在当今数字化与智能化浪潮汹涌的时代,人工智能技术不断取得突破性进展,多模态模型作为其中的前沿领域,正日益成为研究和应用的热点。边缘设备,如智能手机、物联网设备等,对智能处理视觉和文本信息的需求也在急剧增长。然而,传统模型往往因参数规模庞大、计算复杂等问题,难以在边缘设备上高效运行。在此背景下,OmniVision – 968M模型应运而生,它以紧凑的架构、创新的技术设计,为边缘设备的多模态智能应用带来了新的曙光。
一、模型概述
OmniVision – 968M是一款由NexaAI研发的紧凑且高效的多模态模型,其参数规模小于10亿(968M),却具备强大的视觉和文本处理能力。该模型旨在解决边缘设备在运行多模态模型时面临的资源受限问题,通过优化架构和训练方法,实现了在保证性能的前提下,降低计算成本和延迟,从而为边缘设备的智能化升级提供了可行的解决方案。
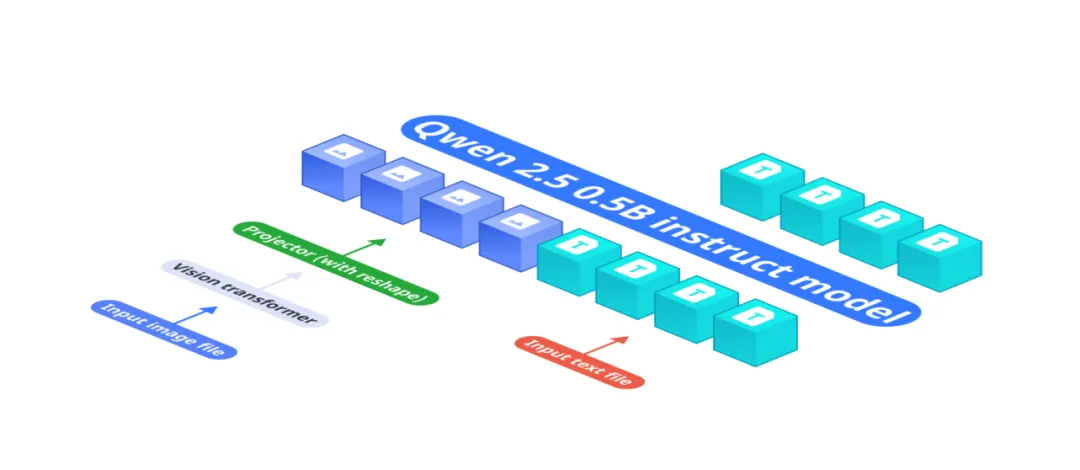
二、技术原理
1. 模型架构
基础组件协同:OmniVision – 968M的架构由三个关键部分组成。基础语言模型Qwen 2.5 – 0.5b – instruct负责处理文本输入,它具备丰富的语义理解能力,能够对输入的文本进行深入分析。视觉编码器Siglip – 400m则专注于图像信息的处理,以384分辨率和14×14的块大小生成图像嵌入,将图像转换为模型可理解的向量表示。多层感知器(MLP)作为投影层,起到了桥梁的作用,将视觉编码器生成的图像嵌入与基础语言模型的标记空间进行对齐,使模型能够实现端到端的视觉语言理解。
创新的投影设计:相较于传统的LLava架构,OmniVision – 968M的一大亮点是其独特的投影仪设计。它成功地将图像标记从729个大幅减少到81个,这一改进带来了显著的优势。通过减少图像标记数量,模型在处理图像时所需的计算资源和时间大大降低,有效缩短了延迟时间,提高了整体运行效率,从而使模型能够在边缘设备上更加流畅地运行,满足实时性要求较高的应用场景。
2. 训练流程优化
多阶段训练策略:OmniVision – 968M采用了精心设计的三阶段训练流程。在预训练阶段,模型专注于利用大量的图像 – 字幕对数据,建立起基本的视觉语言对齐关系。此时,仅解冻投影层参数,使模型能够学习到视觉和文本之间的初步关联。接着进入监督微调(SFT)阶段,借助基于图像的问答数据集,模型进一步增强对上下文的理解能力,通过对包含图像的结构化聊天历史记录进行训练,不断优化其对不同场景下视觉和文本信息综合处理的能力。
直接偏好优化(DPO)提升准确性:最后一个阶段是直接偏好优化(DPO)。在这个阶段,模型首先使用基础模型生成对图像的响应,然后由教师模型对这些响应进行最少编辑的更正,同时确保更正后的响应与原始响应在语义上高度相似。这些原始和更正后的输出形成选择 – 拒绝对,用于训练模型,使模型能够学习到更加准确和合理的输出方式,有效减少幻觉现象,显著提高模型输出的准确性和可靠性。
三、功能特点
1. 高效的图像 – 文本处理
OmniVision – 968M能够快速且准确地处理视觉和文本输入信息。无论是对图像中的物体识别、场景理解,还是对文本指令的解析、语义理解,模型都能高效完成,并将两者有机结合起来,提供全面而准确的处理结果。例如,当输入一张包含多种物体的图片和一个关于这些物体关系的问题时,模型能够迅速分析图片内容,理解问题含义,并给出合理的回答。
2. 低延迟与低资源需求
得益于其创新的架构设计,特别是图像标记的减少,OmniVision – 968M在边缘设备上运行时具有较低的延迟。这意味着在处理实时性要求较高的任务时,如实时视频分析、即时交互等,模型能够快速给出响应,提供流畅的用户体验。同时,模型对计算资源的需求相对较低,能够在资源受限的边缘设备上稳定运行,避免了因资源消耗过大而导致的设备卡顿或性能下降等问题。
3. 高准确性输出
通过使用来自可靠数据的直接偏好优化(DPO)训练,OmniVision – 968M有效减少了幻觉现象,大大提高了输出的准确性。在实际应用中,准确的输出对于决策支持、信息提供等任务至关重要。无论是在智能安防中对危险情况的判断,还是在智能家居中对用户指令的正确执行,模型的高准确性都能确保系统的可靠运行。
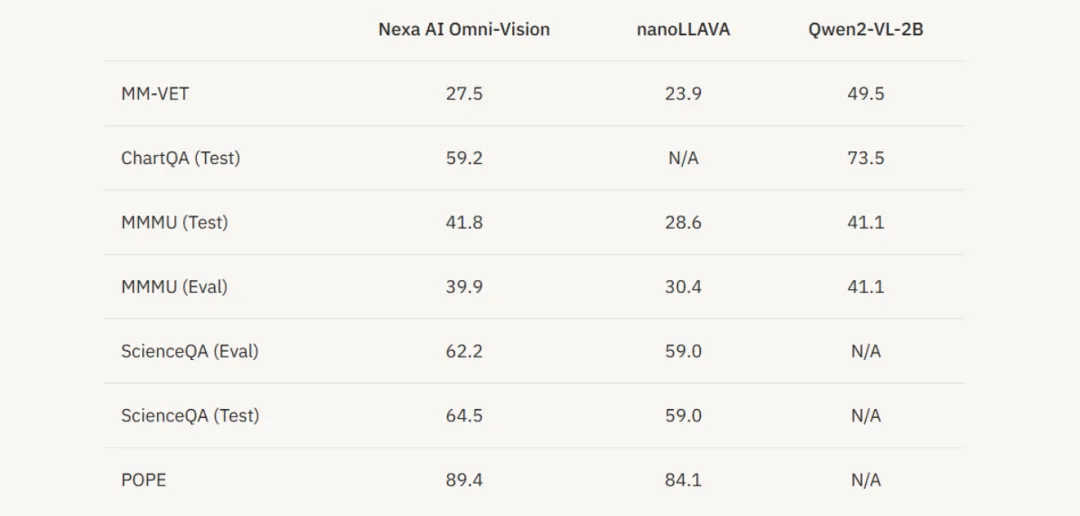
四、性能测试
在多个基准测试任务中,OmniVision 相比 nanoLLAVA 和 Qwen2 – VL – 2B 有明显优势。对比 nanoLLAVA,OmniVision 在多项任务中准确率更高。相较于 Qwen2 – VL – 2B,OmniVision 虽规模小,但在资源利用和性能平衡上表现佳,在推理延迟和资源占用方面更优,能在边缘设备低资源消耗下高效运行。同时,OmniVision 在视觉问答、图像描述、文本 – 图像匹配等准确性评估中表现良好。
五、应用场景
1. 智能安防监控
在安防领域,OmniVision – 968M可应用于监控摄像头系统。它能够实时分析监控画面中的图像信息,如人员行为、物体特征等,同时结合相关的文本信息,如安全规则、警报设置等。当检测到异常行为或符合特定警报条件的情况时,模型能够迅速发出警报,并提供详细的分析结果,帮助安保人员及时做出准确的反应,有效提升安防监控的效率和准确性。
2. 智能家居交互
对于智能家居系统,该模型可以集成到智能设备中,实现更加智能和便捷的家居交互。例如,通过摄像头识别用户的手势、表情等视觉信息,结合用户的语音指令或手机输入的文本信息,模型能够理解用户的意图,从而控制灯光的开关、调节家电的运行状态、调整室内温度等。这种多模态的交互方式,使得智能家居系统更加人性化、智能化,为用户提供更加舒适和便捷的生活体验。
3. 智能交通辅助
在交通领域,OmniVision – 968M可用于车辆的智能辅助系统。它可以分析车载摄像头拍摄的道路图像,识别交通标志、车道线、其他车辆和行人等元素,同时结合交通规则、导航信息等文本数据。在自动驾驶场景中,模型能够为车辆的决策系统提供重要的支持,帮助车辆做出合理的行驶决策,如加速、减速、转弯等,提高自动驾驶的安全性和可靠性。在驾驶员辅助系统中,模型也能实时提醒驾驶员注意道路安全状况,避免潜在的危险。
4. 移动设备智能应用
智能手机和平板电脑等移动设备是边缘设备的重要组成部分。OmniVision – 968M可以为移动设备上的各种应用赋能,如增强现实(AR)应用。在AR游戏中,模型能够实时处理摄像头捕捉的现实场景图像,结合游戏中的文本任务和指令,为玩家提供更加丰富和沉浸式的游戏体验。在图像编辑应用中,模型可以根据用户输入的文本描述,自动对图片进行相应的编辑操作,如调整色彩、添加特效等,提高图像编辑的效率和创意性。
六、结语
OmniVision – 968M模型作为多模态智能领域的创新成果,凭借其独特的技术原理、出色的功能特点和广泛的应用场景,为边缘设备的智能化发展带来了新的活力和机遇。它在解决边缘设备资源受限问题的同时,提供了高效、准确的视觉和文本处理能力,有望推动智能安防、智能家居、智能交通等多个领域的进一步发展。随着技术的不断进步和应用的深入探索,我们期待OmniVision – 968M在未来能够发挥更大的作用,为人们创造更加智能、便捷的生活和工作环境。














暂无评论内容