
在具身人工智能(Embodied AI)领域Visuomotor控制任务是一个关键且棘手的问题。硬件设置会严重影响机器人策略的性能。一个典型的例子来自不可移动的摄像头问题,设想一个经过仔细校准的视觉传感器,精心定位来实现无缝的现实世界部署,却被实验室伙伴打扰。虽然先前的工作试图解决视觉场景变化的挑战,但这些研究主要集中在解决一个方面,无法同时处理多种视觉泛化类型。同时,将各种归纳偏见纳入训练过程也并非易事。
目前的Sim2Real技术主要依赖于人为定义的低维状态数据。获取这些精确的低维状态信息通常需要复杂的系统辨识、设备校准及附加的算法模块,并且往往依赖于大量专家级知识,进行特定关节的域随机化以适应真实环境的部署。因此,这种方法通常限制了机器人在特定工作空间和场景设置中的操作,缺乏泛化能力,长期以来未能有效提升机器人的操作效率和实用性。
基于视觉的Sim2Real提供了一种创新的解决方案。与低维状态信息相比,视觉输入提供了更为丰富的反馈,使得机器人能够通过图像感知自动提取所需的状态信息进行决策。它能够不依赖于专家预定义的状态维度,也不受各关节状态信息的限制,而是可以利用视觉信息来纠正关节状态的误差,减少对动力学过程的依赖。
然而目前的方法大多都会通过构建Digit Twin来实现。Digit Twin的构建不仅需要人工花费大量精力构建,同时训得的policy也无法具备泛化能力。

在Sim2real的过程中需要克服视觉纹理和相机视角两大难点。Maniwhere通过使用多视角表征学习来融合不同视角下的图像信息。在每个时间步,Maniwhere会记录一固定视角和一随机视角的图像,先通过使用InfoNCE,将固定视角的图像与移动视角的图像进行Moco-v3-based对比学习损失的作用。在此基础上,Maniwhere也额外使用了在前层feature maps之间的feature alignment损失赋予所学策略捕捉相似的语义信息和correspondence的能力。
在网络结构方面,Maniwhere插入了STN模块用于进一步提升网络对空间信息感知的能力。在使用STN也将原始的仿射变换更新成了透视变换,以匹配三维空间的感知能力。
对于视觉纹理的泛化,Maniwhere使用课程学习的方式,增加数据增强的强度以及模拟环境各物理关节的动力学随机化过程。关于数据增强,该算法也使用了基于频域的增强来强化对于纹理和光照的影响。在强化学习的框架下,因大量引入额外噪声很容易造成训练的不稳定甚至发散,故Maniwhere通过使用稳定Q值学习的loss,使得在使用数据增强和域随机化时,依旧能够保持Q值估计的低方差,维持整体训练的稳定。
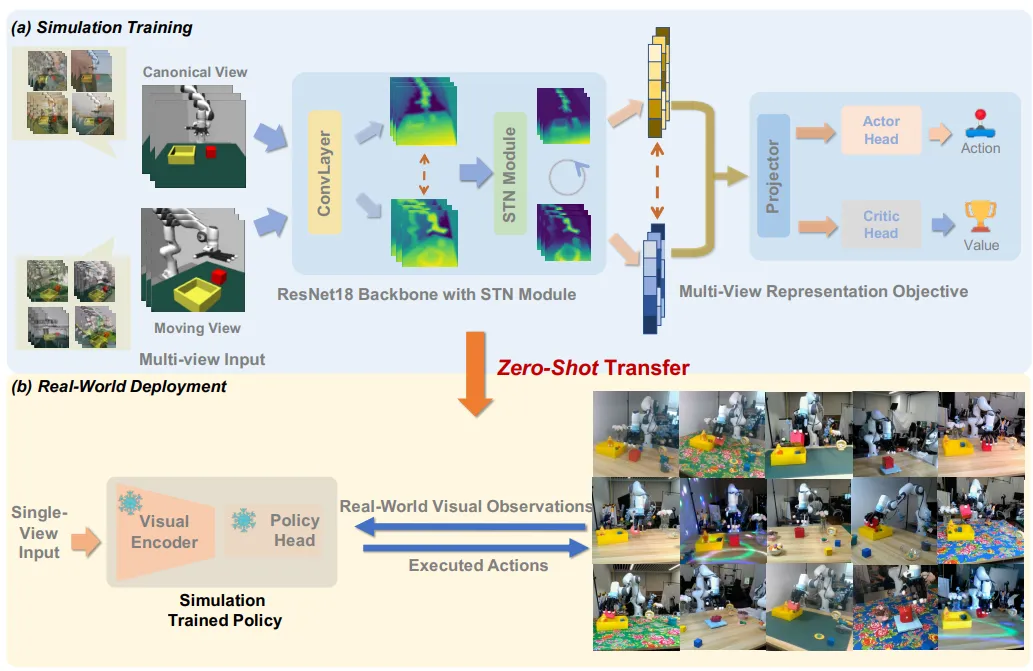
▲图1|Maniwhere算法框架

■3.1 视角泛化评估
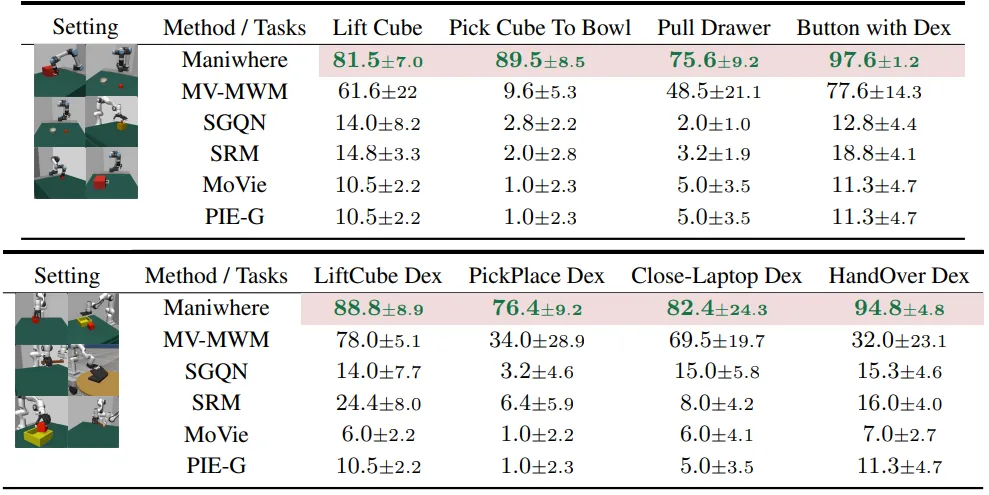
Maniwhere在8个manipulation task上与多个基线模型进行了对比,Maniwhere在全部8个task上都取得了最佳的表现。比之前的多视角训练方法,单视角adaptation,以及单视角泛化算法都具有明显的优势。
▲图2|视角泛化效果对比
■3.2 视觉纹理泛化能力评估

▲图3|视觉纹理泛化效果对比
在视角泛化的基础上,Maniwhere也与比较了视觉纹理泛化的能力。可以从图中看到在加入了纹理的变化后,之前的算法会存在较大的性能差异,而Maniwhere在8个任务上依旧可以很好的维持很好的表现。
另外在不同的embodiment上,Maniwhere也可以凭借其对于correspondence和不同视角下语义信息的捕捉拥有较强的泛化能力。
■3.3 轨迹可视化

▲图4|不同视角轨迹表征可视化
另外,本文也对视觉表征进行了可视化。我们将沿同一执行轨迹从不同视角渲染的图像特征图可视化,然后将 t-SNE 应用于特征图的映射。如上图所示,Maniwhere 能够将不同视点的图像映射到相似区域,并在整个执行轨迹中保持一致。
■3.4 真机实验
在模拟器中训练完成后,Maniwhere可以zero-shot部署到真机中。在实验中,共设计了3个不同的实验平台,包含多种不同类型的操作任务。
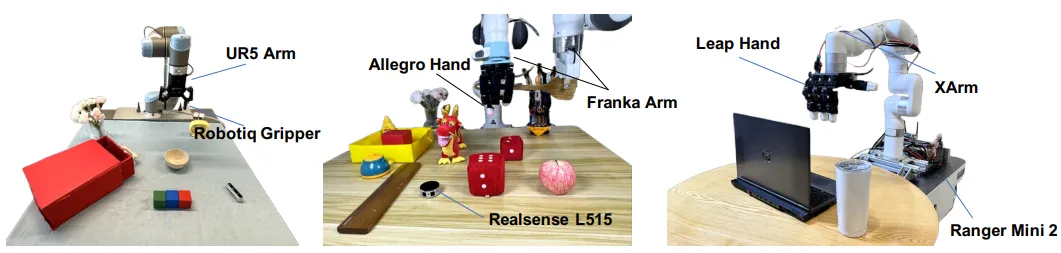
在进行测试时,场景的相机视角和纹理都会发生变化。Maniwhere在不同类型的机器人和任务上也都展现了良好的泛化能力和表现。也和仿真环境一样,均优于baseline算法。
■3.5 消融实验
通过消融实验,本文验证了在没有multi-view损失函数,STN以及其他多视角表征学习方法下的机器人性能。可以看到,每个模块对于Maniwhere的性能都有着重要作用,展现了该方法的优势。
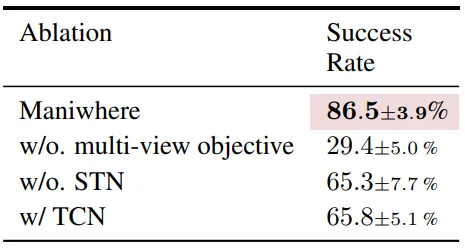
▲图5|消融实验结果

在本篇论文中,我们介绍了Maniwhere——一个用于强化学习的视觉泛化框架。Maniwhere通过多视角表示学习获取不同视角下图像的一致性信息,并采用基于课程学习的域随机化和增强方法来训练具有泛化能力的视觉强化学习策略。实验表明,Maniwhere能够适应多样的视觉场景,并实现zero-shot sim2real transfer。未来,我们计划提升Maniwhere在更广泛的相机范围和更多样化的视觉场景中的泛化能力。除了视觉泛化外,我们还打算融入空间泛化方法来处理更复杂的物体空间关系,最终目标是开发一个鲁棒的sim2real框架。














暂无评论内容