本文目录
moonshine模型介绍
moonshine性能介绍
实战篇:下载moonshine模型权重&&步骤代码进行语音识别
使用 onnxruntime 包来运行 Moonshine 模型,不依赖torch
使用huggingface框架加载moonshine模型进行asr语音识别
效果篇: moonshine-base模型 VS whisper-base模型ASR效果对比
案例1: 短文本语音识别-2种模型效果展示
案例2: TED演讲视频-2种模型效果展示
参考链接
moonshine模型介绍
Moonshine 是由 Useful Sensors公司推出开源的语音到文本(speech-to-text, STT)转换模型,旨在为资源受限设备提供快速而准确的自动语音识别(ASR)服务。Moonshine 基于先进的编码器-解码器架构,采用了Transformer模型。其编码器部分负责处理输入的语音信号,而解码器部分则生成文本输出。目前在gitihub社区点赞量达2k!

Moonshine模型具有以下特点:
- 开源tiny版本,参数量:27 M, 只支持英文语言; 开源base版本,参数量:61 M, 只支持英文语言;
- 更快的处理速度,Moonshine 的处理速度比 Whisper 快 1.7 倍。对于 10 秒的短音频片段,处理速度可达 Whisper 的五倍。
- 基于20w小时的语音样本训练而来。
moonshine性能介绍
Moonshine 在多个维度上超越了现有的语音识别解决方案,特别是在处理速度和准确度方面。据官方报告,Moonshine 的处理速度「比 OpenAI 的 Whisper 快五倍」,并且在词错误率方面也表现得更好,如下图所示。
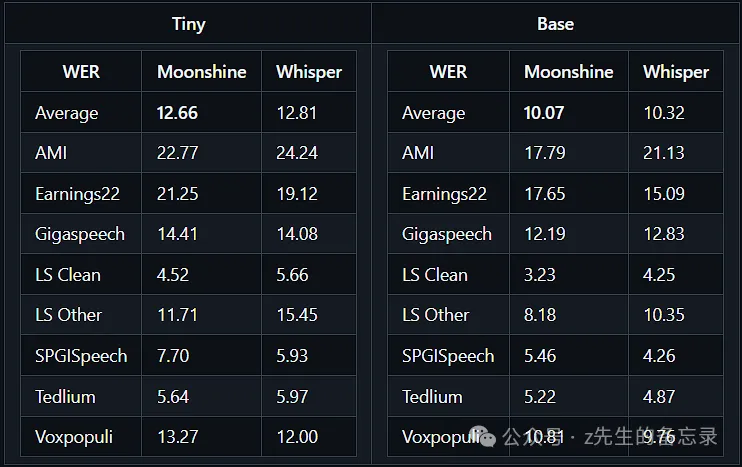
这种显著的优势使得 Moonshine 成为资源受限环境下语音识别的理想选择。
下面我将给大家实操部署moonshine-base模型和whisper-base模型,准备几个案例来实际展示具体的语音识别效果,仅供参考~
实战篇:下载moonshine模型权重&&步骤代码进行语音识别
使用 onnxruntime 包来运行 Moonshine 模型,不依赖torch
from IPython.display import clear_output
!pip install moonshine
!git clone https://github.com/usefulsensors/moonshine.git
!pip install silero_vad onnxruntime sounddevice tokenizers einops
!pip install onnxruntime-gpu
下载模型权重
!huggingface-cli download UsefulSensors/moonshine –local-dir . –local-dir-use-symlinks False
clear_output()
加载moonshine模型onnx格式权重进行推理
model = MoonshineOnnxModel(models_dir= “./onnx/base”)
def moonshine_infer(wav_file):
with wave.open(wav_file) as f:
params = f.getparams()
assert (
params.nchannels == 1
and params.framerate == 16_000
and params.sampwidth == 2
), f”wave file should have 1 channel, 16KHz, and int16″
audio = f.readframes(params.nframes)
audio = np.frombuffer(audio, np.int16) / 32768.0
audio = audio.astype(np.float32)[None, …]
tokens = model.generate(audio)
tokenizer = tokenizers.Tokenizer.from_file(“./moonshine/assets/tokenizer.json”)
text = tokenizer.decode_batch(tokens)
return text
进行模型推理
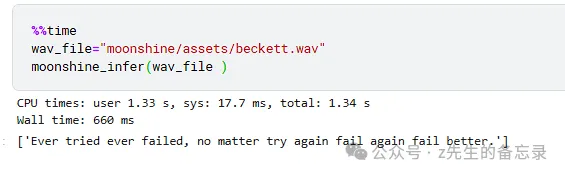
使用huggingface框架加载moonshine模型进行asr语音识别
%%time
%cd /kaggle/working/moonshine
from IPython.display import clear_output
from transformers import AutoModelForSpeechSeq2Seq, AutoConfig, PreTrainedTokenizerFast
import torchaudio
import torch
import sys
device = “cuda:0” if torch.cuda.is_available() else “cpu”
# ‘usefulsensors/moonshine-base’ for the base model
moonshine = AutoModelForSpeechSeq2Seq.from_pretrained(‘usefulsensors/moonshine-base’, trust_remote_code=True)
tokenizer = PreTrainedTokenizerFast.from_pretrained(‘usefulsensors/moonshine-base’)
audio, sr = torchaudio.load(“moonshine/assets/beckett.wav”)
if sr != 16000:
audio = torchaudio.functional.resample(audio, sr, 16000)
tokens = moonshine(audio)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
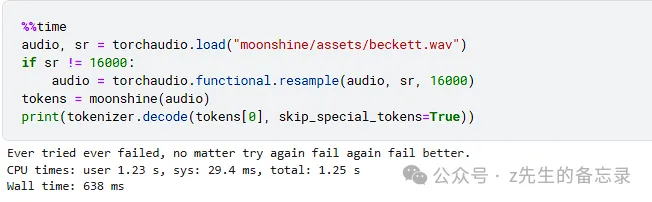
下面我将利用moonshine-base版本和whisper-base版本的模型进行语音识别效果对比,看具体实际案例情况下,模型的具体表现情况,随便找的素材,经供参考~
效果篇: moonshine-base模型 VS whisper-base模型ASR效果对比
案例1: 短文本语音识别-2种模型效果展示
参考音频1效果展示:
参考音频1,z先生的备忘录,9秒
moonshine-base的ASR效果展示
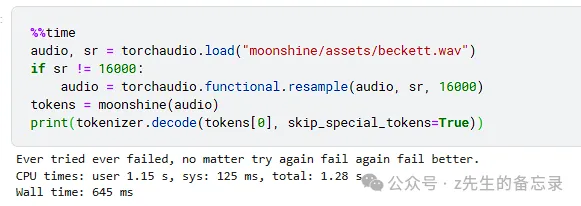
识别结果: Ever tried ever failed, no matter try again fail again fail better.
whisper-base的ASR效果展示
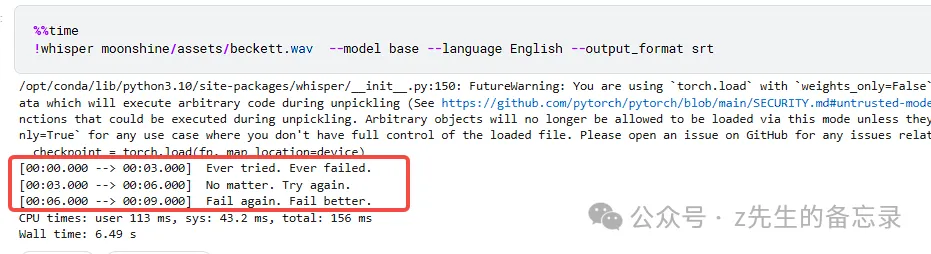
2种模型识别结果都非常正确,而moonshine-base速度很快,只用来不到0.6秒,即便算上模型加载的时间,也才1.2秒。
案例2: TED演讲视频-2种模型效果展示
随便找一份英语的演讲视频进行测试,我这个找到https://www.youtube.com/playlist?list=PLosaC3gb0kGDUYoRq-VioWOZ5Ke0UIoSE,截取前2分钟的视频转化为音频效果如下:
参考音频2,z先生的备忘录,2分钟
moonshine-base的ASR效果展示
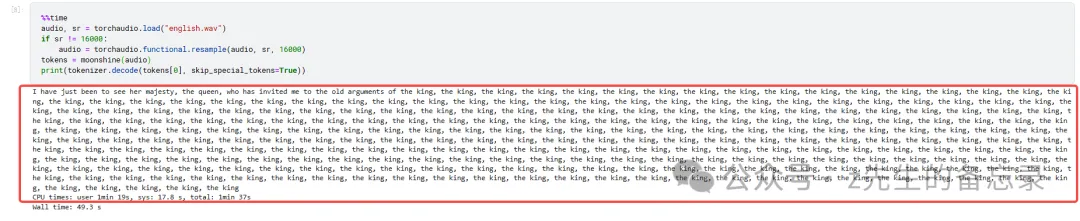
单次不支持长语音识别,采用分段识别,代码如下:
import librosa
import os
import moonshine
import soundfile as sf
# !mkdir temp
def benchmark(audio_pth):
# 读取音频文件
audio, sr = torchaudio.load(“english.wav”)
if sr != 16000:
audio = torchaudio.functional.resample(audio, sr, 16000)
# 分割音频文件成小段
chunk_duration = 10 # 每个片段的长度(秒)
chunk_size = int(chunk_duration * sr)
chunks = for i in range(0, audio.shape[1], chunk_size)]
# 转录音频
transcription = “”
for i, chunk in enumerate(chunks):
print(f”正在转录… ({i + 1}/{len(chunks)})”)
tokens = moonshine_model(chunk)
chunk_transcription = tokenizer.decode(tokens[0], skip_special_tokens=True)
if isinstance(chunk_transcription, list):
chunk_transcription = ‘ ‘.join(chunk_transcription)
transcription += chunk_transcription
return transcription
最后识别的结果如下:

whisper-base的ASR效果展示
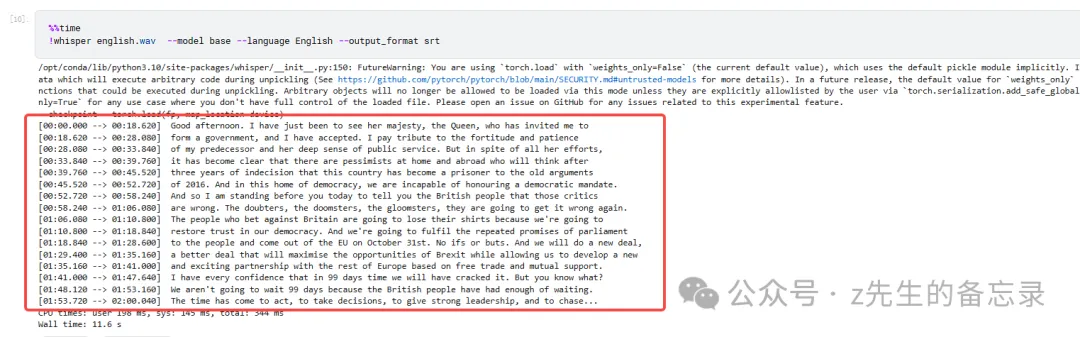
我感觉2个模型识别的效果相差不大,moonshine速度是比较快的,但是目前moonshine只支持英文。大家可以对比录音听听,看看谁识别的更准~














暂无评论内容