
.01
概述近年来,随着人工智能技术的快速进步,视觉语言模型(VLM)开始在多模态任务中崭露头角。然而,相较于文字生成领域的巨头如GPT-o1,这些模型在处理复杂视觉问答任务时表现得力不从心。它们通常缺乏系统的推理能力,无法有效组织信息,导致对图片和文字的组合理解存在明显局限。针对这一痛点,由北京大学、清华大学、鹏城实验室、阿里巴巴达摩院和美国李海大学联合研究团队推出了一款全新的视觉语言模型——LLaVA-o1。这一模型以类似GPT-o1的推理能力为目标,旨在通过系统性、多阶段的推理方法,填补当前视觉语言模型在深度认知任务上的空白。
.02
LLaVA-o1:视觉语言推理的全新突破传统视觉语言模型在面对复杂问题时,往往“一步到位”地生成回答,缺乏逐步推导的能力。这种方法容易导致逻辑漏洞,进而影响结果的准确性。而LLaVA-o1则通过多阶段推理结构,为多模态任务引入了更严谨的逻辑处理。LLaVA-o1的四阶段推理结构LLaVA-o1的核心创新在于其引入的四阶段推理过程,包括:
-
- 摘要(Summary):提取图像和文本的核心信息。
- 描述(Caption):生成更详细的图像文字描述,提供上下文支持。
- 推理(Reasoning):基于摘要和描述,分步进行逻辑推导。
- 结论(Conclusion):总结并生成最终的回答。
这种严谨的推理流程使模型在面对复杂问题时能够保持逻辑连贯性,大幅减少回答中的错误和不一致现象。
.03
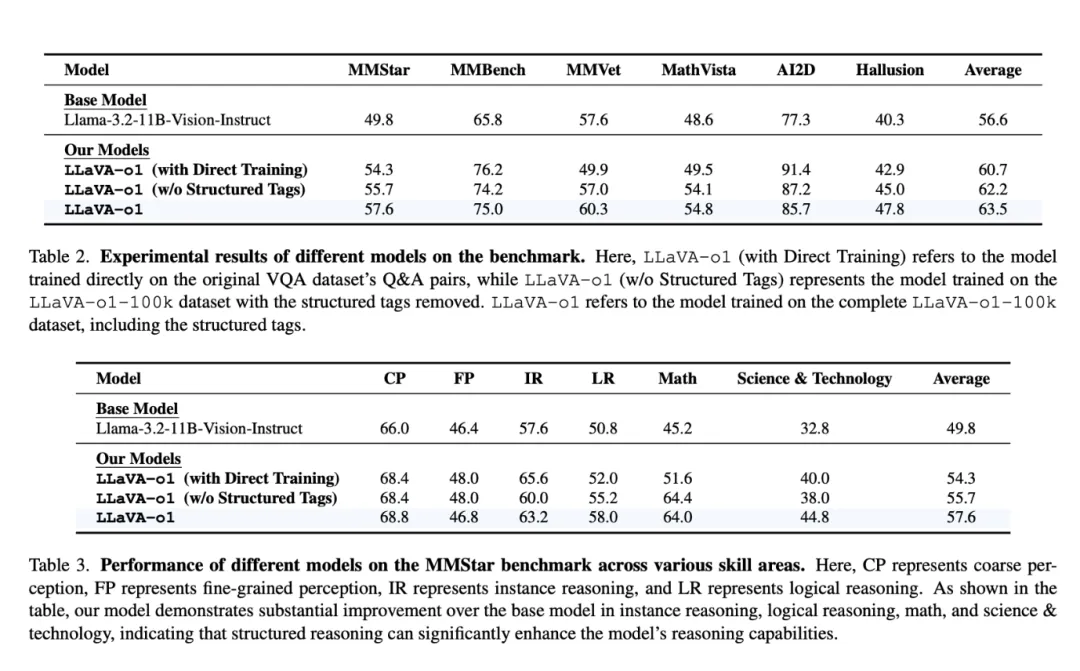
技术亮点:为什么LLaVA-o1更强?1. 推理中的“舞台级束搜索”LLaVA-o1采用了一种名为**舞台级束搜索(stage-level beam search)**的推理技术。在每个推理阶段,模型会生成多个备选答案,然后逐步筛选出最佳答案。这一过程类似于“层层过滤”,确保最终结论的逻辑性和准确性,显著优于传统的最佳-N方法或句子级束搜索方法。2. 高效的数据利用LLaVA-o1的训练数据集LLaVA-o1-100k,基于视觉问答(VQA)数据和GPT-4o生成的结构化推理注解。这一策略通过仅10万条样本,帮助模型实现了多阶段推理能力,展现了卓越的效率与可扩展性。3. 性能超越多种竞品与多种主流模型对比,LLaVA-o1的表现尤为亮眼:
-
- 相较于基础模型Llama-3.2-Vision-Instruct:多模态推理能力提升了8.9%。
- 超越闭源模型:如Gemini-1.5-pro、GPT-4o-mini和更大参数的Llama-3.2-90B-Vision-Instruct。
LLaVA-o1证明,在资源有限的情况下,通过高效的数据利用和创新的推理结构,完全可以实现媲美甚至超越更大规模模型的表现。
.04
解决多模态推理的关键难题传统视觉语言模型的缺陷
-
- 缺乏逻辑性:生成的答案通常过于直接,忽略了推理过程。
- 多模态理解不足:在同时处理图像和文字时容易信息断裂。
LLaVA-o1的突破性方案
-
- 多阶段推理:通过逐步推导,确保逻辑的连贯性。
- 舞台级束搜索:以更高的质量筛选答案,减少错误。
- 高效训练方法:仅依赖小规模训练数据,便可取得大幅度性能提升。
.05
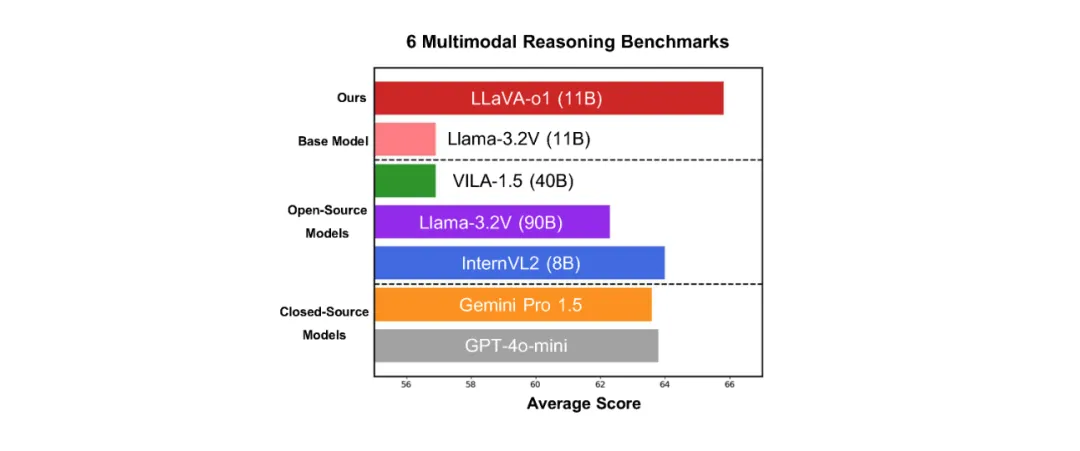
从实验结果看LLaVA-o1的实力在多个多模态任务基准测试中,LLaVA-o1展现了全面领先的表现:
-
- MMStar、MMBench和MMVet:在多模态任务的理解与推理上优于所有同类模型。
- MathVista和AI2D:在数学和科学视觉问题上表现尤为突出,显示其在复杂逻辑任务中的能力。
- HallusionBench:减少回答中的逻辑矛盾,可靠性显著提升。
实验数据显示,LLaVA-o1相较基础模型的性能平均提升超过6.9%。尤其在科学、技术等需要深度推理的领域,这一模型的优势尤为明显。
.06
LLaVA-o1的实际应用场景1. 科学研究分析实验数据:通过图像与文字的结合,辅助科研人员从实验结果中提取关键信息并进行逻辑推导。2. 医学领域医学影像分析:结合患者病史(文本)与医学影像(图片),提供系统性的诊断意见。3. 教育与学习互动教学:通过对复杂问题分步解答,为学生提供更加清晰的学习路径。4. 工业制造质量检测与分析:利用视觉语言结合,分析生产线上的图像数据并生成报告。
.07
结语LLaVA-o1不仅是一项技术的突破,更是多模态人工智能的一次范式转变。它展示了通过系统性推理和创新推导技术,如何弥合视觉与语言之间的差距。这一模型的问世,不仅为学术界和工业界提供了更强大的工具,也为未来的AI发展指出了新方向。对于视觉语言模型来说,LLaVA-o1的四阶段推理结构和高效训练策略设定了新的行业标准。它以“更少的资源”实现了“更大的突破”,充分证明了系统化方法的重要性。














暂无评论内容