1. Mini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities
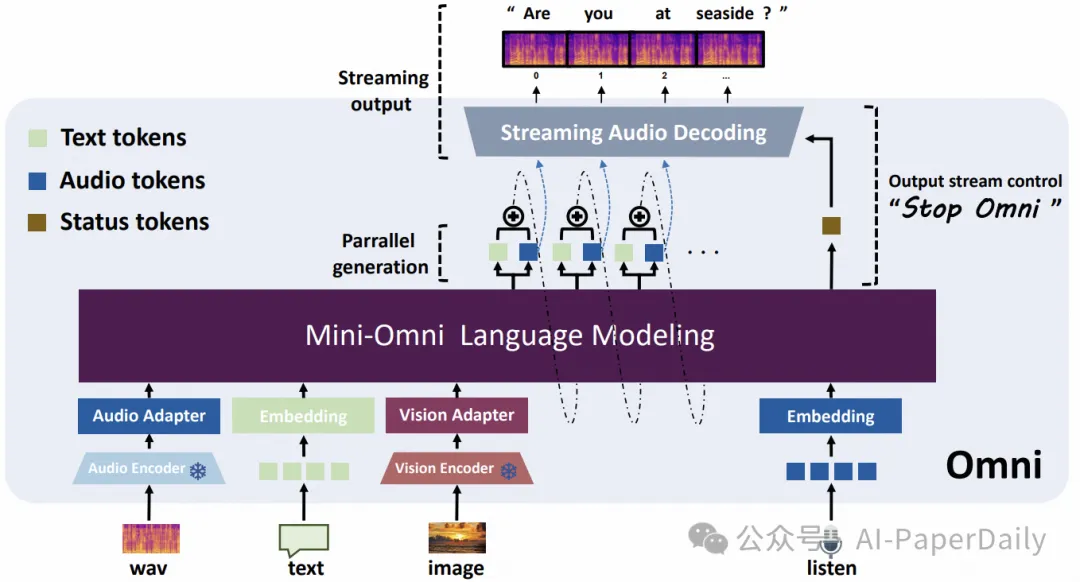
GPT-4o是一个全能模型,代表了多模态语言模型发展的里程碑。它能够理解视觉、听觉和文本模态,直接输出音频,并支持灵活的双向交互。开源社区中的许多模型通常能够实现GPT-4o的一些功能,如视觉理解和语音聊天。然而,由于多模态数据的复杂性、复杂的模型架构和训练过程,训练一个包含所有模态的统一模型是具有挑战性的。在本文中,我们提出了视觉-音频助手Mini-Omni2,它能够对视觉和音频查询提供实时、端到端的语音响应。通过集成预训练的视觉和听觉编码器,Mini-Omni2在各个模态上保持了良好的性能。我们提出了一种三阶段训练过程来对齐模态,使得语言模型在有限的数据集上训练后能够处理多模态输入和输出。据我们所知,Mini-Omni2是与GPT-4o最接近的复现之一,具有相似的功能形式。
2. DAWN: Dynamic Frame Avatar with Non-autoregressive Diffusion Framework for Talking Head Video Generation
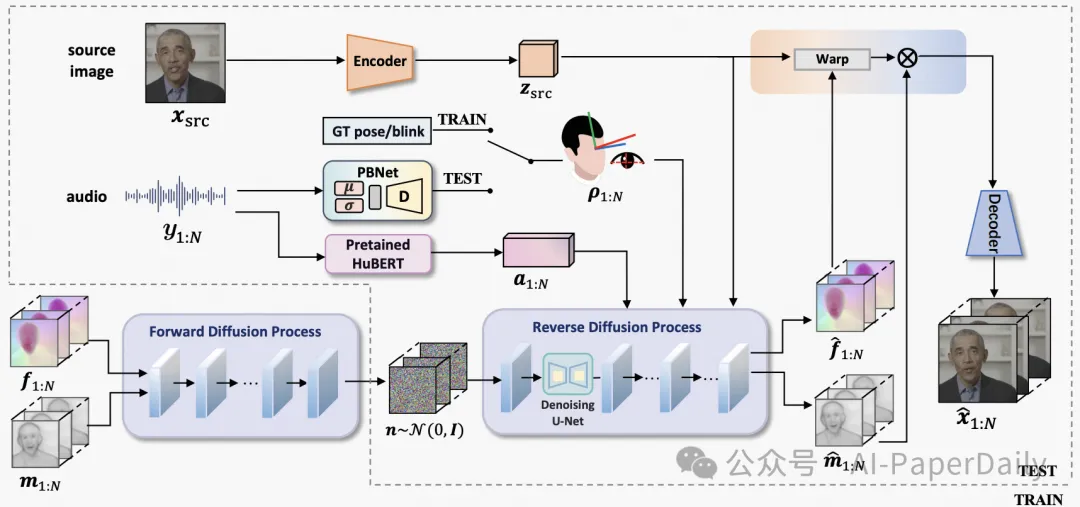
数字人生成旨在从单张肖像和语音音频中生成生动逼真的数字人视频。尽管基于扩散的数字人生成取得了显著进展,但几乎所有方法都依赖于自回归策略,这些策略在当前生成步骤之外的上下文利用有限,容易累积错误,并且生成速度较慢。为了解决这些挑战,我们提出了DAWN(动态帧Avatar与非自回归扩散)框架,该框架能够一次性生成动态长度的视频序列。具体而言,它由两个主要组件组成:(1)音频驱动的整体面部动态生成在潜在运动空间,以及(2)音频驱动的头部姿态和眨眼生成。大量实验表明,我们的方法生成了真实且生动的视频,具有精确的嘴唇动作和自然的眨眼。此外,DAWN具有快速的生成速度,具备强大的外推能力,确保稳定生成高质量长视频。这些结果展示了DAWN在生成数字人视频方面的巨大潜力和影响。此外,我们希望DAWN能够激发对扩散模型中非自回归方法进一步探索的兴趣。
论文: https://arxiv.org/pdf/2410.13726
3. Are AI Detectors Good Enough? A Survey on Quality of Datasets With Machine-Generated Texts

自回归大型语言模型(LLMs)的快速发展显著提高了生成文本的质量,从而需要可靠的机器生成文本检测器。大量的检测器和AI片段集合已经涌现,其中一些检测方法甚至在目标指标上的识别质量达到了99.9%。然而,在实际应用中,这些检测器的质量往往会大幅下降,这引发了一个问题:这些检测器是否真的非常可信,还是它们的高基准分数来自于评价数据集的质量较差?在本文中,我们提出了需要稳健且高质量的方法来评估生成数据,以防止偏见并提高未来模型的泛化能力。我们对专门用于AI生成内容检测的竞赛数据集进行了系统性审查,并提出了评估包含AI生成片段的数据集质量的方法。此外,我们讨论了使用高质量生成数据实现两个目标的可能性:提高检测模型的训练质量和提高训练数据集本身的质量。我们的贡献旨在促进对人类和机器文本之间动态关系的更好理解,最终支持在日益自动化的世界中信息的完整性。
4. DPLM-2: A Multimodal Diffusion Protein Language Model
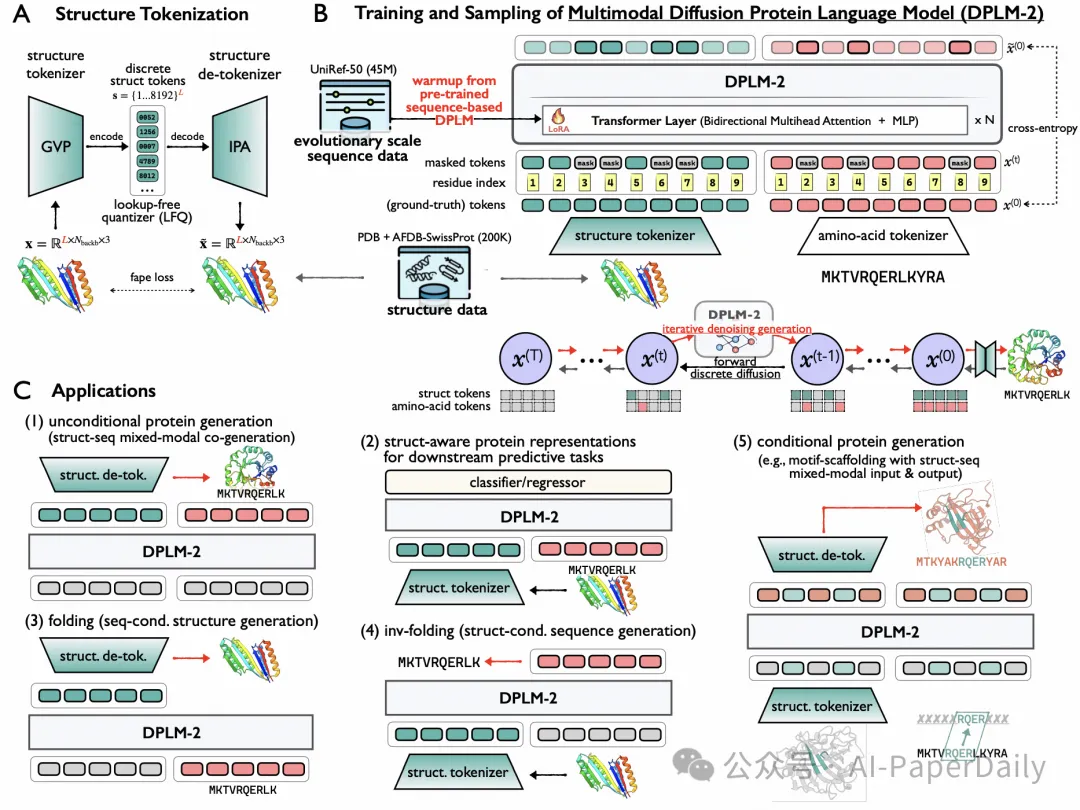
蛋白质是定义为其氨基酸序列的一种大分子,这些序列决定了它们的三维结构,进而决定了所有生物体中的功能。因此,生成性蛋白质建模需要多模态方法,同时建模、理解和生成序列和结构。然而,现有方法通常使用各自独立的模型来处理每种模态,限制了它们捕捉序列和结构之间复杂关系的能力。这导致在需要联合理解和生成两种模态的任务中表现不佳。在本文中,我们提出了一种多模态蛋白质基础模型——DPLM-2,它扩展了离散扩散蛋白质语言模型(DPLM),以同时容纳序列和结构。为了使语言模型能够进行结构学习,三维坐标通过无查找表的基于量化标记的分词器转换为离散标记。通过同时使用实验性和高质量合成结构进行训练,DPLM-2学习了序列和结构的联合分布以及它们的边缘分布和条件分布。我们还实现了一种高效的预热策略,以利用大规模进化数据与预训练序列基础蛋白质语言模型的结构归纳偏差之间的联系。实证评估表明,DPLM-2可以同时生成高度兼容的氨基酸序列及其相应的三维结构,消除两阶段生成方法的需要。此外,DPLM-2在各种条件生成任务中表现出竞争力,包括折叠、逆折叠和使用多模态motif输入的支架生成,以及为预测任务提供结构感知表示。
5. HART: Efficient Visual Generation with Hybrid Autoregressive Transformer

我们提出了Hybrid Autoregressive Transformer(HART),这是一种自回归(AR)视觉生成模型,能够直接生成1024×1024的图像,并在图像生成质量上与扩散模型相媲美。现有的AR模型由于其离散分词器的图像重建质量差以及生成1024像素图像的高昂训练成本而受限。为了解决这些挑战,我们提出了混合分词器,它将自编码器的连续潜在变量分解为两个部分:由离散标记表示的大图景和由连续标记表示的残差部分。离散部分通过可扩展分辨率的离散AR模型建模,而连续部分则通过仅包含37M参数的轻量级残差扩散模块学习。与仅包含离散标记的VAR分词器相比,我们的混合方法在MJHQ-30K上的重建FID从2.11提高到0.30,生成FID提高了31%,从7.85降低到5.38。HART在FID和CLIP得分上也优于最先进的扩散模型,在FID和CLIP得分上表现更优,吞吐量提高了4.5-7.7倍,MACs降低了6.9-13.4倍。














暂无评论内容