
编译:Chris
![]()
在 Lex Fridman 和 Anthropic CEO Dario Amodei 的对谈中,Dario 提到今天 LLM 还有很多领域值得探索,“与其探索新的架构,不如去研究可解释性”。本篇内容就是联合创始人 Chris Olah 对 Anthropic 在机制可解释性的详细阐述:
• 机制可解释性研究的目标是通过对神经网络的 weights 进行逆向编程找出“模型运行的具体算法是什么”,而不只是关注神经网络的输入和输出,
• 训练模型更像是培育植物而不是传统软件工程中的编程,
• scaling law 同样存在于机制可解释性上,
• 我们今天观察到的机制可解释性可能只是某个更大、更稀疏的网络的“投影”;
……
Chris Olah 过去 10 年里一直专注在机制可解释性领域的研究上,在参与创立 Anthropic 之前,他在 Google Brain和 OpenAI 期间也一直以机制可解释性作为工作焦点。
作为和 OpenAI 齐平的头部模型公司,Anthropic 虽然没像 OpenAI 那样通过 ChatGPT 建立强势的 C 端品牌影响力,但团队在 LLM 技术和应用框架上做了大量投入,例如通过 Constitutional AI、机制可解释性等揭秘 AI 黑盒、提升 LLM 可用性,以及在今天发布的 MCP 框架,让模型拥有“眼睛”和“手”,Claude 有可能成为“任务调度中心”。
💡 目录 💡
01 什么是机制可解释性
02 Features, Circuits, Universality
03 神经网络里的叠加
04 Towards Monosemanticity
05 可解释性机制里有 scaling law 吗?
06 机制可解释性研究的新方向
01.
什么是机制可解释性
Lex Fridman:我们可以先从机制可解释性(mechanistic interpretability) 这个概念开始讨论。
Chris Olah:我个人认为理解神经网络首先要建立一个基本的认知,也就是我们并不制造神经网络,而是培育神经网络。我们首先会设计神经网络的架构,同时我们会设定一个 loss objectives(损失目标)。神经网络会像一个支架一样,支持电路在其上生长。神经网络从随机状态开始不断生长,而我们设定的 loss objectives 则会像光引导植物生长一样引导神经网络的生长。因此,我们先创造了支架并设定了光照条件,但借由这一过程我们所创造出的是一个我们当下正在研究的生物实体和有机体,而不仅仅是生长条件本身。模型之所以可以做到这一切,是因为我们“培育”了它,而不是创造或写出了它。
这个过程与传统的软件工程有所不同,因为这个过程的最终产物是一个具备惊人的任务处理能力的模型:它可以撰写文章、进行翻译、理解图像等等,而这些任务是我们无法通过直接编程可以实现的。
这件事又引发出另一个终极问题:在这个神经网络的系统内部究竟发生了什么?对我来说这是一个非常深刻也非常令人兴奋的科学问题,而且从安全性的角度而言,这也是一个非常深刻的问题,因为对于神经网络内部系统的探寻和理解不仅仅具有单纯的科学价值,更关系到我们能否确保 AI 系统的可控性和安全性。
Lex Fridman:机制可解释性实际上更接近于神经生物学(neurobiology)?
Chris Olah: 的确是这样的。我可以举个例子来说明哪些情形不属于机制可解释性的研究范畴。一直以来,关于 saliency maps(显著性图)的研究有很多,它的逻辑是:假设现在有一张图片,模型认为这是一张狗的图片,我们就要关于图片中的哪个部分会导致模型作出‘图片是一张狗’的判断进行解释解释。
显著性图的研究可以论证模型的关键信息,但无法证明模型内部究竟运行了何种算法,以及模型最终得出这个结论的推理路径。虽然这个方法论可以揭示哪些因素对模型很重要,但它不能直接告诉我们模型究竟运行了何种算法,以及模型如何完成人类之前无法完成的任务。
因此我们需要使用“机制可解释性”这个概念来划清界限,将我们的研究与其他现有研究领域做区分。今天这个“机制可解释性”概念已经发展成一个涵盖多种研究方向的总称,我认为这个研究体系的独特性在于:首先,这个体系关注的是机制本身。如果把神经网络看作是计算机程序,那么神经网络的 weights 就像是二进制程序代码,我们的目标是通过对这些 weights 做逆向工程来找出其中运行的算法。
我们可以把神经网络想象成是一个已经编译好的计算机程序,而神经网络的 weights 就像是二进制代码,网络运行时产生的 activation 则可以理解为计算机程序的执行过程,我们的最终目标是理解神经网络的 weights 是如何运行的。因此,机制可解释性的目标在于厘清这些 weights 与具体算法间的对应关系。要实现这个目标,我们就必须理解 activation,因为它就像是内存一样。这就好比对计算机程序进行逆向工程时,尽管已经掌握了二进制指令,但为了理解某个特定指令的含义,我们仍然需要了解它所针对的特定内存中的存储内容。所以机制可解释性研究往往会同时关注这两个方面。
当然,正如我之前提到的,机制可解释性的范围很广,甚至并不是所有从事相关研究的人都会认为自己的研究领域可以被划分到这个体系中。
我认为它的一个显著性的特点是,优化算法的能力(尤其是梯度下降)比人们想象的更强大。我们之所以要去理解这些模型,正是因为我们从始至终都并不清楚如何直接编写出他们,而梯度下降比我们更有能力找到更好的解决方案。因此,我认为机制可解释性研究的另一个特点就是我们不要先入为主的揣测模型内部发生的事情,不预设目标,不假设某种流程一定存在或一定以某种方式运作。相反,我们通过自上而下的方法观测到模型内部的实际情况,并基于这个我们观测到的客观情形对模型展开研究。
02.
Features, Circuits, Universality
Lex Fridman:你们在研究中发现的特征(feature)、电路(circuits)和普遍性(universality)都是机制可解释性研究可行性的证明?
Chris Olah:是的,至少在某些层面,我们发现了一些反复出现的元素、特征和电路连接。比方说如果在每一个视觉模型里,都能够发现曲线检测器和高低频检测器两种基础组件。实际上,我们有理由认为,这些反复出现的元素与特征同时存在于生物神经网络与人工神经网络中。
一个非常典型的例证是视觉模型的 early layers 上有一个机制叫做 gabor filters(滤波器)存在,我们在猴子的大脑与模型中都发现了这种机制。同时,我们还在人工神经网络中发现了高低频检测器,而随后的研究则证实老鼠的大脑中也同样存在这样一种视觉处理机制。所以,我们首先在人工神经网络中发现了这些具备普遍性的特殊现象,然后又在生物神经网络中发现了同样的特征。
有一个非常著名的研究成果叫做“grandmother neuron”,也叫做“Halle Berry neuron”,我们在研究视觉模型时发现了与这种神经元的工作机制非常相似的现象。
💡
Grandmother neuron 是一种假想中的神经元,最初由波兰的神经科学家Jerzy Konorski在1968年提出,它的核心假说是,人类在大脑数十亿神经元中,存在专门识别特定概念的单个神经元。例如,当祖母出现在时,在亿万神经元里,只有一个神经元被点亮,即祖母神经元。
我在 OpenAI 参与 CLIP 研究的时候,我们发现了一些特定的神经元会对图像中的同一实体产生反应。
比如,我们发现了一个特定的“特朗普神经元”,特朗普确实一直是一个人们经常讨论的热门话题,所以,我们在研究的每个神经网络中,我们都能找到一个专门用于识别“特朗普”的神经元。而且特朗普是唯一一个始终拥有专属神经元的人,因为在有的模型中我们可能会发现一个奥巴马神经元,而有的模型中则可能会有一个克林顿神经元,但所有模型中总是会有一个特朗普的专属的神经元。这个神经元会对特朗普的面部图像、“Trump”这个词,以及所有与特朗普相关的内容产生响应。
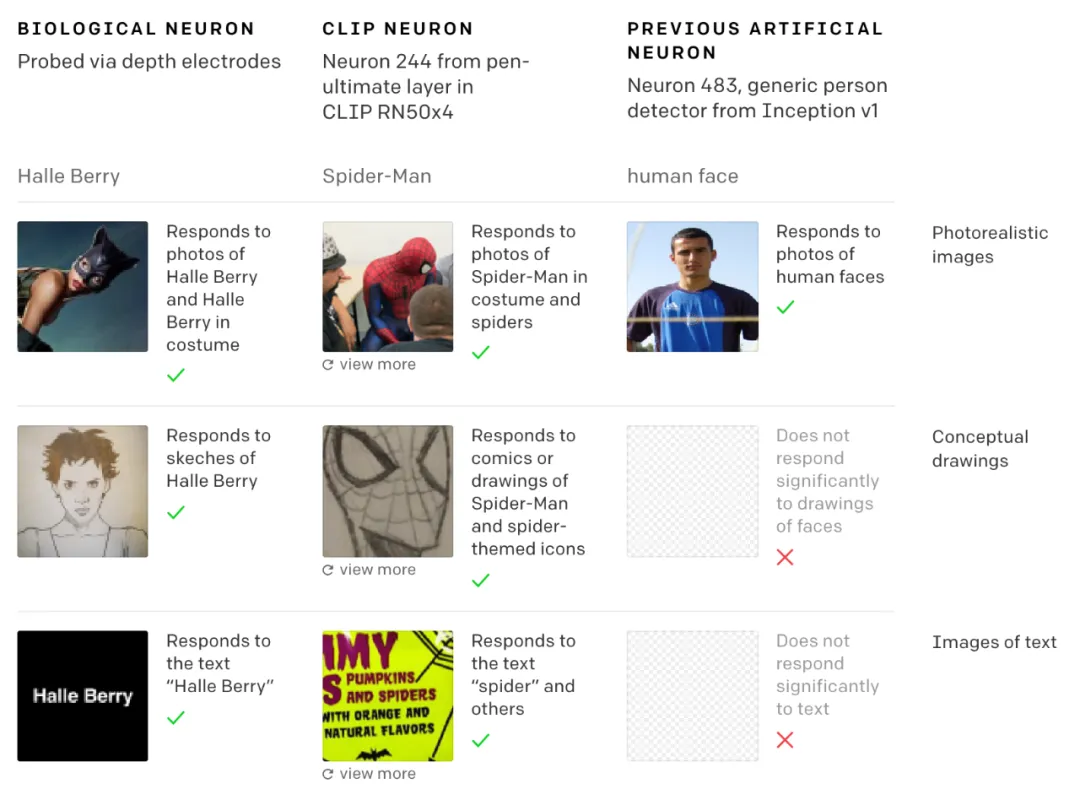
所以它并不是仅仅对某个特定的例子做出反应,也不是仅仅对他的面部特征做出反应,而是对这个整体概念进行了抽象处理,这个现象也和 Quiroga 等人关于 Halle Berry neuron 的研究结果非常相似。
如果这种普遍性现象确实存在,即人工神经网络和生物神经网络中存在类似的特征,会是一个特别重要的科学研究成果。这个现象表明梯度下降算法某种程度上找到了问题的正确分解方式,而很多系统和不同的神经网络架构最终都会收敛到这种分解方式上。换句话说,现实中可能确实存在一种非常合理的抽象方式来切分问题,以至于许多不同的系统最终都会抽象收敛到相似的概念上。但这些都只是基于我们观察到的现象做出的一些简单推测,还没有足够的证据可以支撑。
Lex Fridman:所以有可能为了更好地理解神经网络内部,我们可以从这些普遍性特征入手?
Chris Olah:是的,当我们发现某些特征会在不同的神经网络中反复出现时,背后一定存在某种必然性。
Lex Fridman:你在 2020 年发表的 Zoom In: An Introduction to Circuits 中首次对我们刚才提到的这些特征和神经网络做了描述,可以更详细解释一下吗?
Chris Olah:我可以先描述一些现象来理解这些特征和神经网络。
我用了 5 年左右的时间来研究 Inception V1 这个模型,这是一个计算机视觉模型,在 2015 年的时候 Inception V1 算是最先进的技术,这个模型大约有 1 万个神经元,我花了很多时间研究其中的每一个神经元,有个很有趣的发现:虽然还有很多神经元的功能很难解释,但在 Inception V1 中,确实存在相当多具有明确可解释含义的神经元。
比如,我们发现有些神经元确实专门用于检测曲线,有些专门检测汽车,还有一些分别负责识别车轮、车窗。关于狗的特征识别就更有意思了:有些神经元专门识别狗的耷拉耳朵,有些识别向右侧着的狗的长鼻子,有些则识别向左侧着的狗的长鼻子,还有一些负责识别不同类型的狗毛。
在这个模型中,我们还发现了一系列有趣的特征检测机制:边缘检测机制、线条检测机制、颜色对比检测机制,还有一些我们称之为“高低频检测机制”的精妙结构。整个研究过程中,我感觉自己就像一个生物学家,仿佛在探索一个全新的蛋白质世界,发现各种相互作用的蛋白质。
理解这些模型的一种方式是从单个神经元入手。比如“这是一个检测狗的神经元,那是一个检测汽车的神经元。”,我们还可以进一步研究这些神经元是如何相互连接的,举个例子,当我们研究一个汽车检测神经元时,会问:“这个神经元是如何构建的?”,紧接着就会发现,在它的上一层中,它和窗户检测器、轮子检测器和车身检测器都有很强的连接。比如,它会寻找位于上方的窗户、下方的轮子,以及遍布各处(尤其是下半部分)的车身镀铬部件。这些特征组合在一起,就构成了一个“车”的抽象形象。
我们在前面提到,机制可解释性研究的目标是找出“模型运行的具体算法是什么”,现在,我们只需要查看神经网络的 weights,就能读出一个检测汽车的“配方”。这个配方也许很简单很粗糙,但确实存在,我们把这种连接称为电路(circuits)。
不过问题在于,并非所有的神经元都是可解释的。有时候我们需要分析的不是单个神经元,而是多个神经元的组合。比如,有时候并不是某个单一的神经元来负责表示“汽车”这个概念,模型会把一些汽车的特征信息藏在“狗”相关概念的检测单元中。
神经网络之所以这么做可能是因为在这个阶段它不想在处理汽车这个概念时做太多重复工作。这个发现也让我们意识到,我们不能再以具体某个概念对应特定神经元的思路来理解不同神经元的功能,比如不太可能 100% 的情况是“车”和“狗”分别对应一个具体的神经元,我们需要一个新的概念来描述前面的这种现象,所以我们采用了“特征( feature)”这个概念。
Lex Fridman:电路(circuits)是什么?
Chris Olah:电路就是这些 features 之间的连接。就像我们前面说的,当一个汽车检测器与窗户检测器和轮子检测器相连,并且寻找底部的轮子和顶部的窗户时,这就构成了一个神经网络。简单来说,神经网络就是通过 weights 连接起来的 features 的集合,它们实现了具体的算法。通过研究神经网络,我们就能理解这些特征是如何被使用的,如何被构建的,以及它们是如何相互连接的。
这里的核心假设是我们所说的“线性表示假设(linear representation hypothesis)”。以汽车检测器为例,它的激活值越高,就意味着模型越确信画面中存在一辆汽车。或者说,如果是多个神经元组合来表示“汽车”这个概念,这种组合的激活程度越高,就表示模型越确信看到了一辆汽车。
但也并不是只有这一种路径。我们可以也想象另一种情况:一个汽车检测神经元的激活值在 1 到 2 之间时代表一种情况,但在 3 到 4 之间时却表示完全不同的东西。这就是一种非线性表示。理论上,模型是可以这样工作的。但我认为这种方式效率不高,因为这种计算方式的实现其实相当麻烦。
特征和电路的分析框架是建立在线性代表的假设前提上的。如果一个神经元或一组神经元的激活程度越高,就意味着它们对特定目标的检测信心越强。这样一来,这些特征之间的权重就有了非常清晰的解释。这是整个框架的核心。
我们还可以跳出神经元的框架来讨论这件事。我可以用 Word2Vec 来具体解释。
Lex Fridman:什么是 Word2Vec?
Chris Olah:简单来说就是“king – man + woman = queen”,这个是 Tomas Mikolov 等人在 Word2Vec 研究中的一个很著名的结果。Word2Vec 中之所以可以做这样的“运算”是因为存在一个线性表示。
线性表示假设的核心思想是:在向量空间中,不同的方向都承载着特定的含义,通过将不同方向的向量相加,我们就能表示出各种概念。这可能就是神经网络内部最基本的运作机制。Mikolov 在自己的论文中具体探讨了这一点,也由此发现了一个有趣的现象:我们可以用词向量做“数学运算”。
💡
Tomas Mikolov,捷克计算机科学家,曾在 Google 工作期间提出了革命性的 Word2Vec 技术,其研究彻底改变了自然语言处理领域的词向量表示方法。Mikolov 在 2013 年发表的 Word2Vec 论文提出了一种革命性的方法,通过神经网络把单词转换成向量,使得语义相近的词在向量空间中的位置也相近。这个方法最令人惊讶的发现是,词向量之间可以进行数学运算。
比如我们就可以用“king”这个词的向量,减去“man”的向量,再加上“woman”的向量改变性别属性,最终得到的向量会非常接近“queen”这个词的向量。类似的,比如用 sushi – Japan + Italy 就会得到 pizza。
这就是线性表示假设的核心。我们可以把它纯粹理解为向量空间的抽象概念,也可以把它理解为神经元激活模式的一种表现,但最本质的特点是:空间中的方向都具有实际的语义含义。而且这个概念最关键的特性在于,这些概念可以叠加:我们可以独立地修改代表不同概念的不同的向量,比如性别、国别等,然后把这些向量叠加在一起,又形成一个新的完整的概念。
Lex Fridman:线性假设会随着模型 scaling up 仍旧成立吗?
Chris Olah:到目前为止,我看到的所有现象都符合这个假设。理论上我们完全可以设计出一种神经网络,通过设定特定的 weights 使它不具有线性表示的特性,我们也不会基于线性表示的特征去理解这种神经网络。但我观察过的每个自然形成的神经网络都具有这种线性表示的特性。
最近也有一篇论文在探索这个理论的边界,比如有些研究在研究多维特征,它们发现与其说是单一的方向,不如说是一组相关的、连续变化的方向的集合。不过在我看来仍属于线性表示的范畴。也有一些论文提出在一些规模很小的模型中可能会出现非线性表征,但我认为这个问题现在还没有定论。
所以到目前为止,我们看到的所有现象都与线性表示假设相符合,这其实很出人意料,目前有大量证据表明,这种线性表征至少在神经网络中是极其普遍的现象。
也可能会有人质疑,认为还不能完全确定这个理论是对的的时候,就把它应用在神经网络研究中,是否会存在风险。但我认为,认真对待一个假设并将其推演到极限,本身就很有价值。
科学史上充满了被证明是错误的假设和理论,而正是通过把这些假设当作前提并推演到极限,我们才获得了很多重要发现。
03.
神经网络里的叠加
Lex Fridman:叠加假设(superposition)也很有趣,可以给我们讲讲 吗?
Chris Olah:刚刚我们讨论了词向量,比如可能会有一个向量对应性别,另一个向量方向代表皇室身份,还有其他向量代表意大利、食物等这些概念。通常而言,这些词嵌入的维度大约在 500 维或 1000 维左右,所以如果所有的向量都是严格正交的(即完全独立的),那么我们最多只能有 500 个完全独立的基本概念。
在这个限定下,我们必须先把单复数、名词、动词、形容词这些更基础的语言概念放进这 500 个范围内,而不是具体的意大利、日本这些具体国家或者其他食物的名词,我们首先需要确保更基础的概念有对应的解释,否则世界上还有那么多国家都无法被表示出来。
由此就带来一个问题,模型要如何在线性表示假设成立的同时,又表示出比其维度所能容纳的概念更多的含义呢?这意味着,如果线性表征假说是正确的,那一定还有更精妙的机制在起作用。
首先要介绍另一个重要的现象,多语义神经元(polysemantic neurons)。在我们研究 Inception V1 时,发现有些神经元会对多个相关的事物产生反应,比如负责汽车检测和负责曲线检测的神经元,这些神经元可能对很多具有关联的概念作出响应,更有趣的是,还有一些神经元会对完全不相关的事物产生反应。事实证明,即使是那些看起来很“纯粹”的神经元,如果我们观察它们的弱激活状态(比如最大激活值的 5%),我们会发现这些激活所对应的现象与这些神经元原本应该检测的目标完全不同。
比如说,当我们观察一个负责曲线检测的神经元,查看它在 5%激活水平的情况时,你可能会把这种状态下的激活简单地解释为“噪音”,但也有可能是这个神经元在执行其他的功能。这种现象是如何产生的呢?
数学中有一个概念叫做压缩感知(compressed sensing):通常情况下,当我们把一个高维空间的向量投影到低维空间后,我们无法再通过反投影的方式重建出原始的高维向量的,因为投影过程中有些信息丢失了。这就像你无法对非矩形矩阵求逆,只能对矩形矩阵求逆。
但这个结论并不完全正确,因为如果这个高维向量是稀疏的(大部分分量都是零),那么在很大的概率下,我们还是可以从低维投影重建出原始的高维向量。叠加假设认为这就是神经网络中发生的现象,尤其是词嵌入(word embeddings)过程中。词嵌入能够同时让这些向量具备实际的语义,这是通过利用两个特点实现的:一是它们在相当高维的空间中运作,二是这些概念所对应的向量本身就是稀疏的。比如说,我们通常不会同时谈论日本和意大利,那么在大多数情况下,对很多概念或者说词语对应的向量而言,“日本”和“意大利”这两个概念对应的值都是零,也就是说它们对于某个特定概念而言都不存在。如果这个假说是正确的,那么我们就可以在一个低维度的空间里编码出这个空间维度容量的概念。
同样地,当我们讨论神经元时,可以表达的概念数量也可以远超神经元的数量。
这个假说还引出了一个更重要的推论:神经网络中不仅是 representation 是这样的,computation 可能也是,包括神经元之间的所有连接。所以从某种意义上说,我们观察到的神经网络可能只是某个更大的、更稀疏的神经网络的”投影”。
所以叠加(Superposition hypothesis) 的极端是,某种意义上真的存在一个“上层模型”,在那里神经元是真正稀疏的,所有神经元之间都是可解释的,它们之间的权重构成了真正稀疏的电路。这才是我们真正要研究的对象。而我们现在观察到的只是这个对象投射出的影子,我们需要找到这个原始对象。
Lex Fridman:所以学习的过程就像是尝试对这个上层的理想状态下的模型进行压缩,并且不要丢失太多原始模型中的信息?
Chris Olah:是的,寻找如何有效拟合或者类似的路径,梯度下降做的就是这件事,这意味着,梯度下降所做的看似只是在优化一个密集的神经网络,但它实际上也在地搜索那些可以被投影到现在这个低维空间的极度稀疏的模型。而这也就解释了目前为什么会有大量研究在探索稀疏神经网络,尝试设计出 edges 和 activations 都稀疏的神经网络。
这些研究从理论上看非常合理,但实际效果并不理想,其中一个可能的原因是:神经网络在某种意义上已经是稀疏的了。人们想要实现某种稀疏化,但实际上梯度下降在背后已经比你能做的更高效地搜索了稀疏模型的空间,并学习到了最高效的稀疏模型。然后,它还找到了如何巧妙地将这个模型压缩下来,使其能在 GPU 上通过密集矩阵乘法进行高效运算,这个效果难以超越。
Lex Fridman:一个神经网络最多能塞进多少个概念?
Chris Olah:取决于概念(对应的向量的)的稀疏程度。概念的上限取决于参数的数量,因为我们需要权重参数来连接这些概念,而这就构成了一个上限。
压缩感知理论和 Johnson-Lindenstrauss 定理给了我们一些很有参考价值的理论研究成果。这些理论告诉我们:当你在一个向量空间中想要构造近似正交的向量时(这正是我们这里需要的),你不必追求概念或特征之间的严格正交。换句话说,我们可以放松要求,只需要概念之间“差不多正交”就行,也就是让它们之间的干扰保持在较小的范围内即可。
一旦我们设定了可以接受的余弦相似度阈值,那么可表示的概念数量实际上会随神经元数量呈指数增长。所以,在某种程度上,神经元数量可能都不是限制因素了。这方面已经有一些还不错理论结果,实际情况可能比这更好。因为理论假设情况下,任意特征都可能被随机激活,但在实际中,特征之间是有某种相关结构的,所以有一些特征更可能同时出现,而另一些则不太可能同时出现。因此,我认为神经网络在压缩这些特征上表现得更好,以至于容量可能根本不是限制因素。
Lex Fridman:polysemanticity(多语义性)问题在这里是如何体现的?
Chris Olah:多义性是我们观察到的这样一种现象:当我们观察很多个神经元时,发现单个神经元并不是仅仅表示一个概念,相反,它会对一系列不相关的事物产生响应。而叠加性可以被看作是解释多义性现象的一个假说。换句话说,多义性是一个被观察到的现象,而叠加性则是一个可以解释多义性及其他相关现象的理论假说。
Lex Fridman:这些现象的存在都让机制可解释性的研究变得更加困难。
Chris Olah:是的。如果我们试图从单个神经元的角度去理解事物,而这些神经元又具有多义性,就会遇到问题。如果再考虑到 weights,即假设有 2 个神经元都是多语义的,每个神经元可能会对 3 个不同的特定概念起反应,并且这两个神经元之间还存在一个 weight 连接,是不是就意味着可能会产生 9 种不同的交互结果?
这确实很奇怪,但还有一个更深层的原因,这与神经网络在高维空间中运作的事实有关。我之前说过,我们的目标是理解神经网络和它的运作机制。
有人可能会认为其实就是理解一个数学函数、并不难。我在早期做过的项目之一就是研究的是把二维空间映射到二维空间的神经网络。那个时候我们还可以用一种很直观的方式来理解这种神经网络,因为它的原理很像 bending manifolds(弯曲流形),为什么我们不能把这种方法推广到更复杂的网络呢?这是因为进入更高维的空间时,空间的体积会随着输入维度的增加呈指数级增长,所以很难去可视化这个空间。
因此我们需要用某种方式把这个问题拆分开来,要把这个指数级的空间分解成一些可拿来独立研究的东西,这些独立的部分中的维度数量不能是指数级的。
这里的“独立”非常关键,因为只有独立性才能让我们避免考虑所有指数级的组合情况, 而单义性、具有明确含义的特征,正是让我们能够独立思考这些部分的关键。这就是我们需要可解释的、单义特征( features)的根本原因。
Lex Fridman:你最近的研究目标就是:如何从一个多义 features、以及由这些复杂 feature 构成的神经网络中,提取出单义的 features?
Chris Olah:是的,我们观测到了一些多义神经元,如果假设认为这是叠加性理论在起作用,那么实际上有一个已经被广泛认可的技术可以处理这个问题,这就是字典学习(dictionary learning)。
如果我们用到稀疏自编码器这种很高效的、规范化的方式使用字典学习的路径的话,就会有一些可解释性的特征(features)出现,这些特征在之前是看不到的。这也是是对线性表示和叠加理论的一个重要验证。
这就回到了我们之前说的观点:我们不做任何预设。梯度下降比我们更聪明,所以我们不去预设可能存在的结果。
04.
Towards Monosemanticity
Lex Fridman:你和团队去年发表了一篇 Towards Monosemanticity,这篇研究的核心发现是什么?
Chris Olah:Towards Monosemanticity 确实算是我们使用稀疏自编码器(sparse autoencoders)以来取得的第一个真正的成功。尽管我们使用的是一个单层模型,但如果我们用字典学习训练它,我们可以得到很多高质量的、可解释的 features。典型的例子是阿拉伯语 features、希伯来语 features、Base64 features,这些例子经过深入研究都证实了我们的预期。有一个有意思的现象是,如果我们训练两个不同的模型,或者把同一个模型训练两次、都进行字典学习的话,两个模型中会存在一些共性的特征。所以这个实验确实是很有意思的,我们发现了各式各样的特征。不过这也仅仅证明了这个方法是有效的。必须要提到的还有一点是 Cunningham 团队在同一时期也有非常相似的研究结果。
现在回头看,有段时间我一度认为所有机制可解释性的研究最终会全部指向一个结论,就是“解释(nterpolate)”太难了,完全不可行。我们完全有理由认为,因为存在叠加性的这样我们无法处理的问题,所以可解释性研究就是很难。但事实并非如此,只需要一个很简单的技术就够了。
Lex Fridman:能不能展开说说这种研究方法最终得出的究竟是什么样的特征(features) ?
Chris Olah:取决于研究的模型。模型规模越大,提取到的 features 就越复杂。单层模型中最常见的 features 是编程语言和自然语言。语言相关的很多 features 是关联到具体上下文中的特定词,比方说“the”这个字眼。
理解这件事的关键在于,我们要很明确知道,the 的后面很可能会跟着一个名词,这个就是 the 作为一个 feature 本身所代表的意义。这些特征会在不同的上下文中被触发,比如在法律文档中和数学文档中就不一样,举个例子,在数学上下文中,当出现 the 时,模型可能会预测 vector(向量)或者 matrix(矩阵)这些数学词汇,而在其他上下文中则会预测其他词,这是很常见的现象。
Lex Fridman:这个过程也是基于人类的认知来给研究观察出来的特性贴标签、分类?
Chris Olah:是的,这种方法所做的其实就是帮助我们把在神经网络中观测到的特征“展开”。因为序列化(serialization)是把一切都折叠到了一起,我们根本看不清楚。所以需要先展开,但即使展开后,仍然要面对着一个非常复杂的东西,所以还需要做大量工作来理解这些特征是什么。
即使在这个单层模型中,关于 Unicode 的处理也有一些很有趣的现象。因为有些语言是用 Unicode 编码的,而tokenizer 并不一定会为每个 Unicode 字符都分配一个专门的 token。所以相反,你会看到这样的模式:交替的词符,每个词符代表一个 Unicode 字符的一半。”
我们会看到有不同的特征在相对的位置上被激活,就好像是在说:“好,我刚刚完成了一个字符,现在我需要去预测下一个前缀,然后当我预测完了下一个前缀,又需要另一个特征在识别到前缀后预测一个合理的后缀。”这样就会产生一个交替预测的循环,所以这些交替层模型真的很有趣。
还有一点,我们可能会下意识的认为只存在一种 Base64 特征,但事实证明有很多种 Base64 特征。被英文文本编码成的 Base64 与普通的 Bas64 编码有着完全不同的分布特征。还有一些与分词有关的特性也可以被模型利用。
Lex Fridman:打标的任务难吗?这个过程能够使用 AI 来实现自动化?
Chris Olah:这要看具体的特征内容,也取决于我们对 AI 的信任程度。现在有许多关于自动化可解释性的研工作,我觉得这也是一个很值得投入的方向,我们团队自己其实也做了不少自动化可解释性的工作,比如让 Claude 去标注我们发现的这些特征。
但 AI 经常会只点出一些非常笼统的概念,虽然在一定程度上当然是对的,但是又其实没有真正抓住核心,这个问题很普遍。
我个人对于自动化的可解释性其实还是存疑的,部分原因是我希望是人类来理解神经网络。如果是神经网络在帮人们理解它自己,可能会有点奇怪,类似于有些数学家讨论的,“如果是计算机自动证明的,那就不算数”,因为他们无法理解它。
这里还涉及到了一个信任的问题,“when you’re writing a computer program, you have to trust your compiler(当你在写程序时,你必须信任你的编译器)”。
如果编译器里有恶意软件,它就可能会把恶意软件注入到下一个编译器中,就会很麻烦。同样,如果使用神经网络来验证其他神经网络的安全性,就需要考虑这个用来验证的神经网络的安全问题,我们需要担心它是否在某种方式上欺骗人类。我认为现在这还不是一个大问题,但从长远来看,这个问题很重要。
05.
可解释性机制里有 scaling law 吗?
Lex Fridman:你们在今年 5 月发表了 Scaling Monosematicity ,在这篇论文中提出了 sparse autoencoder 和 monosematicity analysis 两个概念,如果要把它们应用到 Claude 3 Sonnet 上,需要什么样的条件?

Scaling Monosemanticity:Extracting Interpretable Features from Claude 3 Sonnet
Chris Olah:很多 GPU。
我们团队的 Tom Henighan 参与了最初的 scaling laws 的研究,他也从很早开始就一直在关注这样一个问题:可解释性机制是否也存在某种 scaling law?
所以当我们这项研究取得了成功、sparse autoencoders 开始运行以后,他立即开始关注如何扩展 sparse autoencoders 的规模,以及这与基础模型规模的扩展之间的关系。事实证明这是一个非常好的思路,我们可以借此预测,如果我们训练一个特定大小的 sparse autoencoders,应该训练多少 token 等等这些问题。
他的这个问题其实对我们 scale up 我们的研究起到很大的作用,让我们更容易的去训练真正的大型 sparse autoencoders。因为我们还不是在训练大模型,但训练这些真正的大型 sparse autoencoders 的成本也已经开始变得非常高了。
Lex Fridman:还需要考虑到怎么把一系列的工作任务分配到大量的 CPU 集群上来执行?
Chris Olah:这个过程中肯定存在不小的工程挑战,所以有一个值得研究的问题就是我们怎么样高效地实现 scale?然后还需要大量的工程来实现这种 scaling up。所以挑战在于我们必须进行合理规划,我们必须仔细的考量很多因素。
总的来看我们的研究很成功。虽然可能有人会觉得,monosematicity analysis 和 sparse autoencoder 只在单层模型上有效,但单层模型是很特殊的。也许线性表示假设和叠加假设只能适用于理解单程模型,而不适用于理解更大的模型。
首先,Cunningham 的论文已经某种程度上解决了这个问题的一部分,并且证明事实并非如此。Scaling Monospecificity 这个研究的结果又提供了更重要的证据支持,表明即使是非常大的模型,比如当时作为我们生产工具之一的 Claude 3 Sonnet,这一类非常大的模型也可以用线性表征进行很好的解释,用它们进行字典学习的训练是非常有效的,随着我们掌握更多 features,我们能解释的内容也越来越多,这是很积极的信号。
现在我们还能够发现不少抽象特征,它们是多模态的,会对同一概念的图像和文本内容作出跨模态响应。
Lex Fridman:可以举几个关于抽象特征(feature)的例子吗?
Chris Olah:一个最典型的例子是我们发现了与代码安全相关的安全漏洞和后门代码的特征。这是两种不同的特征(features)。如果我们强制激活安全漏洞特征,那 Claude 就会开始在代码中写入像 buffer overflows 这样的安全漏洞,同时这个特征也会触发其他类型的安全漏洞的响应,比如 disable SSL 这种明显存在安全隐患的命令。
Lex Fridman:目前这个阶段,可能是这些因为具体的表现都以一种显而易见的方式呈现出来,所以模型可以做出有效的识别。但随着发展,模型可能会能够识别出更微妙的模式,比如欺骗或者 bug。
Chris Olah:好的,这里我想区分两个事情:一个是特征或概念本身的复杂性,另一个是我们所观察的例子的微妙程度。当我们展示数据集中的顶级例子时,这些都是能让该 fearture 最强烈激活的极端例子。这并不意味着它不会对更微妙的事物产生反应。比如那个不安全代码 feature,它最强烈反应的是那些明显的禁用安全类型的操作,但它也会对 buffer overflows 和更微妙的代码安全漏洞产生反应。这些特征都是多模态的。你可以问它’什么样的图片会激活这个特征?’结果发现,安全漏洞特征会对一些图片产生反应,比如人们在 Chrome 浏览器中点击继续访问 SSL 证书可能有问题的网站的图片。
另一个很有趣的例子是 Bacdoors 代码 feature,当你激活它时,Claude 会写入一个将数据转储到某个端口的 backdoor。但当你问’什么样的图片会激活后门 Bacdoors feature?’,结果是那些带有隐藏摄像头的设备的图片。显然有一整类人在销售看起来无害但装有隐藏摄像头的设备,他们的广告中就展示了这些隐藏的摄像头。这某种程度上可以说是 Backdoor 的物理版本。这展示了这些概念是多么抽象,我觉得这真的很…虽然我为存在这样一个销售这类设备的市场感到难过,但我对这个 feature 这种抽象并识别的能力感到惊喜。
Lex Fridman:AI 安全领域,是否存在和欺骗和说谎相关的特征 (features)?有没有一种方法可能能够检测模型中的说谎行为?因为随着模型变得越来越智能,一个潜在的重要威胁就是它可能会在自己的意图或其他方面欺骗操作它的人。
Chris Olah:这方面我们还处于早期,虽然我们确实发现了很多与欺骗和说谎相关的特征,其中一种就是会对人们的说谎和欺骗行为作出响应,如果我们强制激活它,Claude 就会开始对我们说谎,所以肯定存在一个欺骗特征。还有其他的一些类似的 features,比如隐瞒信息和不回答问题的 feature,关于追求权力的 feature 等。如果我们强制激活这些 feature,Claude 就会作出一些我们并不想看到的反馈。
06.
机制可解释性研究的新方向
Lex Fridman:在机制可解释性领域,接下来有哪些会有哪些新的方向值得关注?
Chris Olah:值得关注的研究内容很多。
首先,我希望我们不仅可以理解 features,还可以用它们来理解模型的计算过程,对我来说才是整个研究的最终极目标。我们已经发表了一部分研究成果,但我认为这些研究仍然比较边缘,我们仍然有非常多的工作要做。这些工作与我们称之为 interference weights 的挑战有关:由于叠加(superpositon)的存在,如果我们只是简单的观察 features 之间的连接关系,可能会发现一些在上层模型中并不存在的 weights,而这些只是 superstition 产生的假象。这是一个技术性挑战。
但我们可以把 sparse autoencoders 想象成一个望远镜,它让我们观测到所有这些外部的 features,随着我们构建起越来越强大的 sparse autoencoders,在字典学习方面做的越来越好,我们就能够看到越来越多的“星星”,能够放大观察越来越小的“星星”。有大量证据表明我们现在所看到的仍然只是“星星”中非常小的一部分。在我们的人工神经网络宇宙中,可能还存在许多我们现阶段无法观察到的现象,可能我们永远也无法制造出足够精细的工具来观测他们,也可能有些现象根本无法从计算这个位阶上实现对他们的观察。这就像是早期天文学时期的“暗物质”,当时我们不清楚这些无法解释的物质是什么。我经常思考这些“暗物质”,试图弄清楚我们是否能够观测到它,如果我们无法观察到它,如果人工神经网络中有相对方一大部分对我们来说是不可访问的信息,这对安全而言又意味着什么。
另外一个我一直关心的问题是,机制可解释性实际上是一种非常微观的研究方法,这种方法希望以颗粒度极小的方式理解事物,但我们关注的许多问题实际停留在宏观层面,比如我们关注人工神经网络的行为问题,还有其他很多值得关注的相对宏观的问题。
虽然微观研究方法的优势在于准确性容易得到验证,但也有很明显的缺点——离我们真正关注的问题比较远,所以这二者之间的鸿沟是我们接下来需要努力的方向。那么问题来了:我们能否在一个更高的位阶上理解人工神经网络,能否从目前研究的这一层位阶上升到下一个更高的位阶?
Lex Fridman:你之前用“器官问题(Organ Questions)”做过类比:我们把可解析性研究视为对人工神经网络的一种解剖学研究,那么大多数研究都聚焦在微小的血管上,观察较小的单位和单个神经元及其连接方式。但很多问题是无法通过在较小单位上的研究得到回答的。如果看生物解剖学研究,它们最终会发现器官层面有心脏这样的单一器官、系统层面有呼吸系统这种人体的生物系统之一这样的抽象结论。所以大家现在想要试图理解的事情在于,人工神经网络是否也存在某种重要器官或系统?
Chris Olah:是这样的,很多自然科学领域的研究,都在不同的抽象位面上研究事物。生物学领域,我们可以看到分子这个位面上,分子生物学研究的可能是蛋白质和分子结构等,而到了细胞这一层则有专门的细胞生物学等等,当中有很多概念层级。
而我们现阶段进行的机制可解释性研究有点像是人工神经网络上的微生物学,但我们更想要的是类似解剖学的一种研究方向。那你可能想问:“为啥不直接在解剖学的这一层进行研究呢?”,我想我对这个问题的回答是因为有 superstition 的存在。如果不通过正确的当时分解微观结构,并研究微观结构彼此之间如何连接在一起,我们很难看到真正的宏观结构。但我希望会有比特征(features) 和电路(circuits) 更大的东西,这样我们就可以在一个更大的结构找到重要的一小部分具体研究。














暂无评论内容