
01.
什么是 AI-native 应用?
在传统企业软件领域,AI 往往作为一种补充性能力被整合到现有系统中。但随着 ChatGPT 在 2022 年底的惊艳亮相,一种全新的软件形态开始崭露头角,即AI 原生应用(AI-native Applications)正在从基础设施到应用层全方位重构软件产业的价值链条。
这种创新不仅体现在技术架构上,更重要的是开创了全新的产品范式和商业模式。
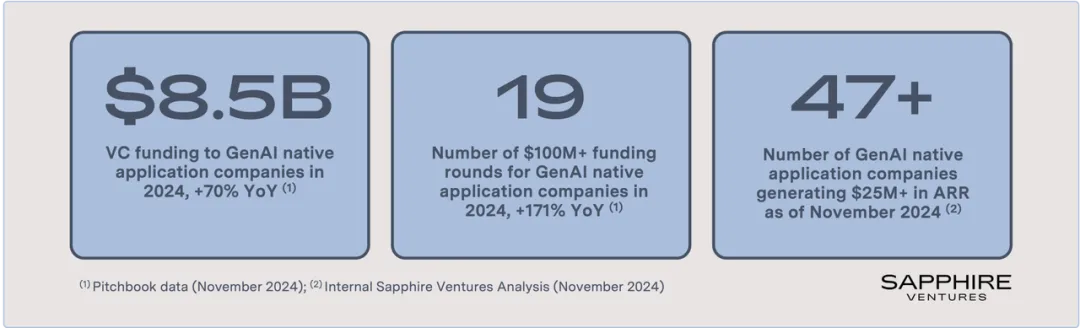
数据显示,AI-native 赛道正在实现从概念到规模化商业化的跨越:截至 2024 年 10 月,该领域已吸引 85 亿美元投资,其中不乏大额融资案例,例如 Perplexity(5亿美元)、Poolside(5亿美元)、Magic(3.2亿美元)、Sierra(1.75亿美元)、Abridge(2.5亿美元)、Glean(2.6亿美元)、Writer(2亿美元)和 EvenUp(1.35亿美元)。
虽然大规模融资反映了市场的乐观预期,但商业成功的真正检验在于企业的实际发展。从这一点来看,AI-native 应用的表现还是很积极的:过去几个月里,具有显著收入增长的应用数量不断增加。据统计,产生超过 2500 万美元 ARR 的 AI-native 应用已从年初的 34 个增加到目前的 47 个。按照这一发展趋势,预计到明年同期,将有相当数量的应用能够达到 5000 万美元 ARR 的规模。
从 Perplexity 到 Writer,从代码开发到营销创意,AI-native 应用正在重新定义各个垂直领域的解决方案。
然而,在这轮变革浪潮中,两个根本性问题值得深入探讨:什么是真正 AI-native 企业的本质特征?这类新型企业将如何重塑传统软件格局?基于这两个核心问题,Sapphire Ventures 通过广泛的实地研究,从 5 个维度构建了评估 AI-native 应用分析框架。本文将深入剖析 AI-native 应用的发展逻辑,探讨其在重构企业软件版图中的关键作用。
AI-native 应用指 AI 是应用体验的核心,而不仅仅是一个辅助功能。虽然这个术语被广泛使用,但其定义——如同 AI 领域的许多概念一样——仍在不断演变。通过与 Canva、Glean、Meta、Runway、Figma、Abridge 等公司的开发者进行深入交流和研究,我们提出了一个更具描述性和细致的定义框架:
AI-native 应用的特征
1. 建立在基础 AI 能力之上,包括从大规模数据集中学习、理解上下文或生成新颖输出的能力。
2. 能够突破传统速度、规模和成本的限制,开创全新的可能性。
3. 具备持续改进的能力,既可以利用底层模型的进步,也可以通过真实世界数据的反馈循环来提升性能。
4. 拥有一定程度的专有 AI 技术,而不是完全依赖现成的解决方案(例如,针对特定功能微调开源模型、模型编排等)。

需要特别指出的是,AI-native 并不意味着应用必须从一开始就具备GenAI 功能。
如同一些传统软件巨头成功从单机版本过渡到 Cloud-native 产品那样,例如 Adobe Photoshop、Microsoft Office 等,许多公司同样可以随时间推移,逐步从 Cloud-native 演进为 AI-native 。
AI-native 是一个过渡性标签
“AI-native”这个术语虽然在当下具有一定的区分意义,但终将只是一个阶段性的概念。就像我们现在很少再提” Internet-native “、” Cloud-native “或” Mobile-native “一样,随着 AI 成为几乎所有产品和服务的标配,这个标签也将逐渐淡化。
我们在当前这个早期阶段使用这个概念,主要是为了区分两类企业:
• 一类是迅速强化和扩展现有产品的企业,
• 另一类是基于全新能力和理念从 0 开始构建的企业。
随着时间推移,这种界限将变得模糊,“是否 Day 1 就围绕 AI 构建产品这件事”将不如企业在产品开发和组织建设过程中对 AI 的深度融合来得重要。
即便在一个更加 AI-native 的世界里,价值创造的基本驱动力并未改变。企业仍然需要深入理解客户痛点,打造满足并超越客户需求的产品和服务。优秀的创业者依然要组建出色的团队并持续不懈地执行。无论 AI 技术多么先进,它始终只是服务于这些目标的工具,而不是一味寻找应用场景的“锤子”。

02.
评估 AI-native 应用的五维框架
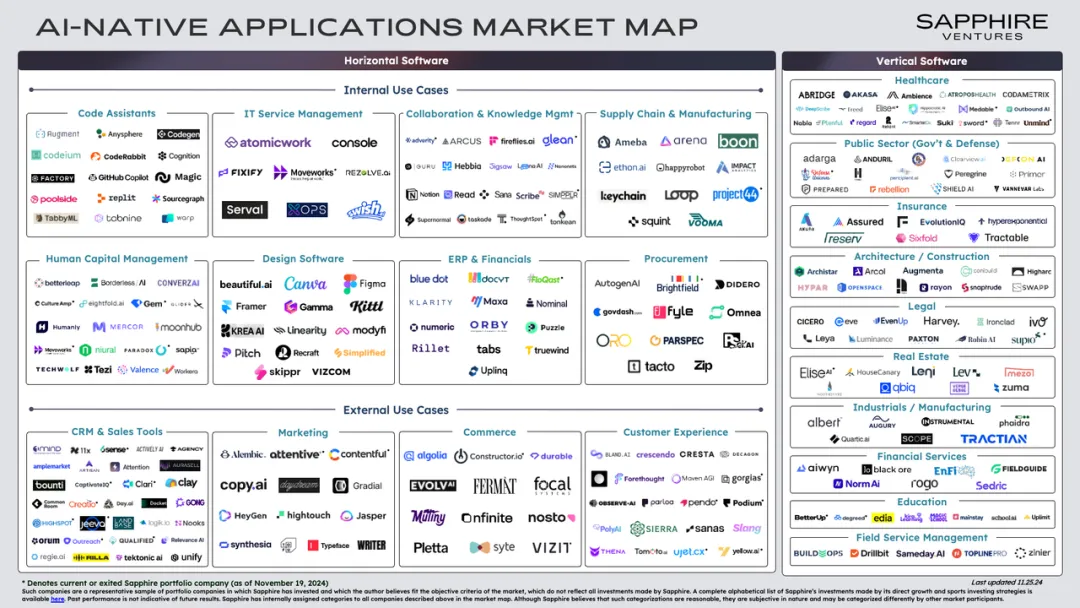
Sapphire Venture 从今年开始一直使用一个框架来评估构建 AI 应用的公司,这个框架包含了 5 个维度:设计(Design)、数据(Data)、专有领域知识(Domain Experience)、分发(Distribution)以及动态性(Dynamism)。
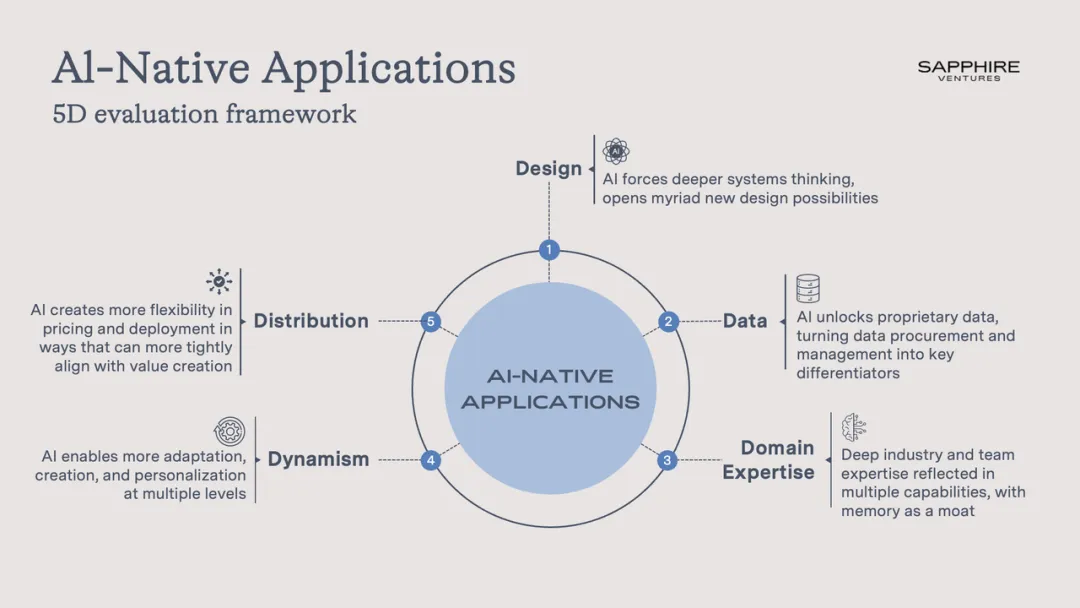
1. 设计(Design) AI 推动更深层的系统思维,开启了众多新的设计可能性。
2. 数据(Data) 利用AI 释放专有数据的价值,使数据获取和管理成为关键的竞争优势。
3. 专业化(Domain Expertise) 深厚的行业和团队专业知识体现在多个能力层面,其积累的经验形成护城河。
4. 动态性(Dynamism) AI 实现多层次的适应、创造和个性化能力。
5. 分发(Distribution) AI 为定价和部署创造了更大的灵活性,使其能够更紧密地与价值创造保持一致。
考虑到企业软件领域日益激烈的竞争,以及在 AI 辅助开发下,产品依靠功能拉开差异化的周期快速缩短,我们认为企业需要在这些维度上实现差异化,才能建立持久的品类领导地位。
设计:核心竞争力
在企业软件这个万亿级市场中,长期以来功能主导着产品开发,而用户体验设计往往被忽视。传统企业应用充斥着复杂的配置选项、繁琐的菜单结构和过度的通知提醒,虽然功能完备但难以带来愉悦的使用体验。随着 AI 技术的发展,这一状况正在发生根本性改变,设计正成为新一代企业软件的核心竞争力。
创建新的交互范式
过去两年,聊天和搜索界面已成为生成式 AI UI 的主导形式,为用户提供了与数据交互的新途径——提问、综合分析、总结和头脑风暴等多样化应用场景,都可以通过基于文本的 AI 助手完成。
• 功能解锁:传统企业工具中的强大功能往往因用户不了解或使用门槛高而被闲置。通过自然语言(文本或语音)表达需求,用户现在可以更好地使用这些既有功能。
• 多模态突破:多模态生成式 AI 模型正在快速追赶文本模型的水平,为软件交互方式的创新提供更多可能。更高性能的语音和视频模型提供了新的创建、捕捉和转换方式,补充了传统的点击和输入操作。
• 发展趋势:OpenAI 的 Canvas 功能和 Anthropic 的 Artifacts 展示了从聊天机器人向协作画布(co-creation canvases)的演进潜力,以及从辅助工具(co-pilots)到自动化工具(auto-pilots)的转变。

加速反馈循环
Gen AI 输出的非确定性特征(non-deterministic nature)为生产环境部署带来挑战。在模型层面,RLHF 在提升 AI 与人类意图一致性方面发挥重要作用。在与产品负责人的交流中,收集到多种反馈机制的案例,如
• 传统方式:输出内容的赞踩投票、星级评分系统。
• 人工审核机制:由专业审核人员对 AI 系统的输出进行审查和评估,帮助确保内容质量并收集改进建议。
• 创新监测:通过分享行为、停留时长、内容时效性、互动频率、复制粘贴等方式收集用户意图信号。
那些能够智能且无干扰地将反馈整合到用户体验中的产品,将实现更快的迭代速度,并能更好地满足用户需求。
构建 AI-native 系统
从与 AI-native 公司的交流中,一个最重要的发现是他们在应用设计中展现出成熟的系统层面思维。这包括在现成的通用人工智能组件和为特定用例优化性能的专有能力建设之间取得平衡。同时,这还涉及在模型层面运用多种基础技术(如微调、RAG、prompt engineering 等)和集成方法,从而在 query level 实现最佳的性价比。
许多 AI-native 应用在用户界面层的优雅设计背后,实际上掩盖了大量后端的复杂性。

此外,随着 AI 从行动辅助(assistance)转向决策(answers)和代理(agents),在流程各环节融入可解释性变得尤为重要。因此,AI-native 应用必须:
• 清晰展示输入与输出的关联;
• 引用具体内容来源;
• 适时提供置信区间;
• 为需深入了解系统性能的用户提供更详细的解释机制。
应用案例
增强型搜索体验:Perplexity.ai 和 OpenAI 的 ChatGPT Search 通过集成相关网页链接和引用来增强 AI 生成的响应内容,提升可信度。
Perplexity.ai
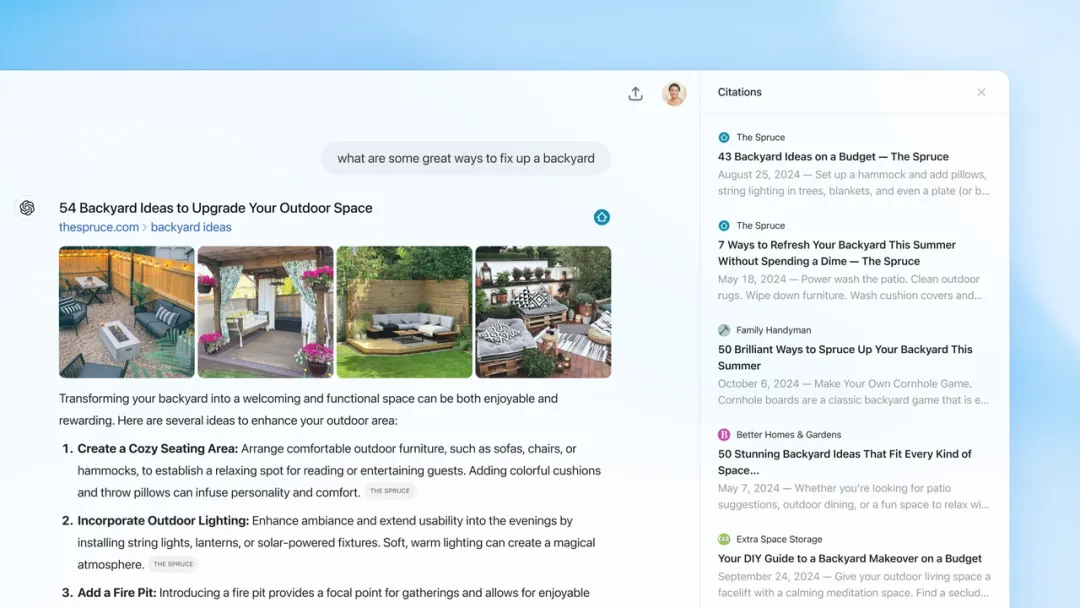
ChatGPT Search
精细化交互设计:Hebbia 和 Reliant AI 采用表格式用户界面,建立起强大的反馈循环机制,让用户能够在更精确、细致的层面上与输出内容进行交互和调优。
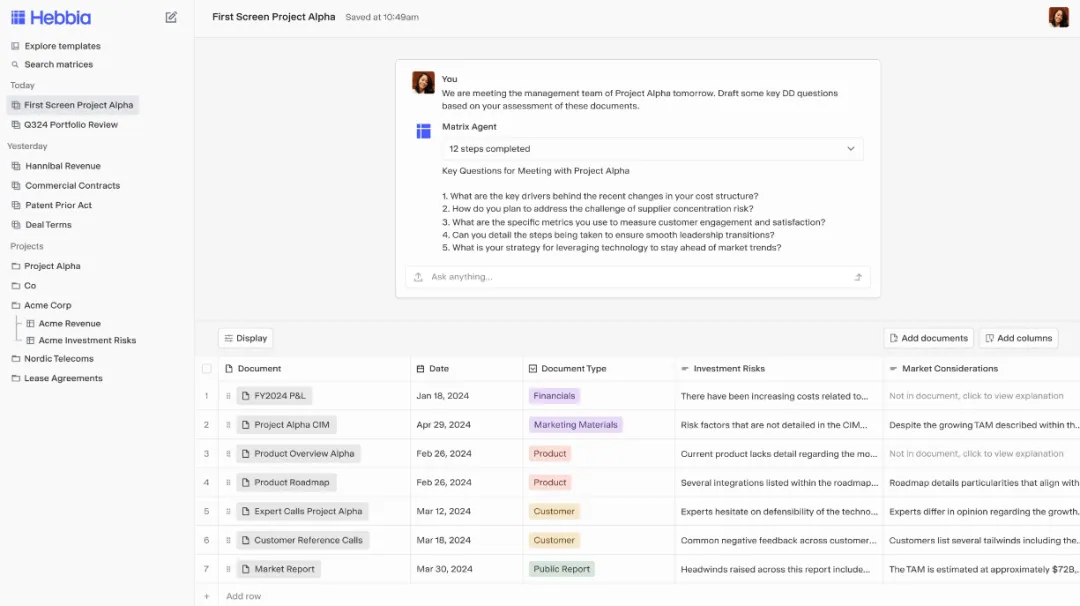
Hebbia

Reliant AI
专业开发工具:Cognition 提供原生代码编辑器,用户可以直接在生成内容旁边进行开发工作,帮助模型根据偏好的编码实践进行优化。
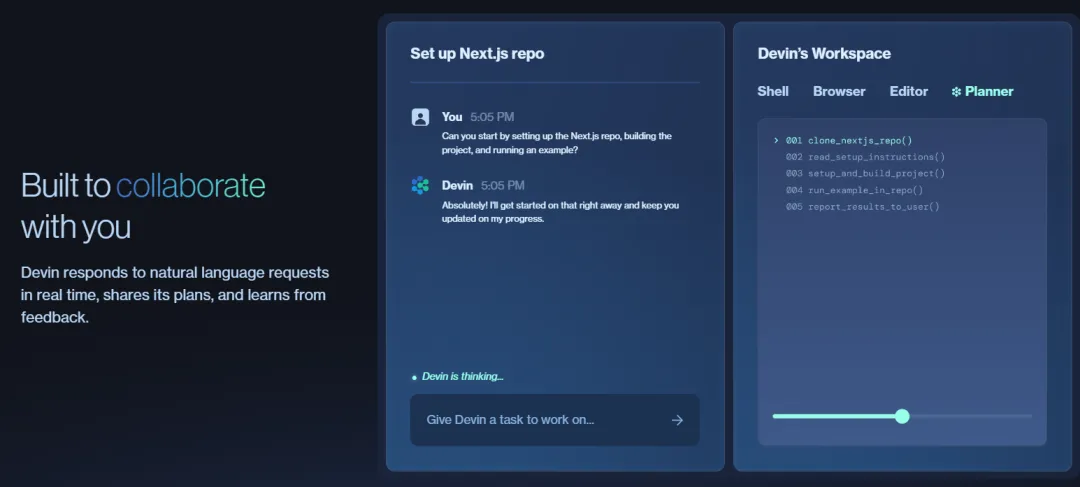
Cognition
行业解决方案:
1)Rilla 运用多模态 AI 中的语音转文本技术,分析客户对话以改进销售培训,
2)Bland.ai 通过部署易于培训的数字化客服代理(配备文本转语音功能),重塑销售和支持服务流程。
数据:关键资产
数据对于训练 foundation models 的重要性已经成为共识,这些模型支撑着过去两年涌现的所有 AI 产品和服务。在应用层面,数据的重要性可能更高,因为它能帮助将各种通用的基础功能转化为针对性的、具有竞争壁垒的产品,从而更好地满足客户需求。
强化端到端的数据管理
“没有数据战略就没有 AI 战略”这句话虽依然真实。尽管 AI-native 应用能够受益于基础模型公司集成的全球数据,以及客户现代化的数据资产,但通过强有力的数据管理实践,企业仍然可以实现差异化竞争,这个维度主要包括:
• 数据采购和策划(data procurement and curation),
• 数据质量管理(data quality),
• 数据治理(data governance),
• 数据安全(data security)。
随着多模态模型能力的提升,跨结构化和非结构化数据的处理能力将成为充分发挥生成式 AI 潜力的关键。那些能够更智能、更快速地以安全方式收集、清理和整合数据的公司将在竞争中胜出。
激活沉睡数据
许多企业早已意识到数据的价值,但如何有效利用这些数据一直是个挑战。在与生成式 AI 公司领导者的交流中,我们发现其产品能够激活两类沉睡数据:
• 存储在各类系统中未被充分利用的数据,例如 Box、Google Drive、SharePoint 中的数据,
• 完全未被系统捕获的数据,例如客户通话、患者讨论、会议记录等。
这种数据激活带来显著优势,使用户能够:
• 更流畅地与现有数据交互;
• 更快地访问适合其角色和特定需求的最优内容;
• 为数据资产带来更多结构化和明确的分类体系。
这些优势进一步促进对数据架构的优化,以支持更多 AI 投资,以及向那些已证明早期投资回报(ROI)的可信 AI-native 应用合作伙伴提供更多数据。

创造专有数据资产
除了激活现有数据,生成式 AI 还能捕获全新的数据集,这些数据集可能成为相对于传统应用的竞争优势。新型数据包括:
•多模态交互数据(multi-modal engagement data),
• AI 生成内容的创建和使用元数据(metadata),
• 微观和宏观层面的数据模式识别(pattern recognition)。
这些数据在传统系统中并不存在,它们为 AI-native 企业提供了捕获数据、形成数据整合枢纽和构建差异化工作流程以扩展数据价值的机会。这些新数据和对用户工作流程的理解可以转化为训练数据,从而不断改进底层模型性能,扩大 AI-native 企业的竞争优势。

应用案例
• Glean:通过训练定制 LLM 和构建组织特定知识图谱,利用实时反馈为每个用户提供个性化、上下文相关的搜索结果。
• Writer:利用专业 LLM 深入理解企业数据中的语义关系,为任何搜索或应用查询检索相关、符合上下文的结果。
• Jeeva.ai:实时整合多源销售潜客数据,使用户能够精确定义目标客户画像(ICP),快速构建准确的潜客列表,并生成高度个性化的信息以自动化互动。
专业化(Domain Expertise):
AI-native 应用的加速器
过去一年,垂直领域的 AI 应用(Vertical AI)备受关注。这种关注是有充分理由的:面向特定行业的 AI-native 应用发展最快,在法律、医疗、房地产和金融服务等领域都有显著案例。
Gen AI 展现出的深度领域理解能力,不仅体现在具体产品交互中,还体现在端到端工作流程中,这种能力对于 vertical 和 horizontal 软件都会产生重要影响。
将 Domain Knowledge 转化为 AI 工作流
Vertical AI 快速发展的一个重要原因是,GenAI 在将特定领域的终端用户活动数字化方面表现出色。通过与创始人和产品负责人的交流,我们发现了许多实践案例:
• 更准确的对话转译(如医生-患者讨论);
• 更全面的研究输入总结(如法律研究和金融分析);
• 更精准的用户关系理解(如企业搜索中的用户间及用户与实体间关系)。
在这些场景中,GenAI 模型被训练来深入理解特定行业或功能的上下文,并自动执行相关操作,帮助用户更快、更高效地达成目标。
专业化并不总是特定于行业。一些产品和工程负责人描述了他们如何研究客户组织中的高级用户和资深领导者的使用模式。通过将这些模式转化为提示和结构化输出,他们致力于让这些见解在组织的各个层面都能获取。
比如 Supio 产品负责人 Pamela Wickersham 就提到:“我们观察平台上经验丰富的用户的行为,并将其转化为其他角色和不同层级人员可重复使用的模式。”通过这种方式,基于经过企业特定数据微调的基础模型的生成式 AI 应用,可以实现提升整个员工队伍水平的知识转移。
规模化实时洞察
AI-native 应用的另一个优势是能够近实时地从海量数据集中获取洞见。新的 AI-native 应用正在多个领域涌现,它们结合了经过验证的行业特定文档和数据(如美国证券交易委员会的 EDGAR 数据库)、微调模型和基于对话的界面,大大加快了客户识别和处理特定目标相关信息的速度。
这一趋势在法律领域表现得最为明显,如 Harvey、EvenUp、Robin AI 和 Supio 等公司的实践。同样的模式也在医疗、公共部门、保险、金融服务和教育领域开始出现。
AI-native 应用在处理特定领域需求时赋予用户超人的能力。毫不夸张地说,那些过去需要大量初级员工(或外部顾问)花费数天或数周才能回答的问题,现在通过这些新服务几分钟就能得到至少部分答案。
全球与本地知识的融合
AI-native 应用在融合知识方面具有独特优势,主要体现在三个层面:
• 已经 embedded 到基础模型中的全球性知识(global knowledge);
• 行业数据库中的领域专业知识(domain-specific knowledge);
• 组织自身积累的专有认知。
其中,组织层面的专业知识往往体现在高质量的演示文稿、备忘录、会议记录、专有研究、培训资料和历史文档中。这些内容用于优化 AI-native 应用的输出,确保其符合用户对“高质量内容”的预期。
这种融合不仅仅是更好地访问专有数据,更重要的是理解这些数据如何在特定场景下反映员工、团队或组织的知识积累。通过这种组合,用户能够突破单个任务优化的局限,实现整个工作流程的自动化,同时专注于更具体的成果。
应用案例
• Abridge:通过基于大规模医疗对话数据集训练的多 LLM 架构,将实时的患者音频转换为精确的临床记录。
• EliseAI:利用 LLM 整合来自物业管理系统(PMS)、客户关系管理系统(CRM)、知识库以及租赁专业人员的相关信息,自动回应潜在和现有租户的询问。
• Supio:基于大量人身伤害案例数据训练的专有模型,能够高精度地分析和生成法律文件。
• Magic School:提供 80 多种专门的 AI 工具,帮助教育工作者改进和自动化课程规划、考核编写、学术内容生成与管理等工作。
动态性:AI-native 应用的自适应引擎
Ben Thompson 在其文章 Meta’s AI Abundance 中很看好 Meta 在GenAI 领域的机遇,尤其是公司利用 GenAI 加速多模态动态广告创建和测试的能力,以及通过新的”Imagine Yourself”模型实现下一代个性化内容的潜力。这对数字营销和电子商务行业的潜在影响显而易见,且这种影响可能很快就会显现。
这也反映了更深层的趋势:GenAI 将推动应用体验从静态向更动态化转变。虽然这一维度的普适性略低于我们之前讨论的三个维度,例如,在处理总账(General Ledger)时并不需要太多动态性,但这种转变趋势已经显现。
产品体验优化
大多数公司已经从单一模型的概念测试阶段,进阶到编排多个模型交互的序列来优化特定场景的输出效果。从输入到输出的处理过程变得更加动态化。这些公司在开发基础设施时特别注重灵活性,使他们能够轻松地替换模块化组件,以实现性能提升和成本优化。
这种动态需求催生了模型路由器(model routers)这一关键的新型 infra 组件,比如 Martian 等公司正专注于此类产品的开发。这些 routers 是支撑 AI-native 应用的 infra 技术栈中的重要组成。
未来,更多当前需要用户手动选择的高级 AI 功能,例如在 ChatGPT 或 Perplexity 中选择底层模型、设定输出语气、对输出进行评分等,将逐渐隐藏在系统后台,由底层系统更加自适应地代替用户做出决策。
GenAI 客户旅程
我们在设计部分中提到,企业软件在用户体验方面并不是很好,虽然这种情况难以在短期内彻底改变,但 GenAI 为改善现状带来了可能。我们设想通过创建更具动态性和适应性的内容体验,体现对终端用户和客户的深入理解。例如:
• 定制化营销:根据潜在客户偏好定制的销售和营销材料——从外联邮件到演示文稿,从落地页到合同制作。
• 个性化购物:电商平台让购物者通过数字孪生技术在虚拟空间或数字化身上预览商品。
多层次超个性化
企业软件正迎来更广阔的个性化体验机会。随着人工智能不断学习相关偏好、互动模式和关系网络,这种个性化将在企业内部的终端用户、团队、部门和整个组织层面逐步实现。
例如,Outreach 为组织内的每个团队和销售人员都构建了一个定制的赢单模型,并随着交易进展进行实时更新。同时,销售沟通和相关材料也在朝着更精准地匹配个别客户的方向发展。
长远来看,具备共享记忆功能的智能代理(agents)将成为这一主题最完整的体现形式。
应用案例
• HeyGen:提供 AI 视频创作平台,使市场营销和学习发展团队能够快速生成超个性化视频内容,在销售、支持和培训领域部署全自动的对话式视频体验。
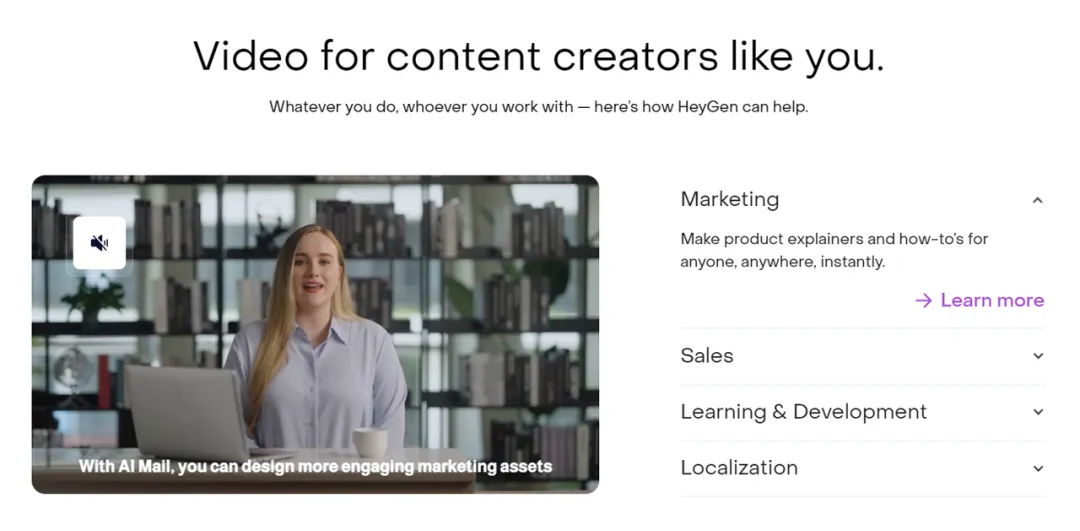
• Mercor:开发了能实时评估候选人的 AI 面试官,在处理简历和档案数据的同时,能够适应实时对话。

• Evolv AI:通过 AI 驱动的实验持续调整用户体验,基于实时用户行为优化客户旅程。
分发:AI-native 应用的定价策略
最后,我们需要探讨如何包装和定价这些新的 AI 价值。一个关键问题随之而来:生成式 AI 是否会给云时代应用公司青睐的传统按席位收费的 SaaS 模式带来灭顶之灾?正如我们在 2024 年 8 月的市场备忘录中所写,对软件即将消亡的预言被严重夸大了。虽然现在判断是否会出现一个颠覆现状的主导模式为时尚早,但显然企业正在积极尝试,在平衡新价值和成本的同时降低新竞争威胁的风险。
价值最大化的灵活定价策略
我们已经进入了一个更加多元化的定价环境,现阶段企业已经开始采用的策略有:
• 在现有服务中免费嵌入 GenAI 功能(如Workday);
• 创建包含 AI 功能的现有产品高级版本;
• 推出全新的独立 GenAI 应用;
• 在基础平台之上测试基于消费和结果(consumption and outcome-based )的收费模式。
属于 GenAI 时代的主流定价方式还没有确立,可能因类别而异。但我们认为GenAI 是一项能够扩展企业价值交付方式的技术。未来可能会包含 application 和agents 的混合,以及 co-pilots and auto-pilots 的结合。
在定价方面,我们相信会看到按席位(seat-based)、按消费(consumption-based)和更有选择性的按结果(outcome-based)收费等多种模式的混合,而不是非此即彼的争论。那些能够平衡不同模式以确保客户覆盖面,同时更透明地将定价与价值交付对齐的应用开发者,将在未来占据优势地位。
案例
关于软件赋能服务的增长以及面向特定商业成果的代理系统的潜在兴起,已有大量讨论。在此我们只想强调一点:真正的颠覆性创新从来不仅仅是产品技术能力的函数,往往还包括商业模式的转变(例如从许可制到订阅制软件的转变)。
许多公司已经引入了包含基于消费和基于结果组件的新定价方式。以下是一些值得注意的例子:
• 传统巨头的创新:
1)Salesforce 对其 Agentforce 套件采用每次对话 2 美元的定价。
2)Zendesk 对自动解决的问题收取 1.5-2 美元不等。
• 客户服务 AI 代理:
Sierra、MavenAGI、Decagon 和 Crescendo 基于结果(如已解决的工单)定价。
• 专业服务创新:
Reserv 提供基于 AI 的理赔处理服务,根据已开立和执行的理赔数量定价。
• 内容生成应用:
1)Synthesia 按生成视频的分钟数收费。
2)Imagen 和 Aftershoot 等编辑工具按编辑次数收费。
03.
AI-native 应用的未来
前面 5 个维度为评估 AI 应用提供了一个清晰视角,但真正的突破将来自于如何创新性地融合这些维度。虽然为现有产品增加 AI 能力很必要,但要在未来胜出,企业需要更深层的变革:打造统一界面、始终在线的多模态应用,将分散的服务整合为一体化体验,以及采用灵活的计量收费模式。
要实现这一愿景,需要技术栈各层面的显著提升。这建立在规模效应延续的假设之上,同时还需要大量基础工作:提升性能、减少幻觉、确保一致性、维持合规、加强安全和管理成本。令人欣慰的是,这些都是明确的挑战,我们投资组合中的企业领导者认为,即便只基于当前模型的能力,只要成本持续下降,未来几年仍有巨大的创新空间。

GPT-5 等新一代模型的出现一定会改变市场对 AI 发展的预期,无论其实际表现如何,突破性进展会带来狂热乐观,但如果只是渐进式改进则可能在短期内影响市场预期和估值。无论如何,未来几年我们将更清楚地看到什么可行、什么不可行,以及具体成本。
值得注意的是,推动行业发展未必是更新一代模型。对于未来几年最令人期待的发展,很多产品负责人都提到了 reasoning 研究,以及它如何加速agent 系统从核心理解发展到深度思考的过程。

随着模型能力的提升和多模态技术的进步,我们正进入应用层面的实验创新新时代。对于 AI 应用开发者来说,他们可以利用的工具库几乎每周都在丰富,产品架构、模型选择、界面设计、数据整合方式和交付机制的创新等等。
但也可能出现的情况是:很多领域 AI 的大规模部署可能比预期更慢,大部分重塑 workflow 的尝试可能失败,AI 或许会加强现有软件巨头的地位而非颠覆它们。然而,那些能够展现组合创新能力,快速整合新技术的企业,必将成为定义 AI 时代的重要力量。














暂无评论内容