前言
OpenAI 最近推出了开创性的 o1 模型,以其卓越的推理能力而闻名。该模型在 AIME 和 CodeForces 等平台上表现出色,超越了其他领先模型。受此成功的启发,阿里研究团队旨在进一步拓展大型语言模型 (LLM) 的边界,增强其推理能力,以应对复杂的现实世界挑战,开源了Marco-o1推理模型。
Marco-o1更加重视开放式问题的解决,目标是解决这个问题:“o1模型能否有效地推广到缺乏明确标准且奖励难以量化的更广泛领域?”
Marco-o1 通过思维链 (CoT) 微调、蒙特卡罗树搜索 (MCTS)、反思机制和创新的推理策略提供支持——这些策略经过优化,适用于复杂的现实世界问题解决任务。
论文主要特点
- 使用CoT数据进行微调:通过在基础模型上进行全参数微调,开发了Marco-o1-CoT。这一过程结合了开源的CoT数据集和自主开发的合成数据,显著提升了模型的推理能力。
- 通过MCTS扩展解空间:将大型语言模型(LLMs)与蒙特卡洛树搜索(MCTS)相结合,形成了Marco-o1-MCTS。通过利用模型的输出置信度来指导搜索过程,成功扩展了模型的解空间,使其在复杂问题上的表现更为出色。
- 推理行动策略:实施了新颖的推理行动策略和反思机制(Marco-o1-MCTS mini-step)。这包括在MCTS框架内探索不同的行动粒度,并提示模型进行自我反思,从而显著增强了模型解决复杂问题的能力。
- 在翻译任务中的应用:首次将大型推理模型(LRM)应用于机器翻译任务,探索了多语言和翻译领域的推理时间缩放规律。这一创新为机器翻译领域带来了新的视角和方法。
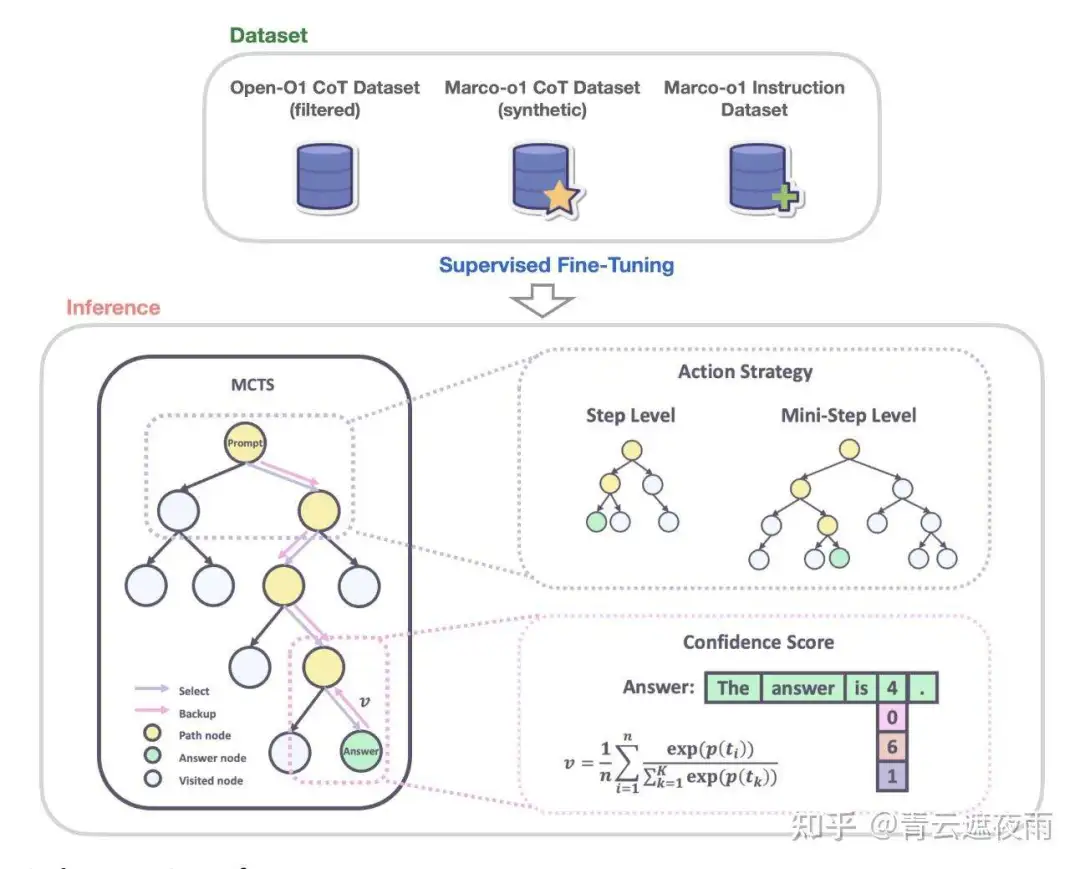
CoT数据微调
为了增强Marco-o1模型的复杂推理能力,首先要使用CoT数据对其进行微调,使用如表格所示的多种数据集的监督微调(SFT)策略。

Open-O1 CoT Dataset (Filtered):该数据集是基于Open-O1项目的CoT(Chain of Thought)数据集经过精炼和过滤后的版本。团队通过应用启发式和质量过滤过程,显著提升了数据集的质量。这种改进使得模型能够更有效地采用结构化的推理模式,从而在复杂任务中表现更为出色。- Marco-o1 CoT Dataset (Synthetic):该数据集是通过蒙特卡洛树搜索(MCTS)生成的合成数据集。MCTS的使用帮助模型构建了复杂的推理路径,进一步增强了模型的推理能力。这种合成数据集的引入,使得模型在处理复杂问题时能够展现出更为深入和全面的思考能力。
- Marco Instruction Dataset:该数据集专注于指令跟随能力,这是执行复杂任务的关键要素。团队认识到,强大的指令跟随能力对于模型在广泛任务中的表现至关重要。因此,他们整合了一组指令跟随数据,确保模型在各种任务中保持高效和通用性,同时显著提升了其推理能力。
通过 MCTS 扩展解决方案空间
什么是蒙特卡洛树搜索(MCTS)?
蒙特卡洛树搜索算法最近在文本规划和AutoCoT领域大放光彩,在EMNLP2023《Prompt-Based Monte-Carlo Tree Search for Goal-oriented Dialogue Policy Planning》一文中首先被用于与大模型的结合,首先我们先来具体解释下什么是蒙特卡洛树搜索算法。
蒙特卡洛树搜索(Monte Carlo Tree Search)是一种用于决策过程的启发式搜索算法,特别适用于具有巨大搜索空间的游戏和问题,例如围棋、国际象棋和复杂的组合优化问题。MCTS 通过在决策树中进行随机模拟(也称为蒙特卡罗模拟),逐步构建搜索树,从而找到最优的决策路径。

核心概念
MCTS 的核心思想是通过在决策树上进行大量的随机模拟,来估计各个节点的价值,从而指导搜索过程。它主要由以下四个步骤组成,每次迭代都会重复这四个步骤:
- 选择(Selection):从根节点开始,根据某种策略(如上置信区间 UCB),选择一个子节点,直到到达一个尚未被完全展开的节点。
- 扩展(Expansion):如果选中的节点不是终止节点,从该节点中随机选择一个未被访问过的子节点,添加到搜索树中。
- 模拟(Simulation):从新添加的节点开始,进行一次随机的模拟(也称为“Playout”),直到到达终止状态(如游戏结束)。
- 回溯更新(Backpropagation):将模拟结果(如胜利或失败)沿着路径反向传播,更新各个节点的统计信息(如胜率、访问次数)。
关键组件
- 选择策略:在选择步骤中,常用的策略是上置信区间应用于树(Upper Confidence Bounds applied to Trees,UCT)。UCT 平衡了探索(选择访问次数少的节点)和利用(选择具有高胜率的节点)。
其中, 是节点 的获胜次数, 是节点 的访问次数, 是父节点的访问次数, 是探索参数。例如,如果从某个节点 出发的模拟结果是正的(例如赢得了游戏或者完成了正确的推理),那么 就会增加1,而 也会加 1。
- 模拟策略:通常是随机的,也可以使用启发式或领域特定的知识来改进模拟的质量。
- 回溯更新:在回溯过程中,更新节点的胜率和访问次数,以反映最新的模拟结果。
如何将MCTS与CoT结合起来扩展思维链路径?
在Marco-o1中:

作为推理状态的节点:在MCTS框架中,每个节点代表问题解决过程的推理状态。
动作作为 LLM 输出:从某个节点出发的可能动作是由 LLM 生成的输出,这些输出表示推理链中的潜在步骤或小步骤。
回合模拟与奖励计算:在回合模拟阶段,LLM 继续推理过程直至到达终止状态。
指导 MCTS:这个奖励分数 用于评估并选择 MCTS 中有前途的路径,有效地引导搜索走向更加自信和可靠的推理链。
通过计算置信度得分获取每个状态的值
在执行rollout期间,为每个生成的token ,通过softmax函数计算其置信度得分。置信度得分基于当前token的对数概率以及前五个备选token的对数概率,公式如下:
其中:
- 表示rollout中第 个token的置信度得分。
- 是由LLM生成的第 个token的对数概率。
- (其中 到 )是第 步中前五个预测token的对数概率。
- n表示rollout序列中的token总数。
该公式确保置信度得分反映了当前选择的token相对于前五个备选token的相对概率,有效地将分数归一化到0和1之间。
计算总体奖励得分
在获取rollout序列中所有token的置信度得分后,计算这些得分的平均值以获得总体奖励得分 :
其中:
- 是rollout路径的总体奖励得分。
- 是rollout序列中的token总数。
- 是第 个token的置信度得分。
这个平均值作为奖励信号,用于评估rollout路径的推理质量。更高的 表示更高的置信度以及可能更准确的推理路径。
由论文内容推理MTCS和LLM的算法流程,具体来说:
在选择阶段,从根节点开始,沿着搜索树选择一个子节点,直到到达一个尚未完全展开的节点。节点的选择基于其累计奖励(置信度得分)和访问次数,优先选择奖励较高的路径。具体选择标准是从当前节点出发的推理步骤中,挑选出奖励分数 较高的节点,即具有较高累计置信度的路径。
在扩展阶段,在选择阶段到达一个尚未完全展开的节点后,将其子节点扩展到搜索树中。从当前节点输入 LLM,生成潜在的下一步推理输出,这些输出被作为新节点添加到搜索树。生成的子节点代表不同的推理方向(例如下一步的逻辑步骤或不同的解法路径)。扩展过程通常生成多个候选输出,例如基于 LLM 前 5 个置信度最高的候选 token,从而捕获可能的推理分支。
在模拟阶段,从扩展的节点开始,模拟整个推理路径,直到达到终止状态。模拟由 LLM 完成,执行一个完整的推理链展开。在每一步中,LLM生成的 token 置信度通过 softmax 计算得出。整个模拟路径的总体奖励 v 是所有 token 置信度得分的平均值。模拟结束的条件可以是推理链完成、达到预设长度或模型预测的终止标记。
在回溯更新阶段,将模拟结果(奖励 )沿路径从当前节点反向传播,更新父节点及祖先节点的统计信息。每个节点更新其累计奖励和访问次数:奖励: ,访问次数: 。奖励值 是 roll-out 路径的置信度得分的平均值,表示路径推理质量。回溯更新确保整个搜索树能够动态调整,未来的搜索倾向于奖励较高的路径。
推理动作策略
动作选择
研究者观察到,以动作作为蒙特卡洛树搜索(MCTS)的粒度较为粗糙,这种方式往往导致模型忽视解决复杂问题所需的关键推理路径。为了解决这一问题,研究者尝试了不同粒度的搜索单元。起初,研究者使用完整的“步骤”作为搜索的基本单位。随后,为了进一步扩展模型的搜索空间并提升其解决问题的能力,研究者尝试将步骤细化为更小的单元,即每32或64个Token组成的“微步骤(mini-step)”。这种更细粒度的划分使模型能够以更高的精度探索推理路径。尽管在理论上,以Token级别为单位的搜索能够提供最大的灵活性和精细化,但由于计算资源的高昂需求以及构建有效奖励模型的难度,目前在实践中尚不可行。
在实验中,研究者在MCTS框架下实现了以下策略:
- 步骤(Step)作为动作(Action):允许模型生成完整的推理步骤作为动作,每个MCTS节点代表一个完整的思维过程或行动标签。这种方法在探索效率上具有优势,但可能忽略解决复杂问题时需要的更细粒度的推理路径。
- 微步骤(Mini-step)作为动作(Action):将32或64个Token作为一个微步骤的动作单元。这种更细的粒度扩大了问题解决的空间,通过在搜索过程中引入更多细微步骤,增强了模型应对复杂推理任务的能力。在这一粒度水平上探索解决方案空间,能够帮助模型发现以较大动作单元可能忽略的正确答案。
研究结果表明,采用更细粒度的MCTS搜索策略可以显著提升模型的推理能力,从而更有效地解决复杂问题。
反思机制
研究者引入了一种反思机制,通过在每次推理过程末尾添加短语“等等!也许我犯了一些错误!我需要从头开始重新思考。”来促使模型进行自我反思并重新评估推理步骤。这种机制显著提高了解题的准确性,特别是在原始模型初始错误解决的复杂问题上表现尤为突出。加入反思机制后,大约有一半此类困难问题能够被正确解决。
从自我批评的角度来看,这一方法使模型能够充当自己的批评者,从而识别推理中的潜在错误。通过明确提示模型质疑其初始结论,这一机制鼓励模型重新表达并优化其思维过程。自我批评机制充分利用了模型检测自身输出中不一致性或错误的能力,从而提升了解题的准确性和可靠性。
反思步骤作为一个内部反馈循环,有效增强了模型在没有外部干预情况下的自我纠错能力。这一机制不仅显著提升了模型解决复杂问题的能力,还强化了其解题的准确性和鲁棒性。
实验结果
MGSM 数据集(多语言小学数学问题)
基于Qwen2-7B-Instruct,使用自有训练数据进行了监督微调(SFT),生成了Marco-o1-CoT。将Marco-o1-CoT引入了蒙特卡洛树搜索(MCTS)框架,并根据动作的定义进行不同的设置,包括以下三种变体:
- Marco-o1-MCTS(步骤):将每一步推理(step)作为一个动作单元。
- Marco-o1-MCTS(64-token微步骤):将每64个Token组成的微步骤作为一个动作单元。
- Marco-o1-MCTS(32-token微步骤):将每32个Token组成的微步骤作为一个动作单元。
这些不同的粒度设置旨在探索更细化的推理路径,从而提升模型在复杂问题上的表现能力。
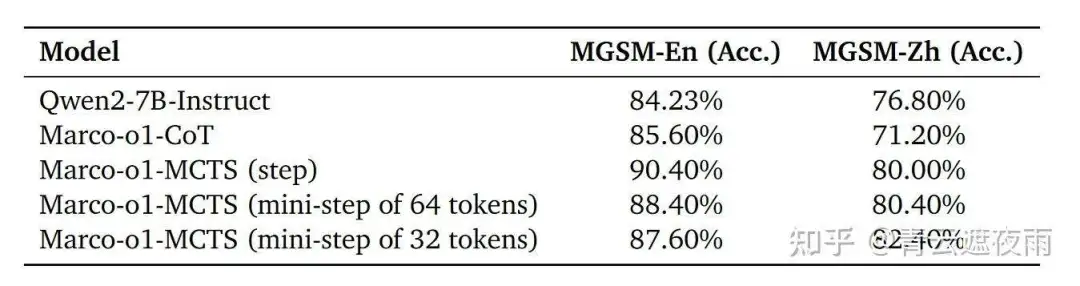
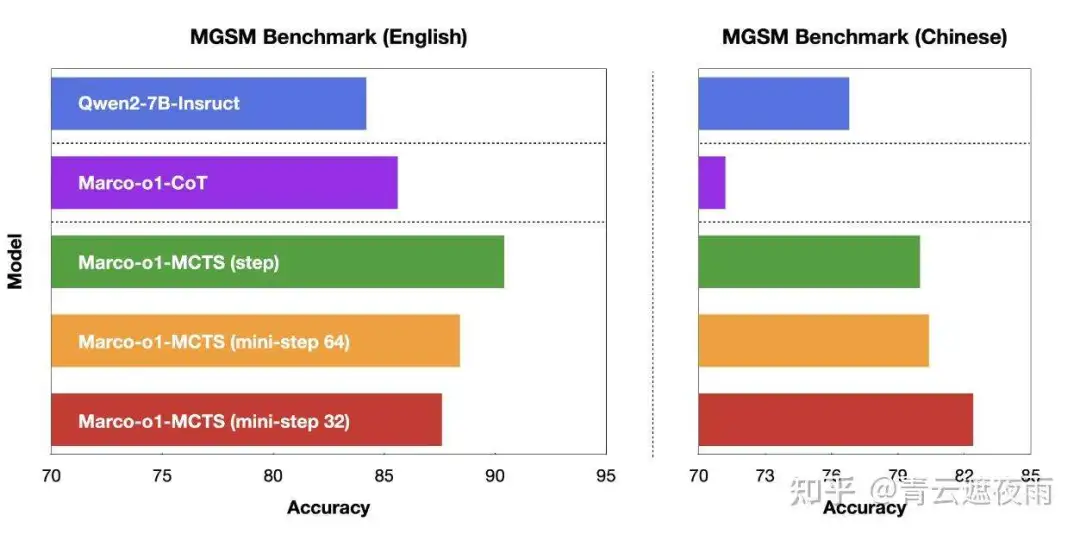
在MGSM-en数据集中,Marco-o1-CoT相较于Qwen2-7B-Instruct表现出明显优势。这种优势是预期中的,因为Marco-o1-CoT经过了带有英文CoT数据的微调。然而,在MGSM-zh数据集中,Marco-o1-CoT的表现相比Qwen2-7B-Instruct有所下降。这一性能下降归因于微调时使用的CoT数据为英文,而这种基于英文数据的微调效果在中文数据集上的迁移性能可能较弱。
具体举个例子:

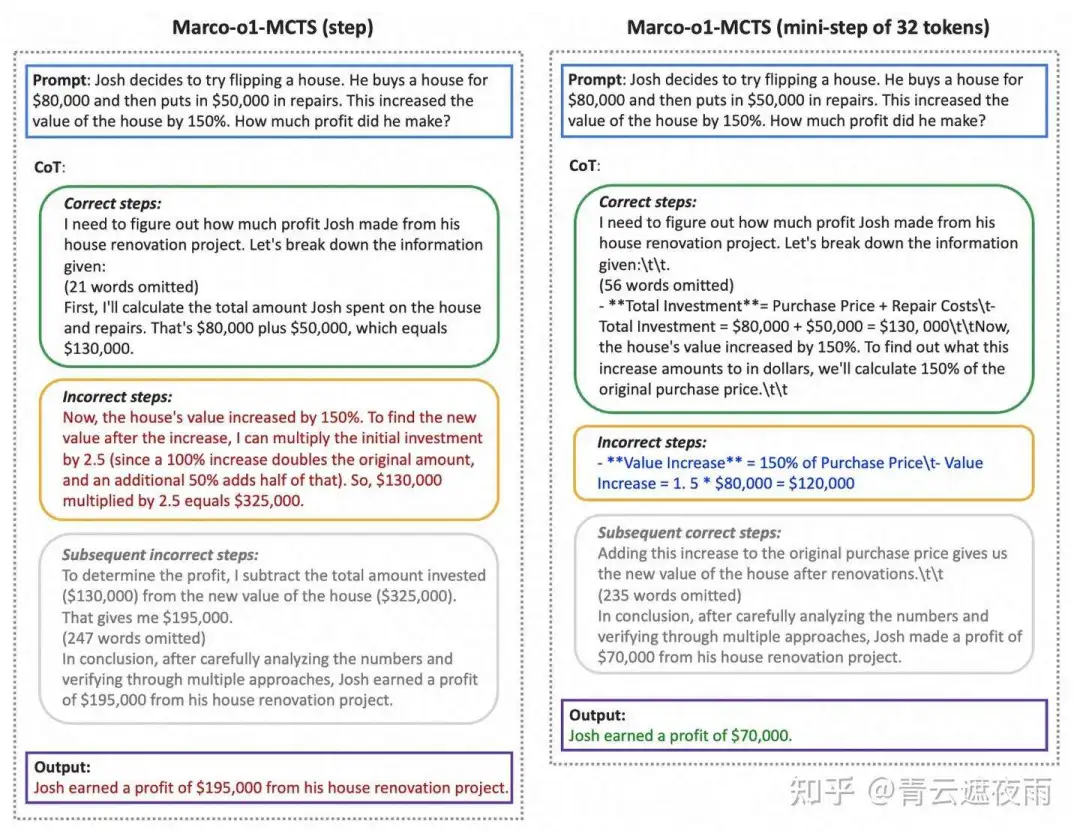
由例子可知,我们无法就哪种行动策略更优越得出明确的结论。
机器翻译
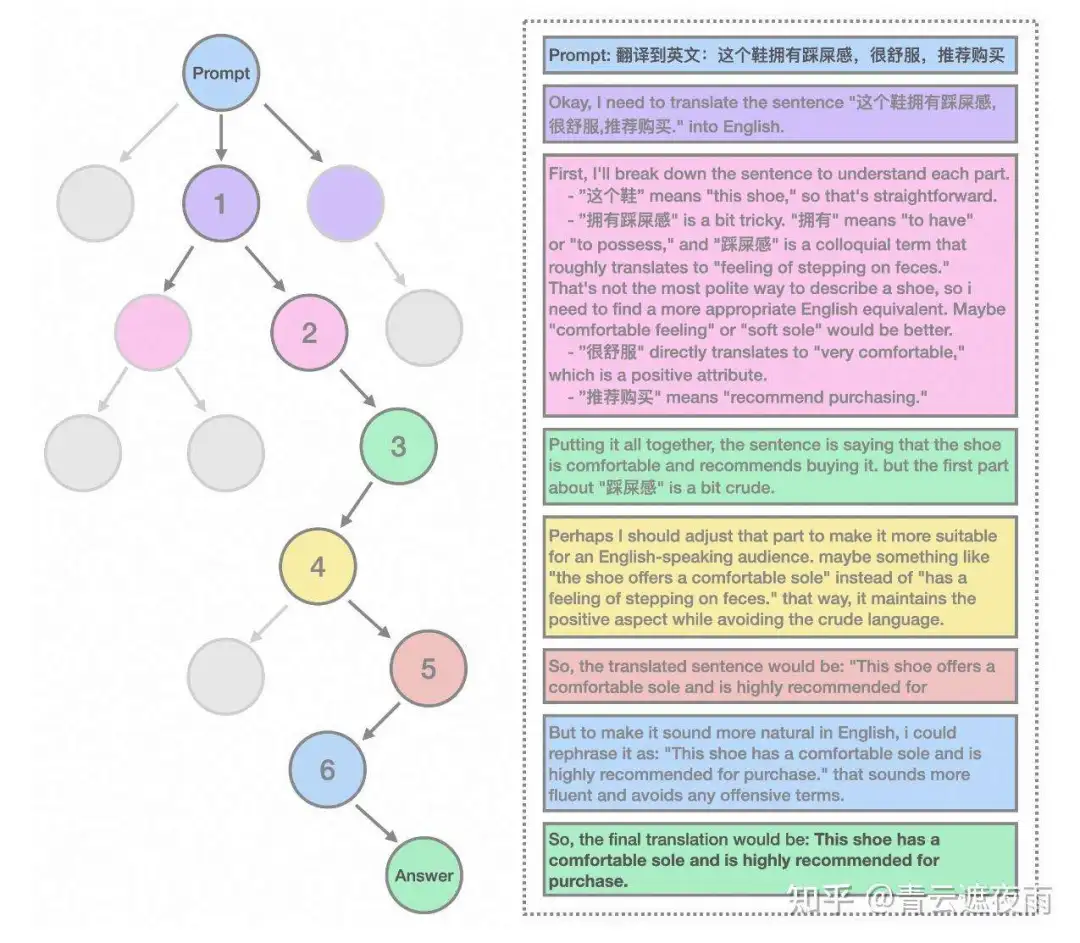
Marco-o1 展示了自己擅长理解上下文和细微差别,提供更准确、更自然的翻译。
















暂无评论内容