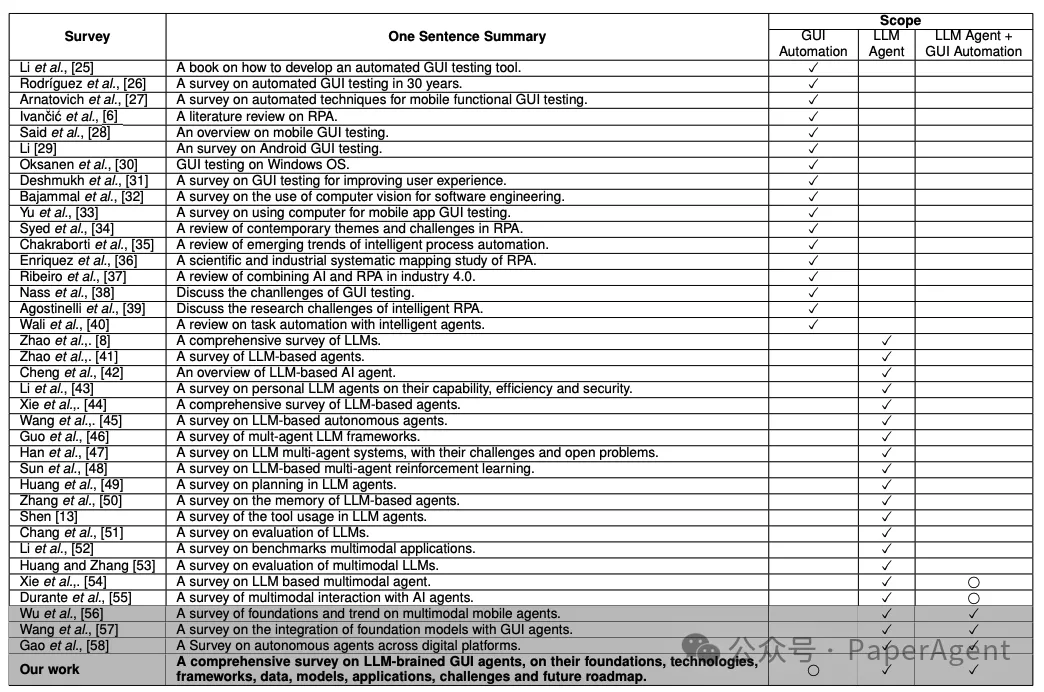
关于GUI自动化和LLM智能体的代表性调查和书籍的总结。一个✓符号表示出版物明确涉及给定领域,而一个⃝符号表示出版物不专注于该领域但提供了相关见解。同时涵盖GUI自动化和LLM智能体的出版物被突出显示以强调。
GUI Agents架构与设计原则
详细介绍了大型语言模型(LLM)驱动的图形用户界面(GUI)智能体的基础架构和设计原则。
架构和工作流程概述:
LLM-Brained GUI智能体的架构包括多个组件,它们共同工作以解释用户指令并执行基于自然语言的任务。
工作流程从用户请求开始,包括环境感知、提示工程、模型推理、动作执行和记忆利用,直至任务完成。
基本LLM驱动的GUI智能体的架构和工作流程概览
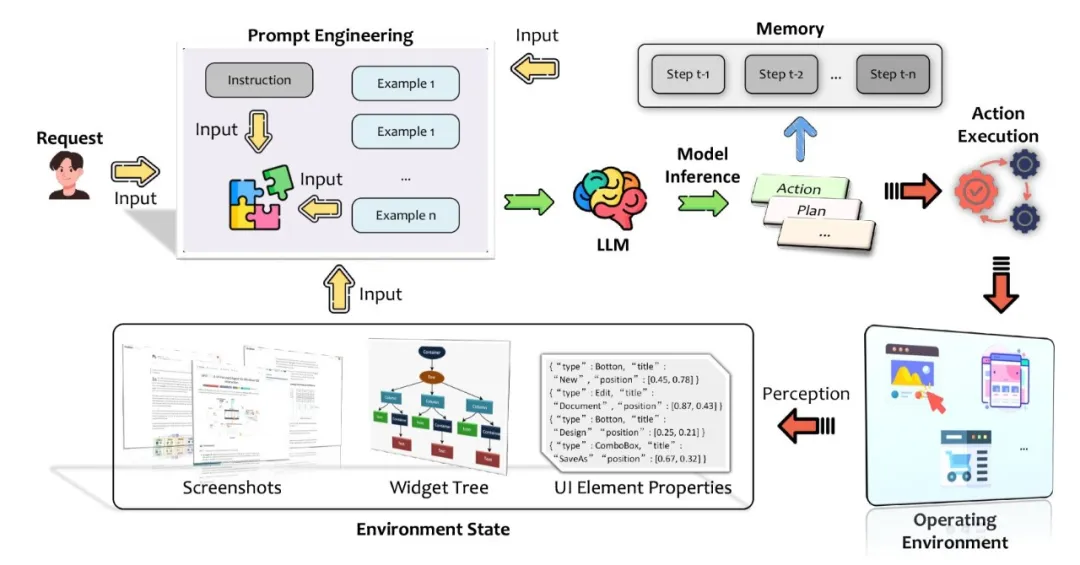
操作环境:
智能体在不同的平台(如移动设备、Web浏览器和桌面操作系统)上与GUI进行交互。
每个平台都有其独特的特点,智能体需要适应这些特点以有效地感知和解释GUI。
环境状态感知:
智能体通过截图、控件树和其他方法来感知环境状态,这对于做出决策至关重要。
环境状态感知包括获取屏幕截图、控件树、UI元素属性等,以构建对界面的完整表示。
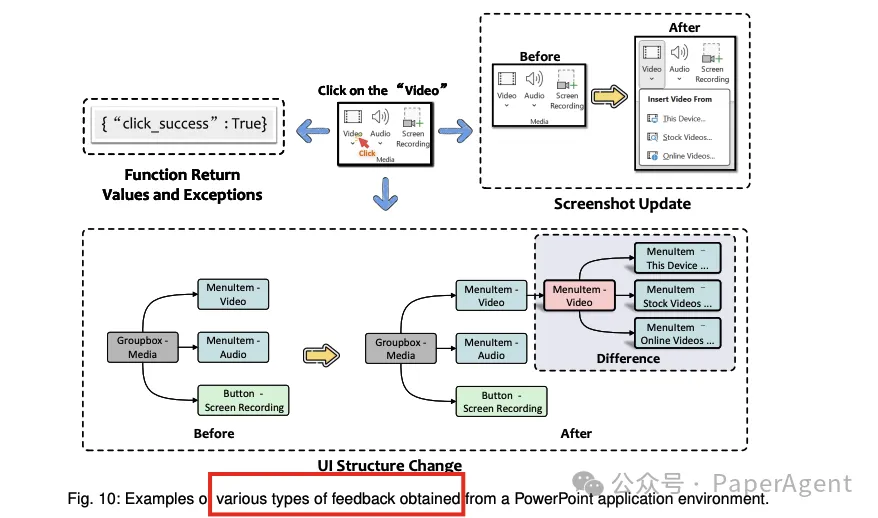
环境反馈:
智能体执行动作后,需要根据环境的反馈来评估动作的成功与否,并据此调整策略。
反馈可以是视觉变化、UI结构变化、函数返回值或异常。
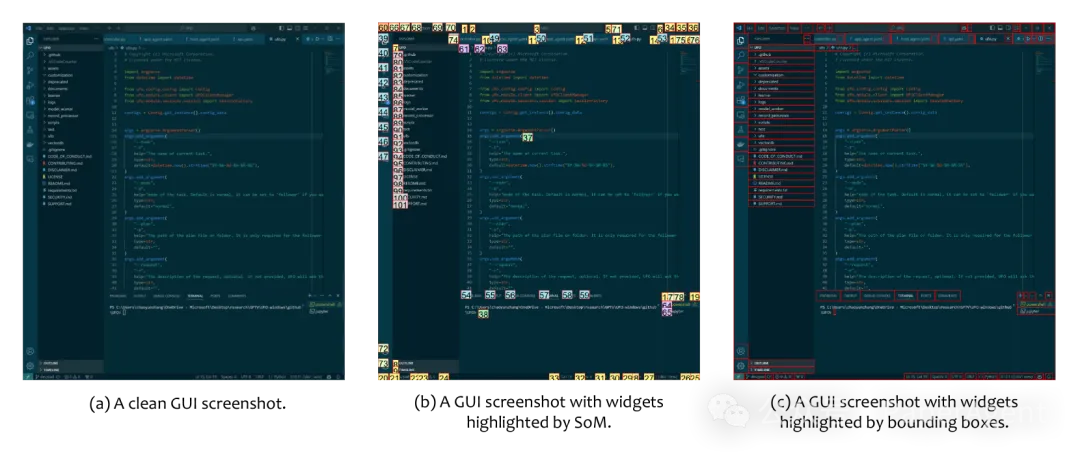
VS Code GUI截图的不同变体示例
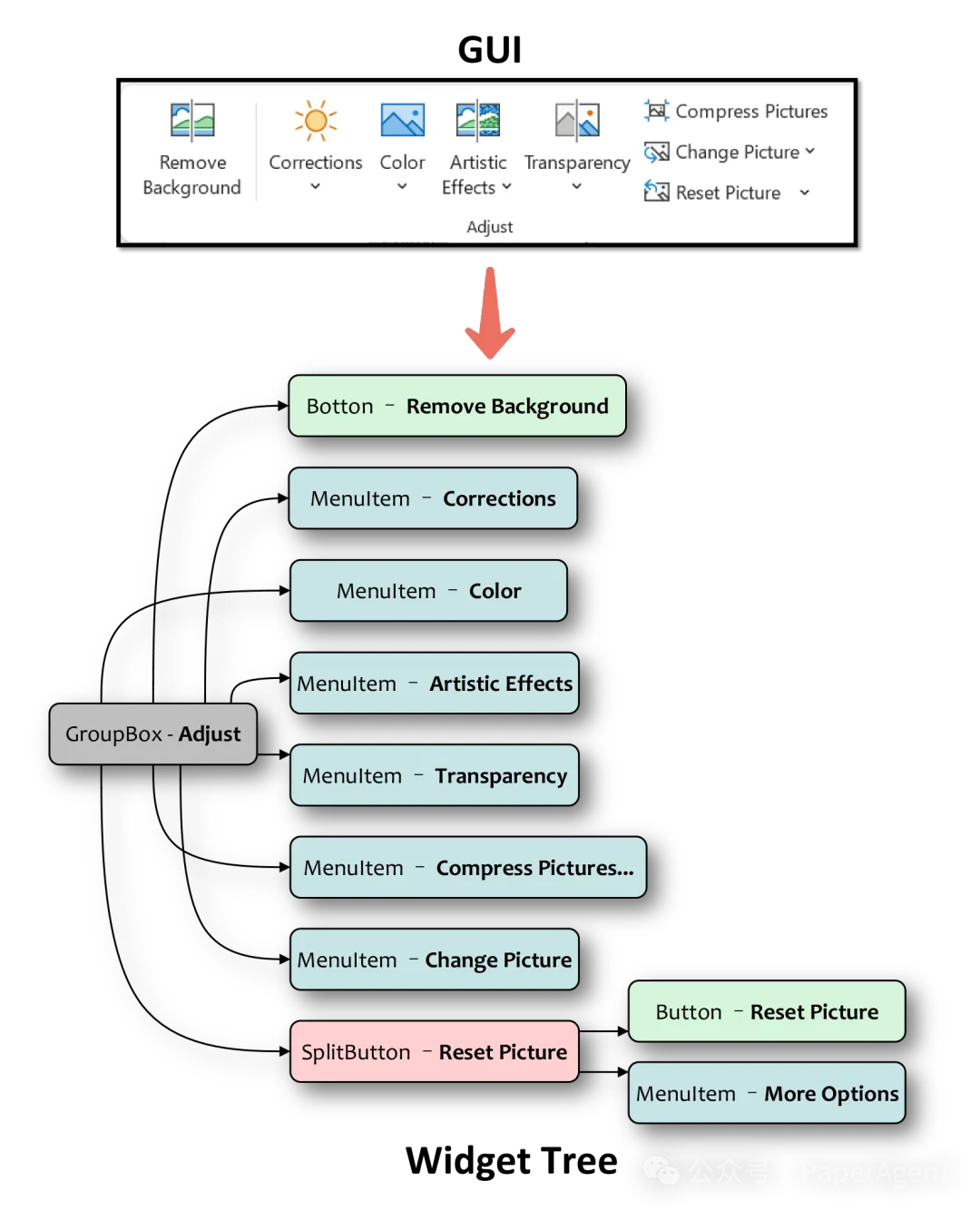
一个GUI及其控件树的示例
提示工程:
提示工程是构建详细提示的过程,它结合了用户指令、环境状态和动作文档,以指导LLM的推理。
有效的提示对于LLM理解和执行任务至关重要。
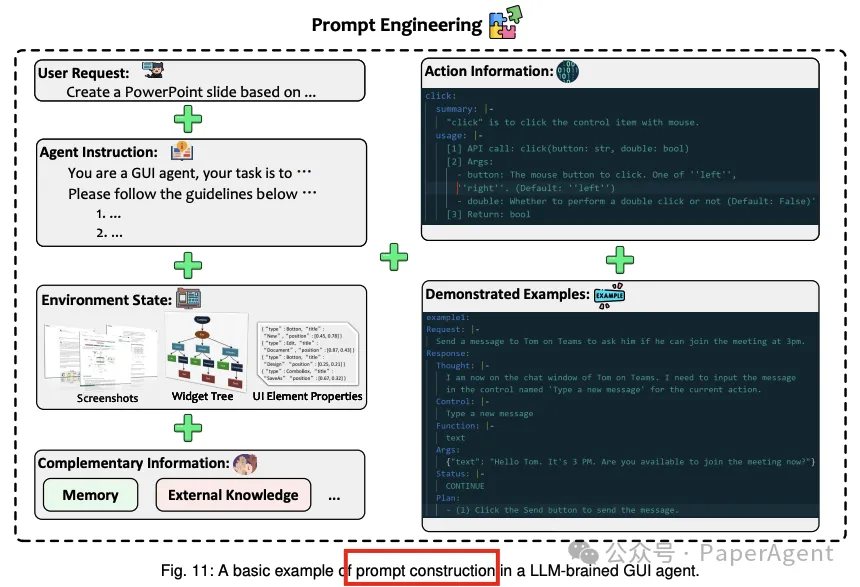
模型推理:
推理过程涉及规划和动作推理,LLM根据提示生成计划和具体动作。
推理输出包括计划、动作和补充输出,如推理过程和任务状态。
动作执行:
智能体根据LLM的推理结果执行动作,如鼠标点击、键盘输入或API调用。
动作执行是将LLM的文本输出转化为实际界面操作的过程。
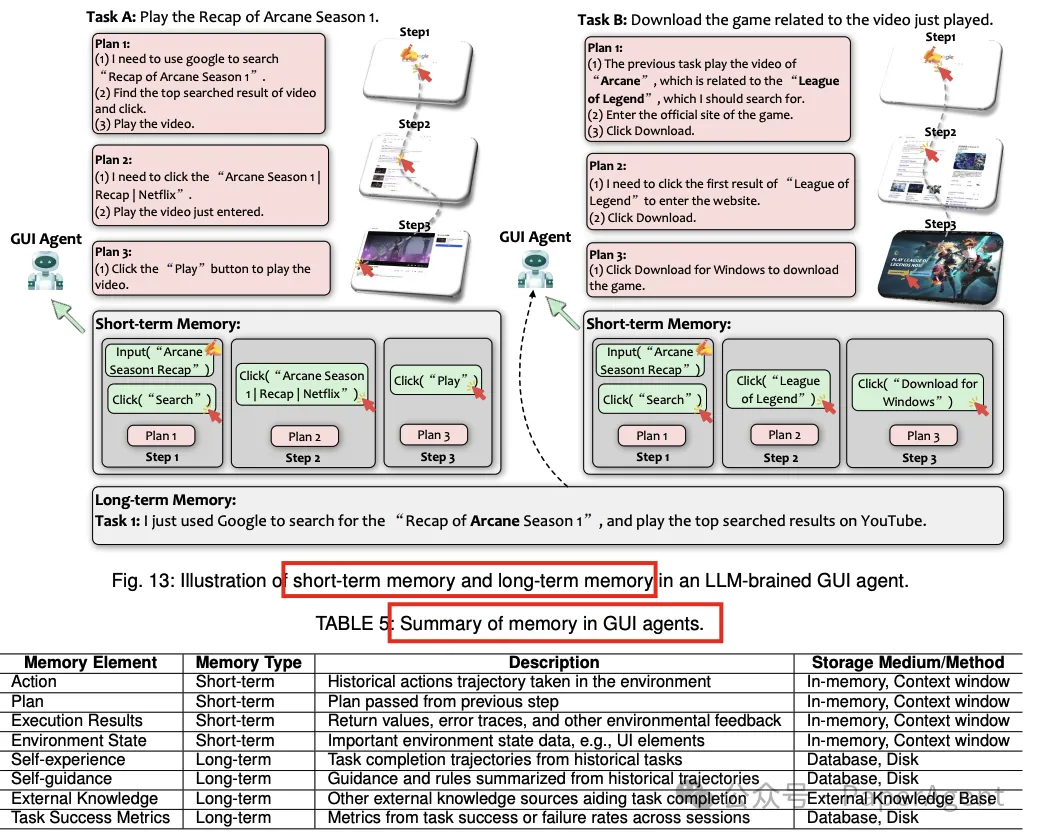
记忆:
智能体需要记忆以管理状态和历史信息,这对于多步骤任务的连贯性和决策至关重要。
记忆分为短期记忆和长期记忆,分别存储当前任务的上下文和跨任务的历史数据。
高级增强:
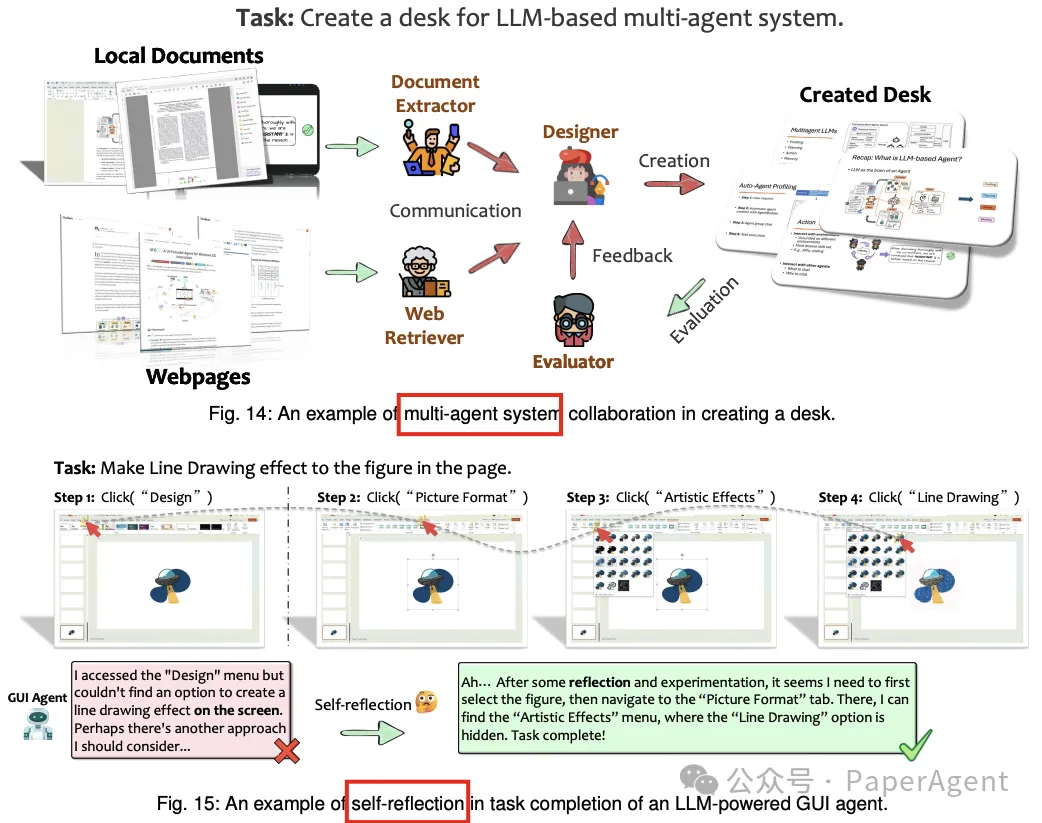
除了基础组件,还有一些高级技术可以显著提高智能体的推理和能力,如基于计算机视觉的GUI解析和多智能体框架。
大模型GUI Agents框架
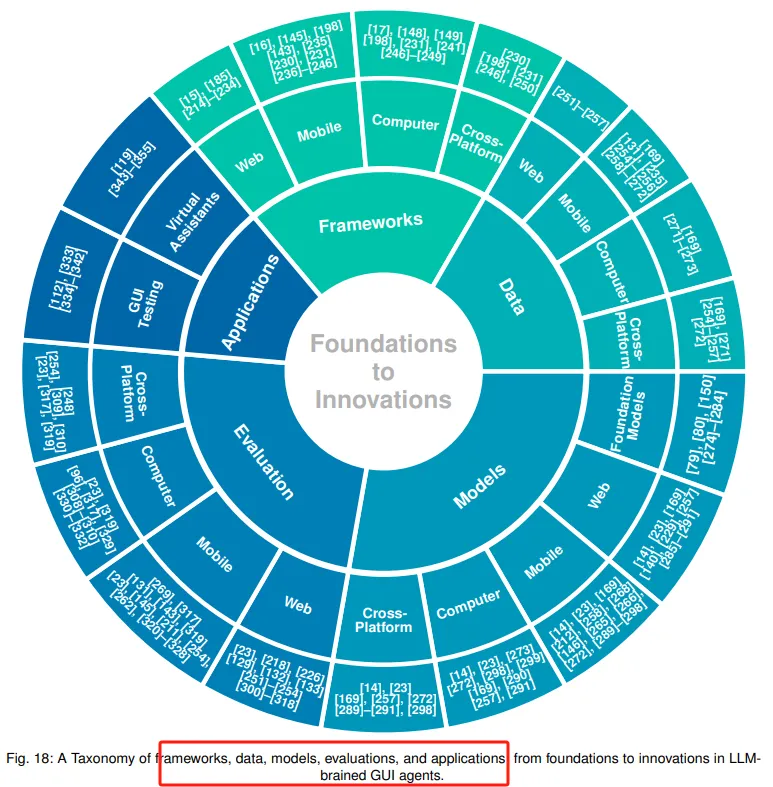
主要探讨了将大型语言模型(LLMs)集成到GUI自动化中的各种框架(frameworks)。这些框架使得智能体能够解释用户的自然语言请求,分析GUI屏幕及其元素,并在不同软件界面中自动执行动作。
Web GUI智能体(Web GUI智能体):
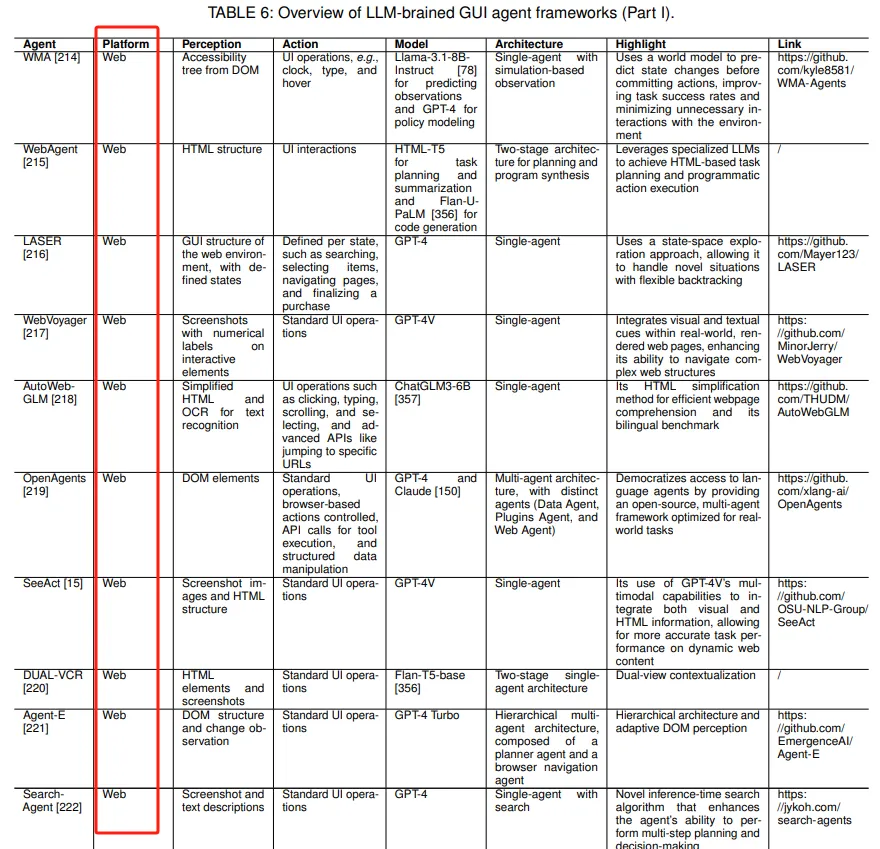
介绍了几个关键的Web GUI智能体框架,如WebAgent、WebVoyager和AutoWebGLM,它们利用多模态输入和预测建模来提高Web任务的执行效率和适应性。
移动GUI智能体(移动GUI智能体):
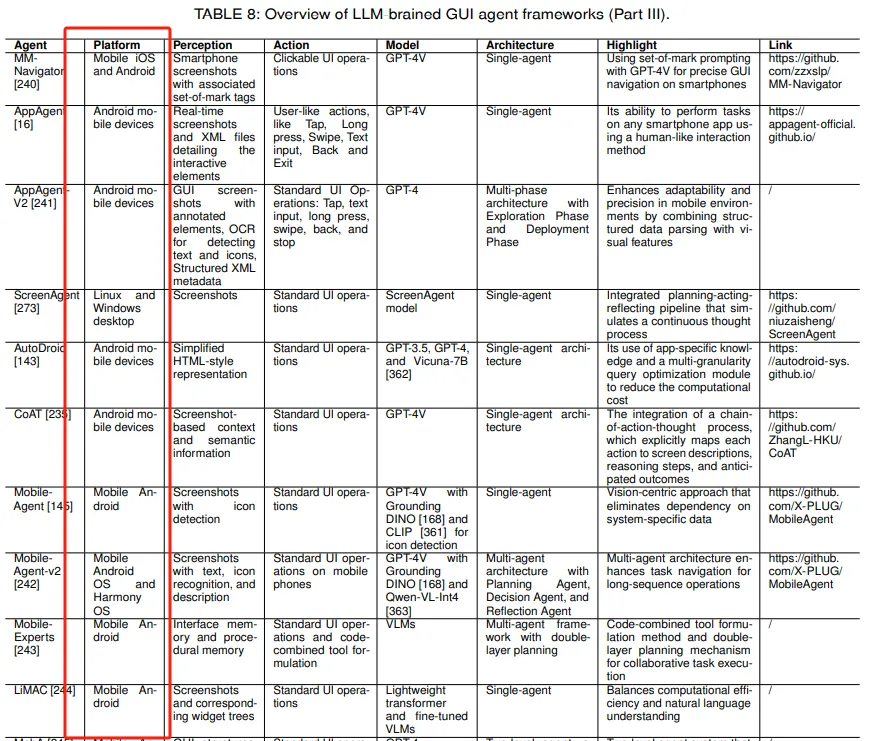
讨论了移动平台GUI智能体的进展,包括AppAgent和MobileAgent等框架,它们通过结合多模态能力和复杂的架构来处理移动环境中的独特挑战。
计算机GUI智能体(计算机GUI智能体):
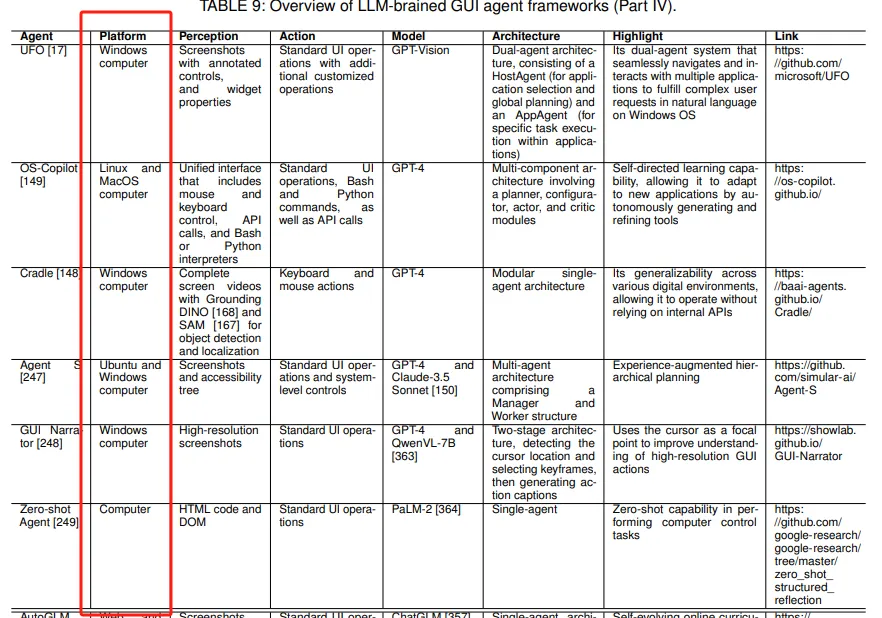
描述了计算机GUI智能体的发展,如UFO和OS-Copilot,它们提供跨多个应用程序的复杂任务执行能力。
LLM-Brained GUI智能体框架要点:
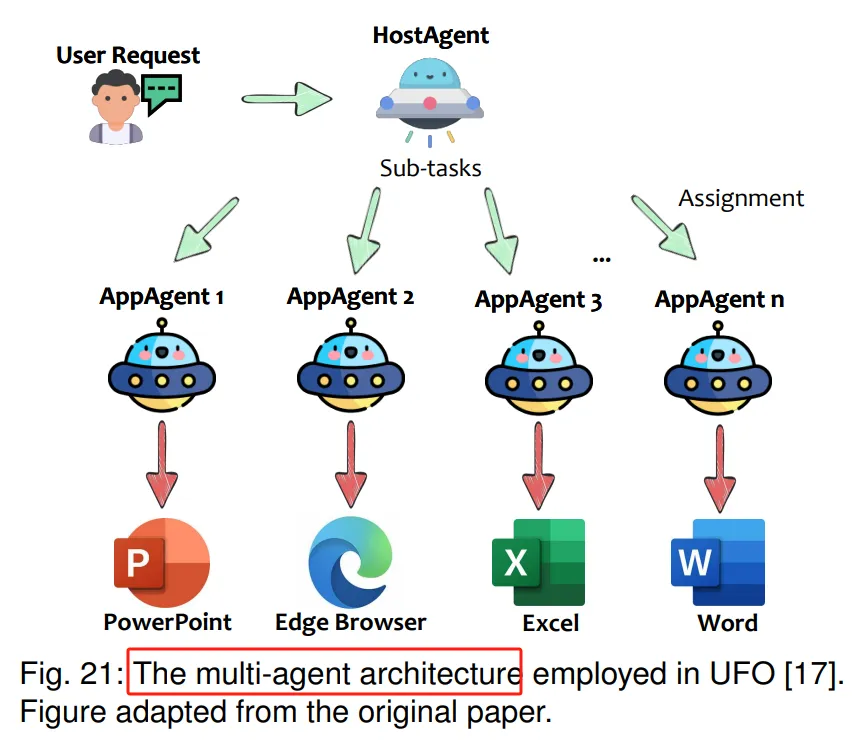
多智能体协同:多智能体系统通过分配不同角色给各个智能体,增强了任务效率和适应性,尤其是在处理复杂任务时。
多模态输入的优势:结合视觉输入(如屏幕截图)和文本输入可以提供更丰富的环境状态表示,帮助智能体做出更好的决策。
扩展动作集:智能体不仅限于UI操作,还包括API调用和AI驱动的动作,提高了交互水平和任务完成率。
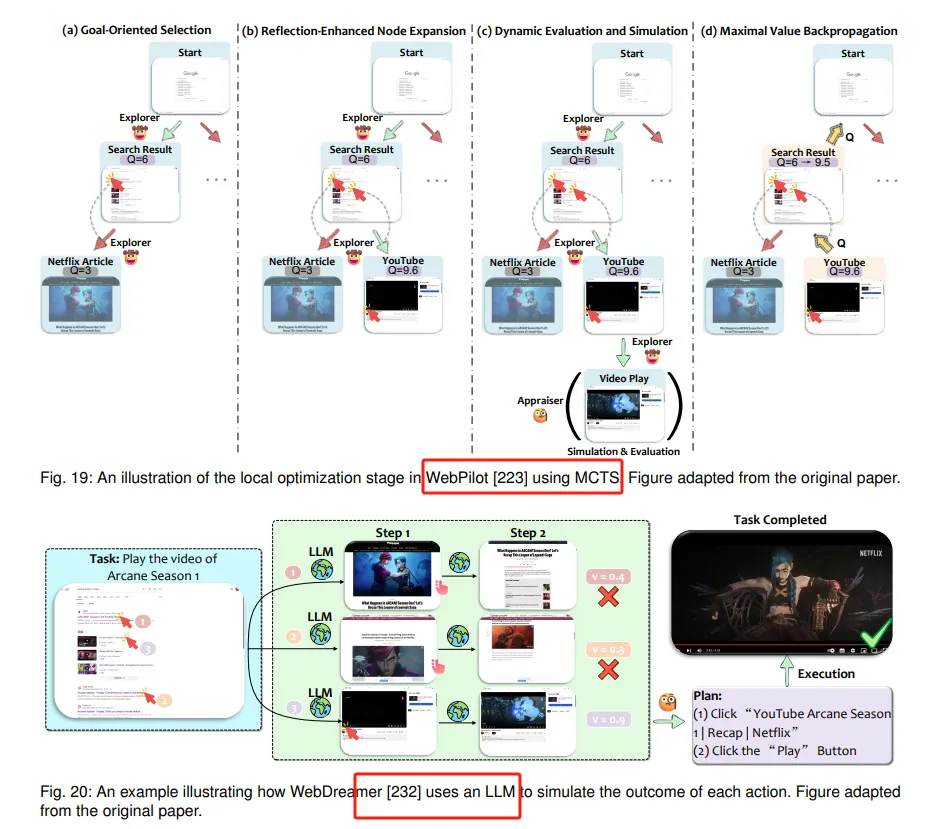
新兴决策技术:如世界模型和基于搜索的策略等新兴方法,帮助智能体在复杂环境中进行更有效的决策。
跨平台泛化:跨平台框架支持智能体在不同平台间进行泛化,朝着创建能够在多个生态系统中一致运行的解决方案迈进。














暂无评论内容