
这两天,有一个开源的多模态模型Omnivision在HuggingFace上比较火,这个模型参数量只有968M,也是目前我所看到的最小的多模态模型。Omnivision-968M是由创业公司Nexa AI所发布,这家公司的使命就是开发先进的端侧AI模型,端侧AI模型不需要部署在云端,而是可以直接跑在本地设备上,不仅成本低,而且也可以保护用户的隐私。这次发布的Omnivision-968M可以在 M4 Pro MacBook 上运行,为一张 1046×1568 的图像生成描述仅需不到 2 秒处理时间,而且只占用 988 MB 内存。
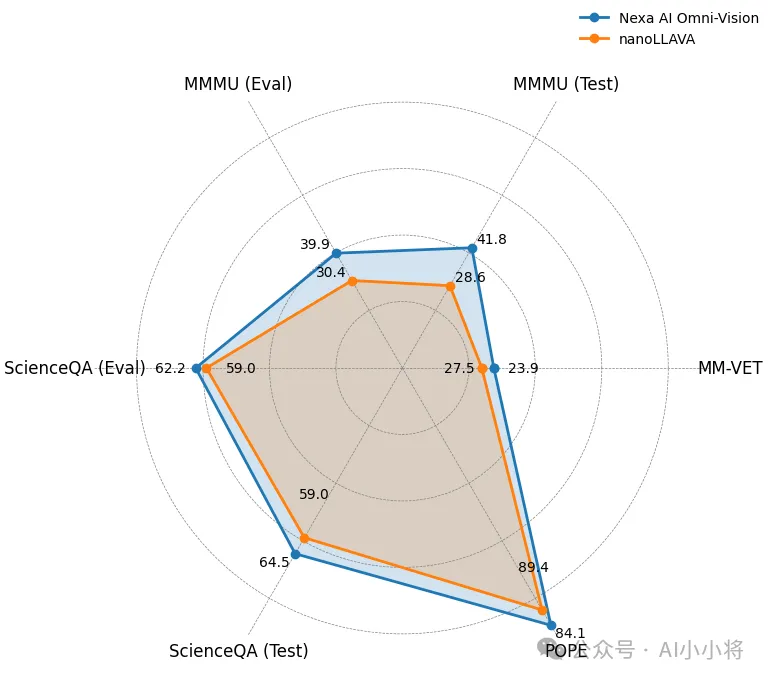
而且,在一些多模态评测集上,Omnivision 的表现均优于此前全球最小的视觉语言模型nanoLLAVA(1B参数):
部分指标也接近参数量更大的Qwen2-VL-2B:

下面Omnivision-968M的一些demo:
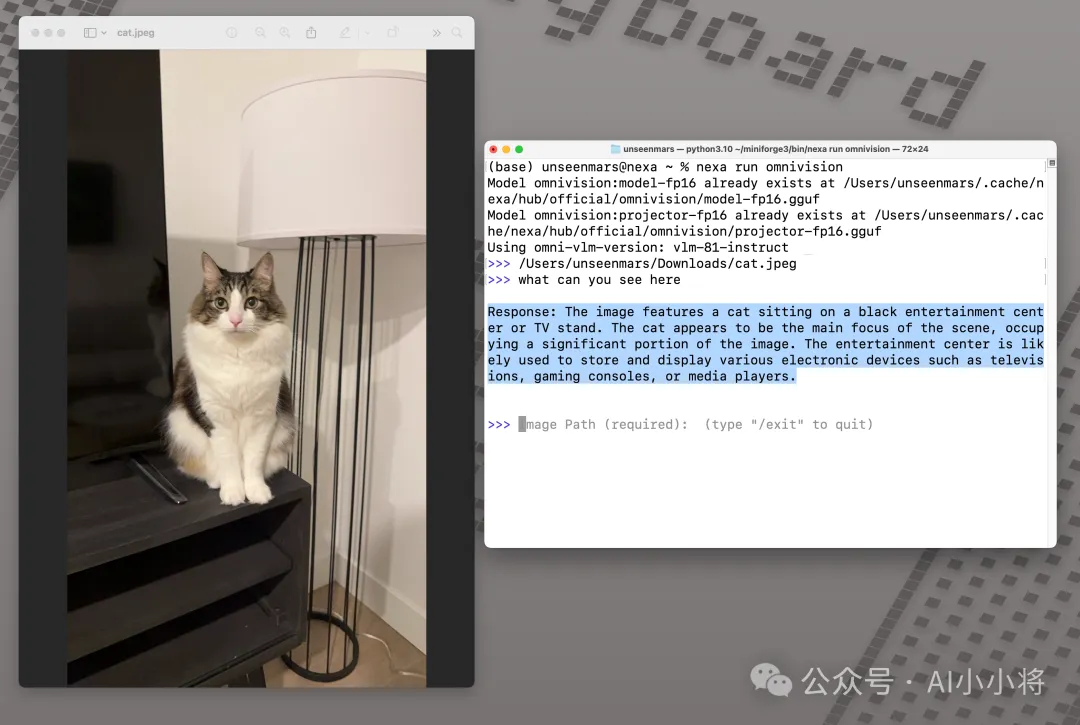
给图片生成描述:
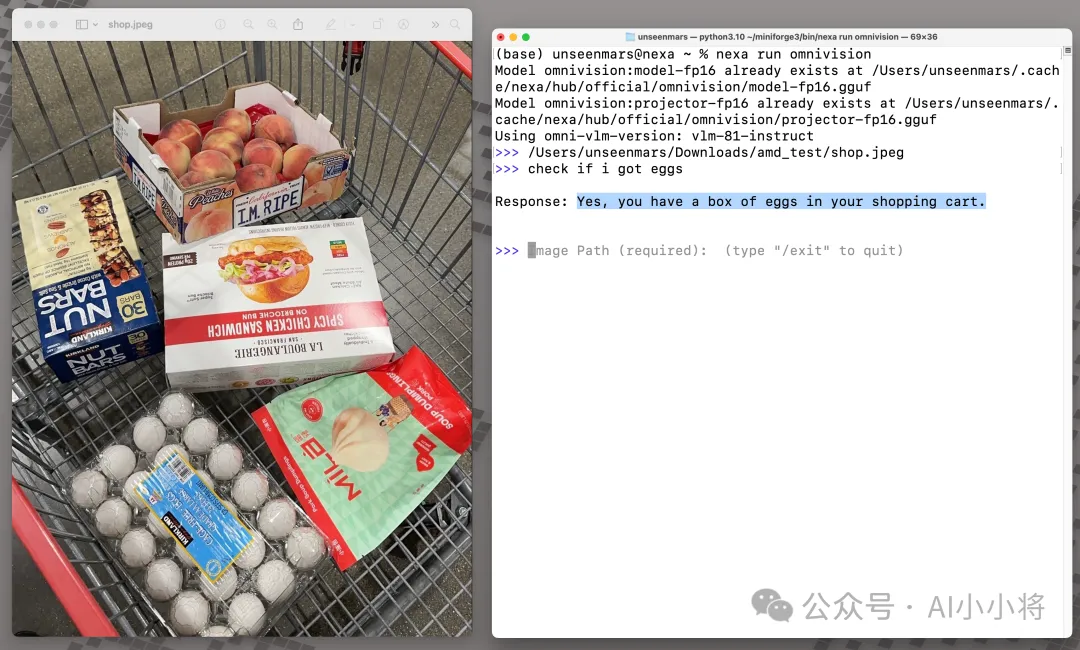
找到图片中的特定物体:
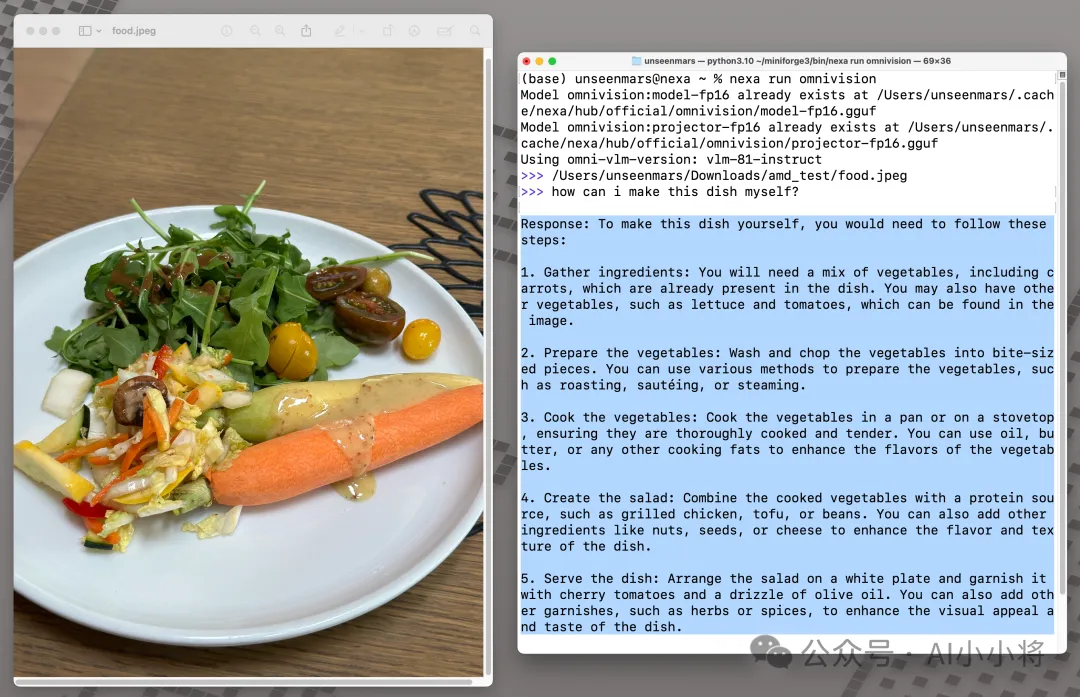
分析食物图像并生成食谱:
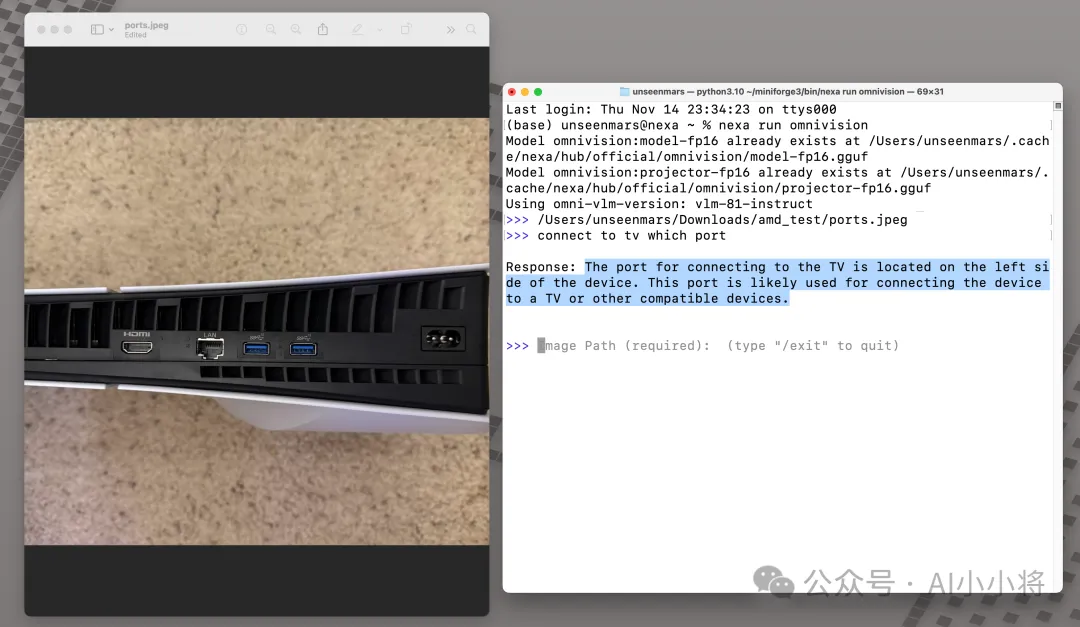
识别物体位置:
为什么Omnivision-968M可以这么小?这里我们可以看一下Omnivision-968M的模型架构,它是基于LLava架构,主要包括三个组件:
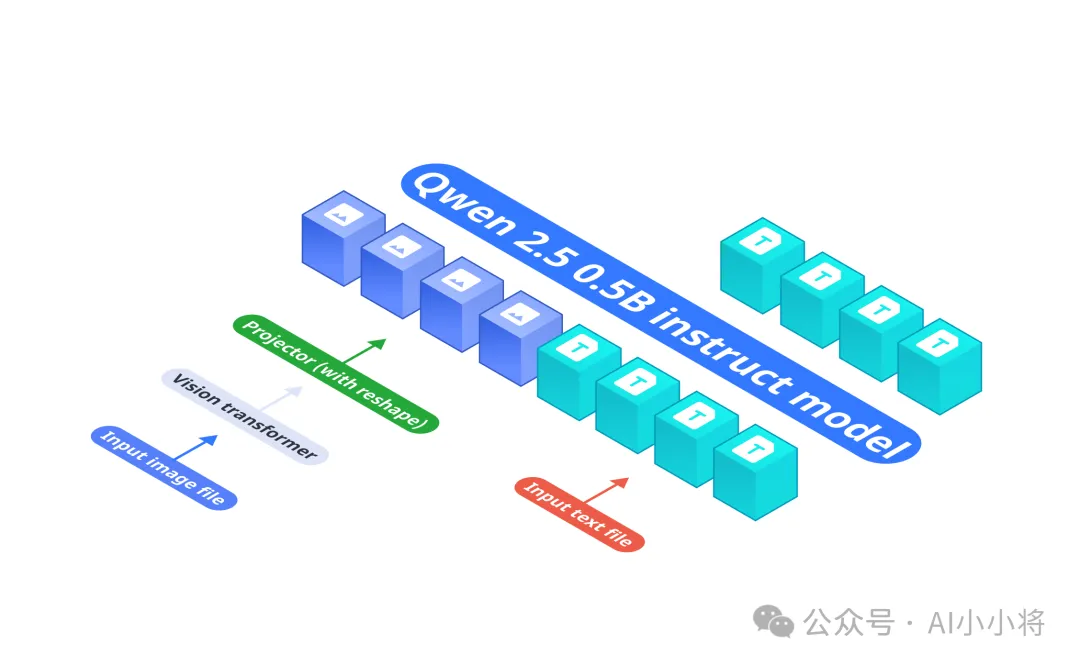
基础LLM:Qwen2.5-0.5B-Instruct。
视觉编码器:SigLIP-400M,处理384×384分辨率图像,patch size是14×14。
投影层:采用MLP将视觉编码器的特征与语言模型的embedding进行对齐。与原始的Llava架构相比,这里的投射层将将图像tokens从729减少到81(减少9倍),降低了延迟和计算成本。
此外,Omnivision的训练也采用三阶段的策略:预训练 -> SFT -> DPO。预训练阶段使用图像-文本对建立基本的视觉-语言对齐,在这个阶段,只有投影层的参数是可训练的。SFT阶段使用基于图像的问答数据集来增强模型的上下文理解,这个阶段涉及在包含图像的结构化聊天记录上进行训练,以便模型生成更符合上下文的响应。最后的DPO阶段,先使用基础模型对图像生成输出,然后采用Qwen2-VL-72B-Instruct作为教师模型对输出结果修正,这里只修正输出的准确性,而尽量持与原始响应的高度语义相似性。原始输出和修正结果就构成了DPO训练的pair对。
目前Omnivision可以直接在HuggingFace上下载:
https://huggingface.co/NexaAIDev/omnivision-968M
如果要使用,要首先安装Nexa-SDK,它是一个开源的、本地设备上的推理框架。安装后就可以在终端直接运行:
nexa run omnivision














暂无评论内容