DeepSeek放大招!DeepSeek-R1-Lite-Preview 震撼登场!推理能力超强,没有黑盒,实时展示推理思考过程,直接叫板OpenAI的o1-preview!
直接看性能
DeepSeek-R1-Lite 预览版模型在美国数学竞赛(AMC)中难度等级最高的 AIME 以及全球顶级编程竞赛(codeforces)等权威评测中,大幅超越了 GPT4o,甚至o1-preview 等知名模型
在六个不同基准测试(AIME 2024、MATH、GPQA Diamond、Codeforces、LiveCodeBench、ZebraLogic)中的表现
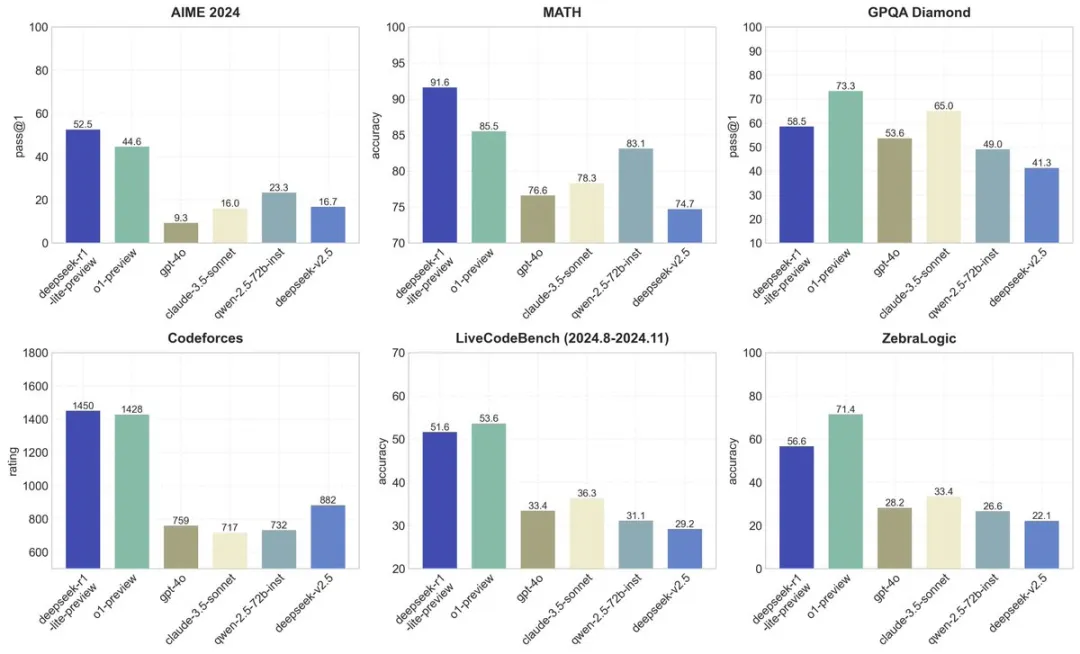
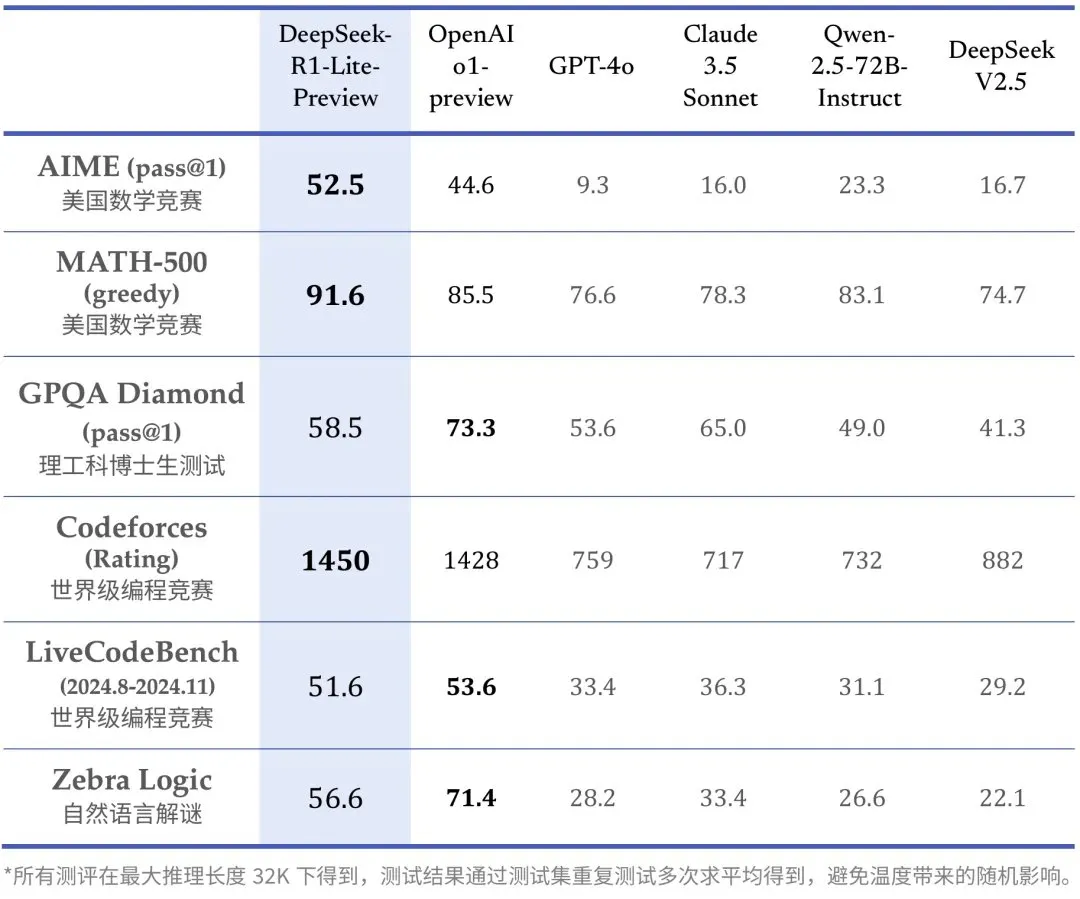
AIME 2024 :pass@1,模型第一次尝试就给出正确答案的百分比
deepseeker-r1-lite-preview 的表现最佳,达到 52.5%。o1-preview 紧随其后,为 44.6%
MATH :accuracy,模型在数学推理题上的正确率
deepseeker-r1-lite-preview 依然领先,正确率为 91.6%。o1-preview 紧随其后(85.5%),与其他模型拉开较大差距
GPQA Diamond:pass@1,模型在高难度问题上的首答正确率
o1-preview 领先,达到 73.3%,deepseeker-r1-lite-preview 紧随其后,为 58.5%
Codeforces:rating,模型在编程挑战赛中的分数
deepseeker-r1-lite-preview 领先,分数为1450 , o1得分1428
LiveCodeBench:accuracy,编程任务的正确率(2024年8月至11月)
o1-preview 小幅领先,正确率为 53.6%。deepseeker-r1-lite-preview 紧随其后,为 51.6%
ZebraLogic :accuracy,评估逻辑推理任务的正确率
o1-preview 占据第一,为 71.4%,deepseeker-r1-lite-preview 紧随其后,为 56.6%
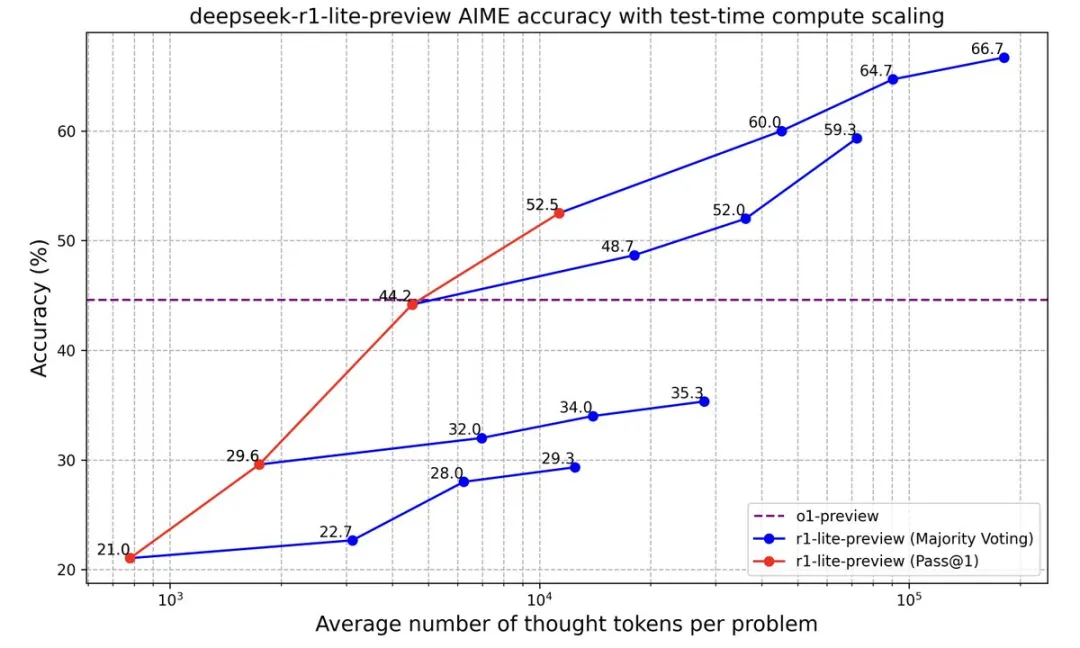
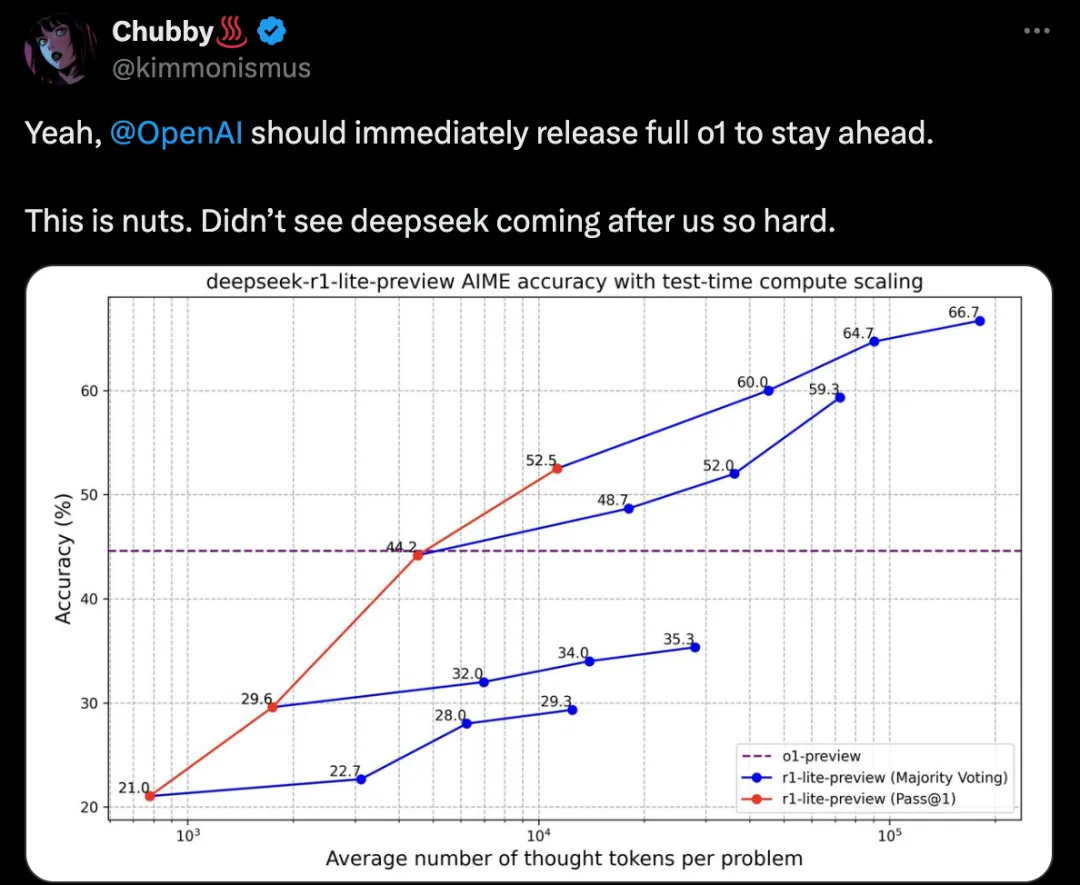
DeepSeek-R1-Lite-Preview推理缩放
更长的推理,更好的性能。随着思维长度的增加,DeepSeek-R1-Lite-Preview 在 AIME 上的得分稳步提高,这与OpenAI o1 提出推理缩放规律是一致的,由此也可以说明推理缩放具有巨大的潜力
DeepSeek-R1-Lite-Preview实测:
实时透明的思维过程! 让你清清楚楚地看到AI的思考过程,不再是黑盒!
我测试了几个经典问题:
9.11和9.8哪个大?
9.12和9.9哪个大?
单词 “strawberry”(草莓)有几个r?
单词’blueberrycherryberrycarbonpherry’?有几个r?
回答全都是一次性正确,并且实时的展示出了思考的过程
令我印象非常深刻,如果我没记错,这是我第一次在大模型上测试这些经典问题全部一次性答对,大家可以自己去试试










开源模型和API即将推出! DeepSeek-R1-Lite 目前仍处于迭代开发阶段,仅支持网页使用,暂不支持 API 调用。DeepSeek-R1-Lite 所使用的也是一个较小的基座模型,无法完全释放长思维链的潜力。正式版 DeepSeek-R1 模型将完全开源,公开技术报告,部署API
各路网友都在向OpenAI喊话,赶紧放出o1完整版,deepseek太强了,超出了想象















暂无评论内容